







import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset,DataLoader
import h5py
import glob
import os
import json
from tqdm import tqdm
import sys
import open3d as o3d
目录
写在前面,本人pointnet代码所在的目录结构

2022.12.3更新
训练S3DIS需要大内存,注意是内存,不是显存,因为要加载数据进去。
若自己没有设备,可用云平台,这个云平台是市面上便宜的了,自己也在这个平台下用,出了篇paper。
GPU云平台
2022.11.6更新
该pointnet网络,代码有些混乱,只能是参考。
经过后续复现许多经典的点云分割网络,代码皆以流程化(不是源码,按照我自己的话术敲写,比源码的可读性强很多)。
本人在这售卖DGCNN、PointNeXt、RandLA-Net、PointTransformer、Minkowski网络(打包价140元,单买35,可讲价),实现的代码可以反复使用(也可以在其他网络中使用),包你节省至少1个月弯路(这几个网络代码,我总共也复现了近30天,所以140元)。(有意可以联系qq: 1326855218,备注:CSDN)。
2022.7.6更新
- 关于S3DIS数据集的Train与Test问题,查看该链接:关于S3DIS问题
一、ShapeNet数据集简介
-
首先下载 shapenet 数据集:地址
-
下载完毕后,synsetoffset2category.txt 文件,表明了各点云类在哪个文件夹下
-
点云数据在 .txt文件中,部分内容如下:

-
shapenet有16个大类,每个大类有一些小类。共有16个大类,50个小类。
‘Earphone’: [16, 17, 18], ‘Motorbike’: [30, 31, 32, 33, 34, 35], ‘Rocket’: [41, 42, 43],
‘Car’: [8, 9, 10, 11], ‘Laptop’: [28, 29], ‘Cap’: [6, 7], ‘Skateboard’: [44, 45, 46],
‘Mug’: [36, 37], ‘Guitar’: [19, 20, 21], ‘Bag’: [4, 5], ‘Lamp’: [24, 25, 26, 27],
‘Table’: [47, 48, 49], ‘Airplane’: [0, 1, 2, 3], ‘Pistol’: [38, 39, 40],
‘Chair’: [12, 13, 14, 15], ‘Knife’: [22, 23]
定义ShapeNet_DataSet
class ShapeNetDataSet(Dataset):
def __init__(self, root="./data/ShapeNet", npoints=2500, split="train", class_choice=None, normal_use=False):
'''
root:str type, dataset root directory. default: "./data/ShapeNet"
npoint:int type, sampling number of point. default: 2500
split:str type, segmentation of dataset. eg.(train, val, test). default: "train"
class_choice:list type, select to keep class. default: None
normal_use:boolean type, normal(法线) information whether to use. default: False
'''
self.root = root # 数据集路径
self.npoints = npoints # 采样点数
self.normal_use = normal_use # 是否使用法线信息
self.category = {} # 类别所对应文件夹
# shapenet有16个大类,每个大类有一些部件,
# 例如飞机 'Airplane': [0, 1, 2, 3] 其中标签为0 1 2 3 的四个小类都属于飞机这个大类
self.seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],
'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],
'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],
'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
# 读取 类别所对应的文件夹信息,即该文件synsetoffset2category.txt
with open(self.root+"/synsetoffset2category.txt") as f:
for line in f.readlines():
cate,file = line.strip().split()
self.category[cate] = file
# print(self.category) # {'Airplane': '02691156', 'Bag': '02773838', 'Cap': '02954340', 'Car': '02958343', 'Chair': '03001627', 'Earphone': '03261776', 'Guitar': '03467517', 'Knife': '03624134', 'Lamp': '03636649', 'Laptop': '03642806', 'Motorbike': '03790512', 'Mug': '03797390', 'Pistol': '03948459', 'Rocket': '04099429', 'Skateboard': '04225987', 'Table': '04379243'}
# 将类别字符串与数字对应
self.category2id = {}
i = 0
for item in self.category:
self.category2id[item] = i
i = i + 1
# class_choice进行类别选择
if class_choice: # class_choice 是 list类型
for item in self.category:
if item not in class_choice: # 若 类别 不在class_choice中,则删除
self.category.pop(item)
# 存储类别对应的点云数据文件
self.datapath = [] # 存储形式:[ (类别, 数据路径), (类别, 数据路径), ... ]
# 遍历点云文件,进行存储
for item in self.category:
filesName = [f[:-4] for f in os.listdir(self.root+"/"+self.category[item])] # 把该类别文件夹下的所有文件遍历出来,之后对其进行判断(属于训练集、验证集、测试集、)
# 抓取部分数据(训练集、验证集、测试集)
if split=="train":
with open(self.root+"/"+"train_test_split"+"/"+"shuffled_train_file_list.json") as f:
filename = [f.split("/")[-1] for f in json.load(f)]
for file in filesName:
if file in filename: # 若该类别文件夹中的数据在训练集中,则存储
self.datapath.append((item, self.root+"/"+self.category[item]+"/"+file+".txt"))
elif split=="val":
with open(self.root+"/"+"train_test_split"+"/"+"shuffled_val_file_list.json") as f:
filename = [f.split("/")[-1] for f in json.load(f)]
for file in filesName:
if file in filename: # 若该类别文件夹中的数据在验证集中,则存储
self.datapath.append((item, self.root+"/"+self.category[item]+"/"+file+".txt"))
elif split=="test":
with open(self.root+"/"+"train_test_split"+"/"+"shuffled_test_file_list.json") as f:
filename = [f.split("/")[-1] for f in json.load(f)]
for file in filesName:
if file in filename: # 若该类别文件夹中的数据在测试集中,则存储
self.datapath.append((item, self.root+"/"+self.category[item]+"/"+file+".txt"))
def __getitem__(self, index):
'''
:return: 点云数据, 大类别, 每个点的语义(大类别中的小类别)
'''
cls = self.datapath[index][0] # 类别字符串
cls_index = self.category2id[cls] # 类被字符串所对应的数字
path = self.datapath[index][1] # 点云数据存储的路径
data = np.loadtxt(path) # 点云数据
point_data = None
if self.normal_use: # 是否使用法线信息
point_data = data[:, 0:-1]
else:
point_data = data[:, 0:3]
seg = data[:, -1] # 语义信息
# 对数据进行重新采样
choice = np.random.choice(len(seg), self.npoints)
point_data = point_data[choice, :]
seg = seg[choice]
return point_data, cls_index, seg
def __len__(self):
return len(self.datapath)
- 测试一下
ShapeNetDataSet类是否定义成功
dataset = ShapeNetDataSet(normal_use=True)
dataset
输出:
<main.ShapeNetDataSet at 0x1449258b5e0>
dataset[1]
输出:
(array([[ 0.04032, -0.04601, -0.2194 , 0.8508 , 0.5099 , 0.1266 ],
[ 0.28303, -0.01156, 0.01564, 0.1708 , 0.8002 , 0.5749 ],
[ 0.28908, -0.02916, 0.0262 , 0.04791, 0.09224, 0.9946 ],
…,
[ 0.12313, -0.06889, -0.12327, 0.6052 , -0.3931 , -0.6923 ],
[-0.17983, -0.04519, -0.02602, -0.07472, -0.4551 , -0.8873 ],
[ 0.03092, -0.05983, 0.05344, 0.7298 , -0.669 , -0.1407 ]]),
0,
array([3., 0., 0., …, 3., 0., 1.]))
