







Pytorch是一个强大的张量计算框架,在这个栏目中,我将与大家一起学习Pytorch官方的教程文档,详细分析每一个方法。
本专题目的是让大家了解Pytorch中的各个方法,我们不会去纠结其更深层次的理解,在官方文档中,注释都是英文的,我会将代码进行逐句解析,让大家对其用途有个大致的了解。
在介绍Pytorch前,我们来看第一个示例,用numpy实现网络的前向和后向传递:
1.定义参数、数据
import numpy as np
# N是batch_size,D_in是输入尺寸,H是隐藏层尺寸,D_out是输出层尺寸
N, D_in, H, D_out = 64, 1000, 100, 10
# 创造一些随机数作为输入输出数据
x = np.random.randn(N, D_in) # 64, 1000
y = np.random.randn(N, D_out) # 64, 10这部分的目的是为了造一些随机数据来使用。
来看这里出现的一个方法:np.random.randn(),这个方法用于返回一组服从正态分布的数据。
需要传入的参数就是数据的维度。例如这里我们传入的x的数据维度就是:64 * 1000。
在这里np.random.randn()方法返回了维度为64 * 1000并且服从正态分布的一组数据。理解到这里就可以了。同理y就返回了一组维度为 64 * 10并且服从正态分布的一组数据。
# 随机初始化权重
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)w1,w2也是同理。w1,w2是初始化的权重。
2.训练过程
learning_rate = 1e-6
for t in range(500):
# 正向传递:计算预测y
h = x.dot(w1)
h_relu = np.maximum(h, 0)
y_pred = h_relu.dot(w2)
# 计算并打印loss
loss = np.square(y_pred - y).sum()
print(t, loss)learning_rate是学习率。
循环500次:计算x与w1的点积(.dot())赋值给h。np.maximum(h,0),这个方法是比较h与0每个元素的大小,然后输出较大的结果,也就是h中的负数就取0。可以看到下图中-27这一项就换成了0。
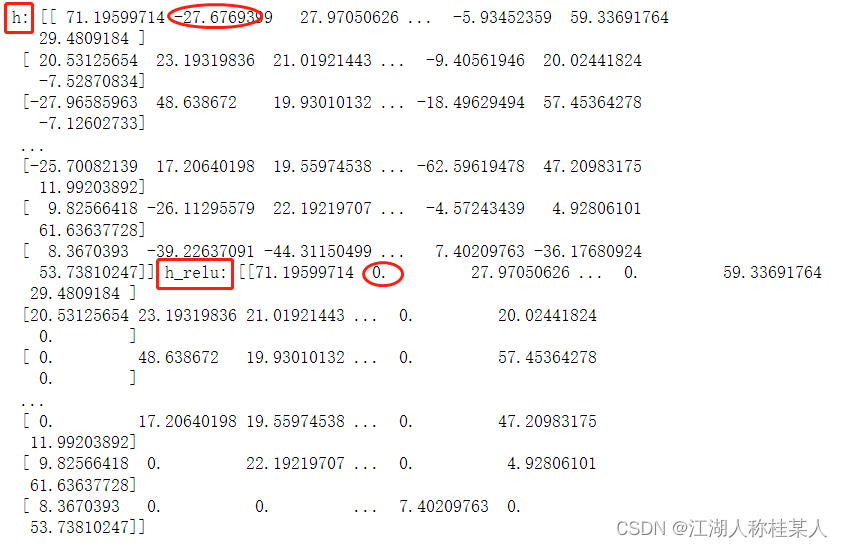
比较后的结果就是h_relu,再次求h_relu与w2的点积,赋值给y_pred。y_pred其实就是作为预测值。
损失就是y_pred - y,再对其求取平方(np.square())的和,这就是一种用平方和作为损失函数的表示方法,和nn.MSELoss类似。
3.计算梯度并更新权重(注意这段代码是上一段for循环内部的)
learning_rate = 1e-6
for t in range(500):
# 正向传递:计算预测y
h = x.dot(w1)
h_relu = np.maximum(h, 0)
y_pred = h_relu.dot(w2)
# 计算并打印loss
loss = np.square(y_pred - y).sum()
print(t, loss)
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# 更新权重
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
print(w1, w2)每计算一次梯度更新一次权重,实现了网络的前向传递。
grad_h[h < 0] = 0,是将h中小于0的部分替换成0,赋值给grad_h。
grad_h_relu.copy(),是将grad_h_relu复制一份赋值给grad_h。
计算500次后,w1,w2就被修改成比初始权重拟合度更高的一个值了。
4.PyTorch官方完成源码
# -*- coding: utf-8 -*-
import numpy as np
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
# Randomly initialize weights
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
learning_rate = 1e-6
for t in range(500):
# Forward pass: compute predicted y
h = x.dot(w1)
h_relu = np.maximum(h, 0)
y_pred = h_relu.dot(w2)
# Compute and print loss
loss = np.square(y_pred - y).sum()
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# Update weights
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