二、S3DIS数据集简介
-
S3DIS数据集下载:
-
txt格式文件介绍:
- 下载完毕后,有6个文件夹(Area_1、…、Area_6)
- 简介如下:
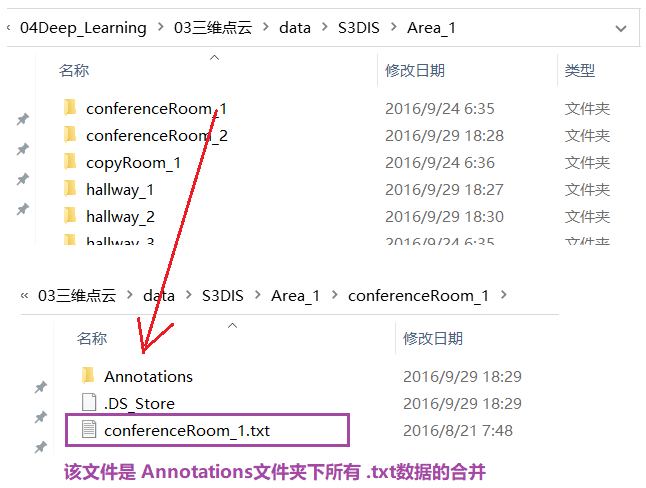
-
数据集中有几个问题:
- Stanford3dDataset_v1.2版本,Area_5\office_19\Annotations\ceiling_1.txt 第323474行
- Stanford3dDataset_v1.2_Aligned_Version版本,Area_5\hallway_6\Annotations\ceiling_1.txt 第180389行
- hdf5格式文件介绍:
- 有 0-23 编号 .h5文件(共24个文件)

- 有 0-23 编号 .h5文件(共24个文件)
- 一个 .h5 文件有
data键 和label键- 0-22编号文件:
data.shape = (1000, 4096, 9)、label.shape = (1000, 4096) - 23编号文件:
data.shape = (585, 4096, 9)、label.shape = (585, 4096) - data最后一维是9,表示:XYZRGBX’Y’Z’ (X’:所属房间中的点 归一化坐标)
- 一共加起来,共 23585 行数据,正好对应
room_filelist.txt文件中的行数 - 那么,
data[i, :, :]数据对应room_filelist.txt的一行数据,即:(画图展示)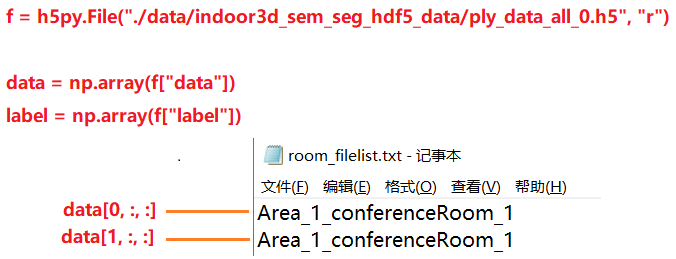
- 0-22编号文件:
注意
- 在
train时,使用S3DISDataSetTxt或S3DISDataSetH5类声明train_dataset,因为在训练时,使用一个room中的部分场景进行训练。 - 在
test时,使用S3DISWholeSceneDataSet类声明test_dataset,因为在测试时,使用一个room进行测试,不再进行分割场景。
DATA_PATH = './Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version' # 数据集所在目录
BASE_DIR = "./Pointnet_Pointnet2_pytorch-master/data_utils"
ROOT_DIR = os.path.dirname(BASE_DIR) # "./Pointnet_Pointnet2_pytorch-master"
classes = [i.strip() for i in open(BASE_DIR+"/meta/class_names.txt")] # ['ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door', 'table', 'chair', 'sofa', 'bookcase', 'board', 'clutter']
classes2label = {classes[i]:i for i in range(len(classes))} # {'ceiling': 0, 'floor': 1, 'wall': 2, 'beam': 3, 'column': 4, 'window': 5, 'door': 6, 'table': 7, 'chair': 8, 'sofa': 9, 'bookcase': 10, 'board': 11, 'clutter': 12}
classes2color = {'ceiling':[0,255,0],'floor':[0,0,255],'wall':[0,255,255],'beam':[255,255,0],
'column':[255,0,255],'window':[100,100,255],'door':[200,200,100],'table':[170,120,200],
'chair':[255,0,0],'sofa':[200,100,100],'bookcase':[10,200,100],'board':[200,200,200],'clutter':[50,50,50]}
easy_view_labels = [7,8,9,10,11,1] # 点云进行可视化时,容易观察到的类别
label2color = { classes2label[cls]:classes2color[cls] for cls in classes } # {0: [0, 255, 0],1: [0, 0, 255],2: [0, 255, 255],3: [255, 255, 0]4: [255, 0, 255],5: [100, 100, 255],6: [200, 200, 100],7: [170, 120, 200],8: [255, 0, 0],9: [200, 100, 100],10: [10, 200, 100],11: [200, 200, 200],12: [50, 50, 50]}
txt格式
- 在定义DataSet之前,需将S3DIS数据打上标签值,因为下载原始数据,只有 XYZRGB 值,没有 label 值
# 将原始数据打上label
def collect_point_label(anno_path, out_filename, file_format=".txt"):
'''
把原始数据集转换为 data_label 文件(每行:XYZRGBL,L:label)
anno_path:annotations的路径。例如:Area_1/office_2/Annotations/
out_filename:保存文件(data_label)的路径
file_format:保存文件的格式, 只有两种格式:.txt 或 .npy
return: None
github源代码中注释如下:
Note: the points are shifted before save, the most negative point is now at origin.
注意:这些点在保存之前被移动,现在最负的点在原点。
'''
points_list = []
anno_files = [anno_path+"/"+i for i in os.listdir(anno_path) if i.endswith(".txt")] # 把 Annotations 文件夹下,以.txt结尾的文件取出
for file in anno_files:
# print(file) # ./Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_1/conferenceRoom_1/Annotations/beam_1.txt
cls = os.path.basename(file).split("_")[0] # beam
if cls == "stairs": # 有些 Annotations 文件夹下,有 stairs 类别,例如:Area_1/hallway_8/Annotations
cls = "clutter"
points = np.loadtxt(file, encoding="utf8") # 加载点云数据(XYZRGB)
labels = np.ones([points.shape[0], 1])*classes2label[cls] # L:label
points_list.append(np.concatenate([points, labels], 1)) # np.concatenate((a1, a2, ...), axis)。axis:0 将a1与a2行连接;1 将a1与a2列连接
data_label = np.concatenate(points_list, 0) # 将 points_list 中的数据,全部进行 行连接
xyz_min = np.min(data_label[:,0:3], axis=0) # 为什么这样?在该方法定义处,有解释
data_label[:, 0:3] = data_label[:, 0:3] - xyz_min
# 保存data_label (PS:在这我个人比较喜欢使用 .txt格式保存,因为 .npy格式没有使用过)
if file_format==".txt":
with open(out_filename, "w") as f:
for i in data_label: # 遍历 data_label 每行
f.write("%f %f %f %d %d %d %d\n" % (i[0], i[1], i[2], i[3], i[4], i[5], i[6]))
elif file_format==".npy":
np.save(out_filename, data_label)
else:
print('ERROR!! Unknown file format: %s, please use .txt or .npy.' % (file_format) )
exit()
# 遍历 Annotations 文件夹下的 点云数据(txt格式), 然后调用 collect_point_label() 方法
anno_paths = []
with open(BASE_DIR+"/meta/anno_paths.txt") as f:
lines = f.readlines()
for line in lines:
l = line.strip()
anno_paths.append(l) # ['Area_1/conferenceRoom_1/Annotations']
anno_paths = [os.path.join(DATA_PATH, p) for p in anno_paths] # ['./Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version\\Area_1/conferenceRoom_1/Annotations']
output_folder = os.path.join(ROOT_DIR, 'data/s3dis/alter_s3dis_my') # 原始数据修改后,保存的文件夹。'./Pointnet_Pointnet2_pytorch-master\\data/s3dis/alter_s3dis_my'
if not os.path.exists(output_folder): # 若不存在 ./Pointnet_Pointnet2_pytorch-master\\data/stanford_indoor3d' 文件夹,则创建
os.mkdir(output_folder)
for anno_path in anno_paths:
'''
windows下,需要 .replace("\\", "/"),否则使用 anno_path.split("/") 后,会产生 ['.', 'Pointnet_Pointnet2_pytorch-master', 'data', 's3dis', 'Stanford3dDataset_v1.2_Aligned_Version\\Area_1', 'conferenceRoom_1', 'Annotations']
'''
anno_path = anno_path.replace("\\", "/")
print(anno_path) # ./Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_1/conferenceRoom_1/Annotations
elements = anno_path.split("/") # ['.', 'Pointnet_Pointnet2_pytorch-master', 'data', 's3dis', 'Stanford3dDataset_v1.2_Aligned_Version', 'Area_1', 'conferenceRoom_1', 'Annotations']
out_filename = elements[-3]+"_"+elements[-2]+".txt" # 保存的文件,Area_1_hallway_1.txt
out_filename = output_folder + "/" + out_filename # 保存文件的完整路径。./Pointnet_Pointnet2_pytorch-master\\data/s3dis/alter_s3dis_my/Area_1_hallway_1.txt
collect_point_label(anno_path, out_filename, ".txt")
- DataSet:读取txt格式
# txt形式
class S3DISDataSetTxt(Dataset):
def __init__(self, root="./Pointnet_Pointnet2_pytorch-master/data/s3dis/alter_s3dis_my", split="train",
num_point=4096, test_area=5, block_size=1.0, sample_rate=1.0, transform=None):
'''
root:数据集所在路径
split:训练集 或 测试集("train"、"test")
num_point:采样点数
test_area:测试集、Area_5。也可以取其他数字,论文中取的是5
block_size:将采样房间变为block_size * block_size的大小,单位:m
sample_rate:采样率,1表示全采样
transform:目前不知道,后续补充
'''
self.num_point = num_point # 采样点数
self.block_size = block_size # 将采样房间变为block_size * block_size的大小,单位:m
self.transform = transform
self.room_points, self.room_labels = [], [] # 点云数据,标签值(指:一个点云文件中,每行数据加上label)
self.room_coord_min, self.room_coord_max = [], [] # 每个room(点云文件)的各个维度(X、Y、Z)最小值,最大值
num_point_all = [] # 各room中,点的总数
labelweights = np.zeros(13) # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
rooms = sorted(os.listdir(root)) # 数据集文件,['Area_1_WC_1.txt','Area_1_conferenceRoom_1.txt', ..., 'Area_6_pantry_1.txt']
rooms = [room for room in rooms if "Area_" in room]
# 数据集分割
# room.split("_")[1]:即 'Area_1_WC_1.txt'.split("_")[1]
if split=="train":
rooms_split = [room for room in rooms if int(room.split("_")[1]) != test_area]
else:
rooms_split = [room for room in rooms if int(room.split("_")[1]) == test_area]
for room_name in tqdm(rooms_split, total=len(rooms_split)):
room_path = os.path.join(root, room_name) # 获取数据集文件, ./Pointnet_Pointnet2_pytorch-master/data/s3dis/alter_s3dis_my\Area_1_WC_1.txt
room_data = np.loadtxt(room_path) # 加载数据集,XYZRGBL,N*7
points, labels = room_data[:, 0:6], room_data[:, 6]
tmp,_ = np.histogram(labels, range(14))
labelweights = labelweights + tmp # 统计全部room中,各点类别的数量
coord_min, coord_max = np.min(points, 0)[:3], np.max(points, 0)[:3]
self.room_points.append(points), self.room_labels.append(labels)
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
num_point_all.append(labels.size)
labelweights = labelweights.astype(np.float32)
labelweights = labelweights / np.sum(labelweights) # 各类别点 占 总点数的比例
# 最大值 / labelweights,作用:将类别数量出现最少的,赋予更多的权重
# 开3次方:为了使得权重变平,使得它们不易变化
self.labelweights = np.power(np.max(labelweights)/labelweights, 1/3.0)
sample_prob = num_point_all / np.sum(num_point_all) # 每个room的点云数 占 总点云数 的比例
num_iter = int( sample_rate * np.sum(num_point_all) / num_point ) # sample_rate * 所有room的总点数 / 采样点数。总共需要迭代 num_iter 次,才能把所有room采样完
room_idxs = []
for index in range(len(rooms_split)):
# sample_prob[index]:对应room的点云数占总点云数的比例;num_iter:总迭代次数
room_idxs.extend([index] * int(round(sample_prob[index] * num_iter))) # sample_prob[index] * num_iter:采样第index个room,需要的次数
self.room_idxs = np.array(room_idxs)
print("Totally {} samples in {} set.".format(len(self.room_idxs), split))
def __getitem__(self, index):
room_idx = self.room_idxs[index]
points = self.room_points[room_idx] # N × 6
labels = self.room_labels[room_idx] # N × 1
N = points.shape[0] # 点的数量
while(True):
center = points[np.random.choice(N), :3] # 随机指定一个点作为block中心
# 1m × 1m 范围
block_min = center - [self.block_size/2.0, self.block_size/2.0, 0]
block_max = center + [self.block_size/2.0, self.block_size/2.0, 0]
'''
np.where(condition, a, b):满足condition,填充a,否则填充b
若没写a,b,只有np.where(condition),则返回:(array1, array2),array1满足条件的行,array2:满足条件的列
'''
# 选定在block范围内点的索引
point_index = np.where((points[:, 0] >= block_min[0]) & (points[:, 0] <= block_max[0]) & (points[:, 1] >= block_min[1]) & (points[:, 1] <= block_max[1]))[0]
if point_index.shape[0]>1024:
break
# 采样
if point_index.shape[0] >= self.num_point:
sample_point_index = np.random.choice(point_index, self.num_point, replace=False)
else:
sample_point_index = np.random.choice(point_index, self.num_point, replace=True)
sample_points = points[sample_point_index, :] # num_point × 6
# 归一化
current_points = np.zeros([self.num_point, 9]) # num_point × 9,XYZRGBX'Y'Z',X':X归一化后的坐标
current_points[:, 6] = sample_points[:, 0] / self.room_coord_max[room_idx][0]
current_points[:, 7] = sample_points[:, 1] / self.room_coord_max[room_idx][1]
current_points[:, 8] = sample_points[:, 2] / self.room_coord_max[room_idx][2]
sample_points[:, 0] = sample_points[:, 0] - center[0]
sample_points[:, 1] = sample_points[:, 1] - center[1]
sample_points[:, 3:6] = sample_points[:, 3:6] / 255
current_points[:, 0:6] = sample_points
current_labels = labels[sample_point_index]
if self.transform:
current_points, current_labels = self.transform(current_points, current_labels)
return current_points, current_labels
def __len__(self):
return len(self.room_idxs)
hdf5格式
-
由于官方给出的 hdf5 数据,我不会用。
-
于是,我就把 官方txt格式文件中每行打上label标签后的txt文件(上述代码我已写明转换代码以及注释),转换为 hdf5格式
-
官方txt文件每行 打上label后所在路径:
D:\AnacondaCode\04Deep_Learning\03三维点云\Pointnet_Pointnet2_pytorch-master\data\s3dis\alter_s3dis_my -
把上述目录下的文件,转换为 .hdf5格式,放在:
D:\AnacondaCode\04Deep_Learning\03三维点云\data下 -
转换为hdf5格式
def convert_txt_to_h5(source = r"D:\AnacondaCode\04Deep_Learning\03三维点云\Pointnet_Pointnet2_pytorch-master\data\s3dis\alter_s3dis_my",
target = r"D:\AnacondaCode\04Deep_Learning\03三维点云\data\S3DIS_hdf5"):
for file in glob.glob(source+"/*.txt"):
name = file.replace('\\', '/').split("/")[-1][:-4]
data = np.loadtxt(file)
points = data[:, :6]
labels = data[:, 6]
f = h5py.File(target+"/"+name+".h5", "w")
f.create_dataset("data", data=points)
f.create_dataset("label", data=labels)
f.close()
convert_txt_to_h5()
- DataSet:读取hdf5格式
# hdf5形式
class S3DISDataSetH5(Dataset):
def __init__(self, root="./data/S3DIS_hdf5", split="train",
num_point=4096, test_area=5, block_size=1.0, sample_rate=1.0, transform=None):
'''
root:数据集所在路径
split:训练集 或 测试集("train"、"test")
num_point:采样点数
test_area:测试集、Area_5。也可以取其他数字,论文中取的是5
block_size:将采样房间变为block_size * block_size的大小,单位:m
sample_rate:采样率,1表示全采样
transform:目前不知道,后续补充
'''
self.num_point = num_point # 采样点数
self.block_size = block_size # 将采样房间变为block_size * block_size的大小,单位:m
self.transform = transform
self.room_points, self.room_labels = [], [] # 点云数据,标签值(指:一个点云文件中,每行数据加上label)
self.room_coord_min, self.room_coord_max = [], [] # 每个room(点云文件)的各个维度(X、Y、Z)最小值,最大值
num_point_all = [] # 各room中,点的总数
labelweights = np.zeros(13) # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
rooms = [os.path.basename(file) for file in glob.glob(root+"/*.h5")] # 数据集文件,['Area_1_conferenceRoom_1.h5', 'Area_1_conferenceRoom_2.h5', ..., 'Area_6_pantry_1.h5']
rooms = [room for room in rooms if "Area_" in room]
# 数据集分割
# room.split("_")[1]:即 'Area_1_WC_1.h5'.split("_")[1]
if split=="train":
rooms_split = [room for room in rooms if int(room.split("_")[1]) != test_area]
else:
rooms_split = [room for room in rooms if int(room.split("_")[1]) == test_area]
for room_name in tqdm(rooms_split, total=len(rooms_split)):
room_path = os.path.join(root, room_name) # 获取数据集文件, ./data/S3DIS_hdf5\Area_1_WC_1.h5
# 读取h5文件
f = h5py.File(room_path)
points = np.array(f["data"]) # [N, 6] XYZRGB
labels = np.array(f["label"]) # [N,] L
f.close()
tmp,_ = np.histogram(labels, range(14))
labelweights = labelweights + tmp # 统计全部room中,各点类别的数量
coord_min, coord_max = np.min(points, 0)[:3], np.max(points, 0)[:3]
self.room_points.append(points), self.room_labels.append(labels)
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
num_point_all.append(labels.size)
labelweights = labelweights.astype(np.float32)
labelweights = labelweights / np.sum(labelweights) # 各类别点 占 总点数的比例
# 最大值 / labelweights,作用:将类别数量出现最少的,赋予更多的权重
# 开3次方:为了使得权重变平,使得它们不易变化
self.labelweights = np.power(np.max(labelweights)/labelweights, 1/3.0)
sample_prob = num_point_all / np.sum(num_point_all) # 各个room的点云数 占 总点云数 的比例
num_iter = int( sample_rate * np.sum(num_point_all) / num_point ) # sample_rate * 所有room的总点数 / 采样点数。总共需要迭代 num_iter 次,才能把所有room采样完
room_idxs = []
for index in range(len(rooms_split)):
# sample_prob[index]:对应room的点云数占总点云数的比例;num_iter:总迭代次数
room_idxs.extend([index] * int(round(sample_prob[index] * num_iter))) # sample_prob[index] * num_iter:采样第index个room,需要的次数
self.room_idxs = np.array(room_idxs)
print("Totally {} samples in {} set.".format(len(self.room_idxs), split)) # len(self.room_idxs):47576
# len(room_idxs) == num_iter
def __getitem__(self, index):
room_idx = self.room_idxs[index]
points = self.room_points[room_idx] # N × 6
labels = self.room_labels[room_idx] # N × 1
N = points.shape[0] # 点的数量
while(True):
center = points[np.random.choice(N), :3] # 随机指定一个点作为block中心
# 1m × 1m 范围
block_min = center - [self.block_size/2.0, self.block_size/2.0, 0]
block_max = center + [self.block_size/2.0, self.block_size/2.0, 0]
'''
np.where(condition, a, b):满足condition,填充a,否则填充b
若没写a,b,只有np.where(condition),则返回:(array1, array2),array1满足条件的行,array2:满足条件的列
'''
# 选定在block范围内点的索引
point_index = np.where((points[:, 0] >= block_min[0]) & (points[:, 0] <= block_max[0]) & (points[:, 1] >= block_min[1]) & (points[:, 1] <= block_max[1]))[0]
if point_index.shape[0]>1024:
break
# 采样
if point_index.shape[0] >= self.num_point:
sample_point_index = np.random.choice(point_index, self.num_point, replace=False)
else:
sample_point_index = np.random.choice(point_index, self.num_point, replace=True)
sample_points = points[sample_point_index, :] # num_point × 6
# 归一化
current_points = np.zeros([self.num_point, 9]) # num_point × 9,XYZRGBX'Y'Z',X':X归一化后的坐标
current_points[:, 6] = sample_points[:, 0] / self.room_coord_max[room_idx][0]
current_points[:, 7] = sample_points[:, 1] / self.room_coord_max[room_idx][1]
current_points[:, 8] = sample_points[:, 2] / self.room_coord_max[room_idx][2]
sample_points[:, 0] = sample_points[:, 0] - center[0]
sample_points[:, 1] = sample_points[:, 1] - center[1]
sample_points[:, 3:6] = sample_points[:, 3:6] / 255
current_points[:, 0:6] = sample_points
current_labels = labels[sample_point_index]
if self.transform:
current_points, current_labels = self.transform(current_points, current_labels)
return current_points, current_labels
def __len__(self):
return len(self.room_idxs)
- 使用整个场景
- 以下代码借鉴了源码,与源码有较大改动
class S3DISWholeSceneDataSetH5(Dataset):
def __init__(self, root="./data/S3DIS_hdf5", block_points=4096, split='test', test_area=5, block_size=1.0, padding=0.005):
self.root = root # 数据集路径
self.block_points = block_points # 对room进行分割的一部分中,采样的点数
self.block_size = block_size # 分割部分的大小:block_size × block_size
self.padding = padding # 每个分割部分,都与相邻分割部分有重叠
self.room_points_num = [] # 每个room的点数
self.room_points = [] # 每个room中每个点的数据(XYZRGB)
self.room_labels = [] # 每个room中每个点的标签(L)
self.room_coord_min, self.room_coord_max = [], [] # 每个room中XYZ坐标的最小值与最大值
assert split in ["train", "test"] # assert True:正常执行程序 assert False:触发异常,即报错
rooms = [os.path.basename(f) for f in glob.glob(root+"/*.h5")] # ['Area_1_conferenceRoom_1.h5', 'Area_1_conferenceRoom_2.h5', ...]
if split == "train":
self.rooms = [room for room in rooms if int(room.split("_")[1]) != test_area]
else:
self.rooms = [room for room in rooms if int(room.split("_")[1]) == test_area]
labelweights = np.zeros(13) # 标签值权重
for room in tqdm(self.rooms, total=len(self.rooms)):
f = h5py.File(root+"/"+room)
points = np.array(f["data"]) # [N, 6] XYZRGB
labels = np.array(f["label"]) # [N, ] L
f.close()
temp, _ = np.histogram(labels, range(14)) # 各个标签值出现的次数
labelweights = labelweights + temp
self.room_points.append(points)
self.room_labels.append(labels)
coord_min, coord_max = np.min(points, axis=0)[0:3], np.max(points, axis=0)[0:3]
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
self.room_points_num.append(labels.shape[0])
labelweights = labelweights / np.sum(labelweights)
self.labelweights = np.power( np.max(labelweights) / labelweights, 1/3.0 )
def __getitem__(self, index):
points = self.room_points[index] # 第index个room的每个点数据 (XYZRGB)
labels = self.room_labels[index].astype(np.int64) # 第index个room的每个点标签(L)
coord_min, coord_max = self.room_coord_min[index], self.room_coord_max[index]
# points_room:一个room中每个格子的点数据(XYZRGBX'Y'Z') labels_room:一个room中每个格子的点标签 (L)
points_room, labels_room = [], []
# 把XY轴看成一个平面,类似于YOLOv1算法,对该平面进行划分,但是每个格子与其相邻的格子有重叠的部分
# 每个格子正常大小为1m×1m,但是需要有重叠部分,所有需要对格子的范围进行适当的扩大
grid_x = int(np.ceil((coord_max[0] - coord_min[0]) / self.block_size)) # X轴被划分为 grid_x 个格子
grid_y = int(np.ceil((coord_max[1] - coord_min[1]) / self.block_size)) # Y轴被划分为 grid_x 个格子
for row in range(grid_y): # 行
for col in range(grid_x): # 列
x_min = col - self.padding
y_min = row - self.padding
x_max = (col + 1) + self.padding
y_max = (row + 1) + self.padding
points_index = np.where( (points[:,0]>x_min) & (points[:,0]<x_max) & (points[:,1]>y_min) & (points[:,1]<y_max) )[0]
if points_index.shape[0] == 0:
continue
# 所采样的点数必须为 block_points 的倍数,不然后续无法进行reshape
# 若一个格子内的点数 < block_points,则重复采样缺少的点数
multiple = int(np.ceil(points_index.shape[0] / self.block_points))
if points_index.shape[0] < self.block_points:
points_index_repeat = np.random.choice(points_index, self.block_points - points_index.shape[0], replace=True)
else:
points_index_repeat = np.random.choice(points_index, multiple * self.block_points - points_index.shape[0], replace=False)
points_index = np.concatenate([points_index, points_index_repeat], axis=0)
np.random.shuffle(points_index)
# 一个格子中的 点云数据 与 点云标签
points_grid = points[points_index]
labels_grid = labels[points_index]
# XYZ坐标 归一化
# 源码中:把一个格子中的XY坐标,都减去了该格子的中心点
# 在本人代码中,无需减去(本人对减去和不减去进行了实验)中心点,得到了不能减去的结论
# 原因如下;
# 若每个格子的XY坐标都减去该格子的中心点,虽然该格子中的点相对位置不变
# 但是,该格子的点与相邻格子的点 位置会有变化
norm_xyz = np.zeros((points_index.shape[0], 3))
norm_xyz[:, 0] = points_grid[:, 0] / coord_max[0]
norm_xyz[:, 1] = points_grid[:, 1] / coord_max[1]
norm_xyz[:, 2] = points_grid[:, 2] / coord_max[2]
points_grid[:, 3:6] = points_grid[:, 3:6] / 255
points_grid = np.concatenate([points_grid, norm_xyz], axis=1) # [N, 9]
points_room.append(points_grid)
labels_room.append(labels_grid)
points_room = np.concatenate(points_room)
labels_room = np.concatenate(labels_room)
points_room = points_room.reshape(-1, self.block_points, points_room.shape[1]) # [B, N, 9]
labels_room = labels_room.reshape(-1, self.block_points) # [B, N]
return points_room, labels_room
def __len__(self):
return len(self.room_points_num)
三、构建网络
定义T-Net
class STN3d(nn.Module):
def __init__(self, channel):
super().__init__()
self.conv1 = nn.Conv1d(channel, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batch_size = x.shape[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x))) # x.shape:[32, 1024, 2500]
x = torch.max(x,-1, keepdim=True)[0] # x.shape:[32, 1024, 1], keepdim=True,保持output后的维度与input维度一样,例如:input是三维,则output也是三维
x = x.view(-1,1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
# 不知道为什么要写这个
iden = torch.eye(3).view(1, 9).repeat(batch_size, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
class STNkd(nn.Module):
def __init__(self, channel=64):
super().__init__()
self.conv1 = nn.Conv1d(channel, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, channel*channel)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.channel = channel
def forward(self, x):
batch_size = x.shape[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x))) # x.shape:[32, 1024, 2500]
x = torch.max(x,-1, keepdim=True)[0] # x.shape:[32, 1024, 1], keepdim=True,保持output后的维度与input维度一样,例如:input是三维,则output也是三维
x = x.view(-1,1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
# 不知道为什么要写这个
iden = torch.eye(self.channel).view(1, self.channel * self.channel).repeat(batch_size, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.channel, self.channel)
return x
定义PointNet主体部分
class PointNetEncoder(nn.Module):
def __init__(self, global_feature=True, feature_transform=False, channel=3):
'''
global_feature:True,则进行分类
feature_transform:True,则进行分割
'''
super().__init__()
self.stn = STN3d(channel) # 空间转换网络
self.conv1 = nn.Conv1d(channel, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feature = global_feature # 全局特征
self.feature_transform = feature_transform # 是否对高维特征进行旋转变换标定
if self.feature_transform:
self.fstn = STNkd(64)
def forward(self, x): # x.shape:[32, 3, 2500]
B, D, N = x.shape # B:batch_size,D:dimension,N:number(点的数量)
stn3 = self.stn(x) # stn3.shape:[32, 3, 3]
x = x.transpose(2,1) # x.shape:[32, 2500, 3]
if D>3: # 若 维度 > 3
feature = x[:, :, 3:]
x = x[:, :, :3]
x = torch.bmm(x, stn3) # x.shape:[32, 2500, 3] stn3:[32, 3, 3]。 使用torch.bmm(t1, t2),t1,t2必须都为3维,且第一维必须一样,其余两维按照矩阵乘法进行
if D>3:
x = torch.cat([x, feature], dim=2)
x = x.transpose(2,1) # x.shape:[32, 3, 2500]
x = F.relu(self.bn1(self.conv1(x))) # x.shape:[32, 64, 2500]
if self.feature_transform: # 是否对高维特征进行旋转
stn64 = self.fstn(x)
x = x.transpose(2,1) # x.shape:[32, 2500, 64]
x = torch.bmm(x, stn64)
x = x.transpose(2,1) # x.shape:[32, 64, 2500]
else:
stn64 = None
point_feature = x # 旋转过后的特征,point_feature.shape:[32, 64, 2500]
x = F.relu(self.bn2(self.conv2(x))) # x.shape:[32, 128, 2500]
x = self.bn3(self.conv3(x)) # x.shape:[32, 1024, 2500]
x = torch.max(x, dim=2)[0] # x.shape:[32, 1024]
x = x.view(-1, 1024) # x.shape:[32, 1024]
if self.global_feature:
return x, stn3, stn64 # 返回:global feature, input transform, feature transform
else:
x = x.view(-1, 1024, 1).repeat(1, 1, N) # x.shape:[32, 1024, 2500]
compoud = torch.cat([point_feature, x], dim=1) # compoud.shape:[32, 1088, 2500]
return compoud, stn3, stn64 # 对应点云分割算法
def feature_transform_reguliarzer(trans):
d = trans.shape[1]
I = torch.eye(d)[None, :, :] # [None, :, :]:None是为了增加1个维度,也可使用 torch.eye(d).unsqeeze(0)
if trans.is_cuda:
I = I.cuda()
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2, 1)), dim=(1,2)))
return loss
语义分割
class Semantic_Segmentation(nn.Module):
def __init__(self, num_class): # num_class:类别个数。S3DIS有13个类别
super().__init__()
self.num_class = num_class
self.point_encoder = PointNetEncoder(False, True, 9)
self.conv1 = nn.Conv1d(1088, 512, 1)
self.conv2 = nn.Conv1d(512, 256, 1)
self.conv3 = nn.Conv1d(256, 128, 1)
self.conv4 = nn.Conv1d(128, self.num_class, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
batch_size = x.shape[0] # x.shape:[32, 9, 2500]
N = x.shape[2]
x, stn3, stn64 = self.point_encoder(x)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.conv4(x) # x.shape:[32, 13, 2500]
x = x.transpose(2,1).contiguous() # contiguous():将tensor地址变连续,否则x.view()会报错。 x.shape:[32, 2500, 13]
x = F.log_softmax(x.view(-1, self.num_class), -1) # x.view(-1, self.num_class):[80000, 13]
x = x.view(batch_size, N, self.num_class)
return x, stn64
class Semantic_Segmentation_Loss(nn.Module):
def __init__(self, mat_diff_loss_scale=0.001):
super().__init__()
self.mat_diff_loss_scale = mat_diff_loss_scale
def forward(self, pred, target, stn64, weight):
loss = F.nll_loss(pred, target, weight)
mat_diff_loss = feature_transform_reguliarzer(stn64)
total_loss = loss + mat_diff_loss * self.mat_diff_loss_scale
return total_loss
四、训练与验证
注意:验证 与 测试 是两个不同任务,具体百度
train_dataset = S3DISDataSetH5(split="train")
val_dataset = S3DISDataSetH5(split="test")
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=0, drop_last=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True, num_workers=0, drop_last=True)
- PS:这里提个小插曲,我在云平台的13G内存上运行上述 4 行代码,内存不够,所以我只能运行
train代码,我觉得内存应该大于15G,可以完美运行 上述 4 行代码。 - 可能有人认为是
batch_size的问题,但是我把batch_size = 1还是内存不够
lr = 0.01
EPOCH = 60
weights = torch.tensor(train_dataset.labelweights, dtype=torch.float64) # 各类的权重
model = Semantic_Segmentation(13).double() # 13:语义分割的类别总数
optimizer = optim.Adam(model.parameters(), lr) # 优化器
criterion = Semantic_Segmentation_Loss() # 损失函数
if torch.cuda.is_available():
model = model.cuda()
weights = weights.cuda()
for epoch in range(EPOCH):
# 训练
num_batch = len(train_dataloader) # batch数量,不是batch_size
total_correct = 0 # 预测正确的数量,从第0次循环到此次循环,预测正确的数量的总和
total_point_number = 0 # 当前循环下,所遍历的点数(包括之间的循环)。即 统计出从第0次循环到此次循环,所遍历点数的总和
loss_sum = 0 # 一个batch中,总损失
model = model.train() # 设置为 训练模式
for points, labels in train_dataloader: # points.shape:[32, N, C] 例如:[32, 4096, 9] labels:[32, N] 例如:[32, 4096]
if torch.cuda.is_available():
points = points.cuda()
labels = labels.cuda()
optimizer.zero_grad()
points = points.transpose(2,1) # points.shape:[32, C, N]
sem_pre, stn64 = model(points) # sem_pre.shape:[32, N, NUM_CLASS]
sem_pre = sem_pre.contiguous().view(-1, 13)
labels = labels.view(-1, 1)[:, 0]
loss = criterion(sem_pre, labels.long(), stn64, weights) # 一个batch中的损失
loss.backward()
optimizer.step()
loss_sum = loss_sum + loss.item() # 一个batch中的总损失
pre_class = sem_pre.max(1)[1] # 每个点预测的类别
correct = torch.sum(pre_class == labels) # 每batch中的准确率
total_correct = total_correct + correct.item()
total_point_number = total_point_number + points.shape[0] * points.shape[2] # points.shape[0]:32,batch_size为32;points.shape[2]:4096,每个batch的元素中的点数为4096。
print("第"+str(epoch+1)+"轮,损失:"+str(loss_sum/32)+",准确率:"+str(total_correct/total_point_number))
torch.save(model.state_dict(), "./model/model_state_dict_"+str(epoch+1)+".pkl")
# 验证
with torch.no_grad():
num_batch = len(val_dataloader)
total_correct = 0
total_point_number = 0
loss_sum = 0
labelweights = np.zeros(13)
total_correct_class = [0] * 13 # 各类别预测正确的总数量,同时也是IOU的分子
tota1_point_number_class = [0] * 13 # 各类别的总点数
total_iou_deno_class = [0] * 13 # IOU的分母
model = model.eval()
for points, labels in val_dataloader:
points = points.type(torch.float64) # points.shape:[32, 4096, 9]
labels = labels.type(torch.long) # labels.shape:[32, 4096]
points = points.transpose(2, 1)
labels = labels.reshape(-1) # [32×4096]
sem_pre, stn64 = model(points) # sem_pre:[B, N, 13]
sem_pre = sem_pre.reshape(-1, 13) # [B×N, 13]
loss = criterion(sem_pre, labels, stn64, weights)
loss_sum = loss_sum + loss.item()
pre_class = sem_pre.max(-1)[1]
correct = torch.sum(pre_class == labels)
total_correct = total_correct + correct
total_point_number = total_point_number + points.shape[0] * points.shape[2]
temp,_ = np.histogram(labels, range(14))
labelweights = labelweights + temp
for i in range(13):
tota1_point_number_class[i] = tota1_point_number_class[i] + torch.sum( labels == i ).item()
total_correct_class[i] = total_correct_class[i] + torch.sum( (pre_class == i) & (labels == i) ).item()
total_iou_deno_class[i] = total_iou_deno_class[i] + torch.sum( (pre_class == i) | (labels == i) ).item()
labelweights = labelweights / np.sum(labelweights)
mIOU = np.mean( np.array(total_correct_class) / ( np.array(total_iou_deno_class)+1e-10 ) )
print("验证集 平均损失:%s,Avg mIOU:%s,准确率:%s,Avg 准确率:%s" % (str(loss_sum/num_batch),str(mIOU),
str(total_correct/total_point_number),
str(np.mean(np.array(total_correct_class)/np.array(tota1_point_number_class)))))
五、测试
- 分析源码过程中,不明白该部分,下面按照我自己的理解,构建测试代码
test_dataset = S3DISWholeSceneDataSetH5()
- 代码说明:
points, labels = test_dataset[room_index] # room_index:第room_index个房间
points.shape:[272, 4096, 9]
因为模型不能run这么大的数据,所以需要分开run。
272分成n个 32 大小;若272不能除尽32,则无法除尽的部分分为run的部分。
例如:
272 / 32 = 8.5 # 无法除尽
272 % 32 = 16 # 余下16个
则:
8个 [32, 4096, 9]
1个 [16, 4096, 9]
batch_size = 32
# 加载模型参数
model = Semantic_Segmentation(13).double() # 13:语义分割的类别总数
model.load_state_dict(torch.load("./model/pointnet_state_dict_18.pkl", map_location='cpu'))
model.eval()
with torch.no_grad():
room_id = test_dataset.rooms
room_size = len(test_dataset) # 272 有272个room文件
idx1 = 0 # 计数器,能除尽
idx2 = 0 # 计数器,不能除尽
# 测试
for room_index in tqdm(range(room_size), total=room_size):
print("start [%d/%d] %s ..." % (room_index, room_size, room_id[room_index]))
tota1_point_number_class = [0] * 13
total_correct_class = [0] * 13
total_iou_deno_class = [0] * 13
points, labels, weights, grid_points_index = test_dataset[room_index]
points = torch.tensor(points)
labels = torch.tensor(labels)
room_pre_class = []
room_labels = []
batch_points = torch.zeros(batch_size, points.shape[1], points.shape[2])
batch_labels = torch.zeros(batch_size, points.shape[1])
sum_batch_size1 = 0
while points.shape[0] % batch_size == 0: # 能除尽
batch_points = points[idx1*batch_size:(idx1+1)*batch_size, :, :] # [32, N, 9]
batch_labels = labels[idx1*batch_size:(idx1+1)*batch_size, :] # [32, N]
batch_points = batch_points.transpose(2, 1) # [B, 9, N]
sem_pre, _ = model(batch_points) # [B, N, 13]
pre_class = torch.max(sem_pre, dim=-1)[1] # [B, N] 预测点的类别
room_pre_class.append(pre_class)
room_labels.append(batch_labels)
idx1 = idx1 + 1
sum_batch_size1 = sum_batch_size1 + batch_points.shape[0]
if sum_batch_size1 == points.shape[0]:
break
sum_batch_size2 = 0
while points.shape[0] % batch_size != 0: # 不能除尽
whether = int(points.shape[0] / batch_size) # 整数,whether个batch中有 32 个 批数据
final_start_batch = points.shape[0] % batch_size
if idx2 == whether:
batch_points = points[-final_start_batch:, :, :] # [final_start_batch, N, 9]
batch_labels = labels[-final_start_batch:, :] # [final_start_batch, N]
else:
batch_points = points[idx2*batch_size:(idx2+1)*batch_size, :, :] # [32, N, 9]
batch_labels = labels[idx2*batch_size:(idx2+1)*batch_size, :] # [32, N]
batch_points = batch_points.transpose(2, 1) # [B, 9, N]
sem_pre, _ = model(batch_points) # [B, N, 13]
pre_class = torch.max(sem_pre, dim=-1)[1] # [B, N] 预测点的类别
room_pre_class.append(pre_class)
room_labels.append(batch_labels)
idx2 = idx2 + 1
sum_batch_size2 = sum_batch_size2 + batch_points.shape[0]
if sum_batch_size2 == points.shape[0]:
break
room_pre_class = torch.cat(room_pre_class).reshape(-1) # [N_all]
room_labels = torch.cat(room_labels).reshape(-1) # [N_all]
for i in range(13):
tota1_point_number_class[i] = tota1_point_number_class[i] + torch.sum( room_labels == i ).item()
total_correct_class[i] = total_correct_class[i] + torch.sum( (room_pre_class == i) & (room_labels == i) ).item()
total_iou_deno_class[i] = total_iou_deno_class[i] + torch.sum( (room_pre_class == i) | (room_labels == i) ).item()
mIOU = np.mean( np.array(total_correct_class) / ( np.array(total_iou_deno_class)+1e-10 ) )
print("Avg mIOU:%s,准确率:%s" % (str(mIOU),str(sum(total_correct_class)/sum(tota1_point_number_class))))
show_point_cloud = torch.cat([points.reshape(-1,9), room_labels.reshape(-1,1), room_pre_class.reshape(-1,1)], dim=1)
f = h5py.File("./predition/"+room_id[room_index], "w")
f.create_dataset("data", data=show_point_cloud)
f.close()
六、显示点云
- 学习链接:https://zhuanlan.zhihu.com/p/338845304
- 显示对
Area_5_conferenceRoom_1.h5的预测结果。 - 因为云平台的关系,每次训练最长13小时,每周总共时间40小时左右,我连续训练了2次,总计26小时左右,训练了18个
EPOCH。 - 在对
Area_5_conferenceRoom_1.h5进行test时,Avg mIOU为:0.03925852346625844,准确率为:0.2383061986770073。
# 显示预测
path = "./predition/Area_5_conferenceRoom_1.h5"
f = h5py.File(path, "r")
data = f["data"][:, :6]
pre_labels = f["data"][:, 10]
points = data[:, :3]
# 把label值 转换为 对应的RGB值
colors = np.zeros((pre_labels.shape[0],3), dtype=np.float) # shape:[N, 3]
# 把label标签值 改为 对应RGB
for i in range(13):
index = np.where(pre_labels == i)[0]
colors[index] = np.array(label2color[i]) / 255
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points)
pcd.colors = o3d.utility.Vector3dVector(colors) # RRB 范围:0-1
o3d.visualization.draw_geometries([pcd])

- 显示原数据(RGB 和 对应类别的颜色)
# 对应类别的颜色
path = "./data/S3DIS_hdf5/Area_5_conferenceRoom_1.h5"
f = h5py.File(path, "r")
data = np.array(f["data"])
labels = np.array(f["label"])
points = np.array(data[:, :3])
# 把label值 转换为 对应的RGB值
colors = np.zeros((labels.shape[0],3), dtype=np.float) # shape:[N, 3]
# 把label标签值 改为 对应RGB
for i in range(13):
index = np.where(labels == i)[0]
colors[index] = np.array(label2color[i]) / 255
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points)
pcd.colors = o3d.utility.Vector3dVector(colors) # RRB 范围:0-1
o3d.visualization.draw_geometries([pcd])

# RGB
path = "./data/S3DIS_hdf5/Area_5_conferenceRoom_1.h5"
f = h5py.File(path, "r")
data = np.array(f["data"])
# labels = np.array(f["label"])
points = np.array(data[:, :3])
colors = np.array(data[:, 3:6]) / 255
# # 把label值 转换为 对应的RGB值
# colors = np.zeros((labels.shape[0],3), dtype=np.float) # shape:[N, 3]
# # 把label标签值 改为 对应RGB
# for i in range(13):
# index = np.where(labels == i)[0]
# colors[index] = np.array(label2color[i]) / 255
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points)
pcd.colors = o3d.utility.Vector3dVector(colors) # RRB 范围:0-1
o3d.visualization.draw_geometries([pcd])

Reference
[1] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660.
[2] https://github.com/yanx27/Pointnet_Pointnet2_pytorch
















 1920
1920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











