







该论文针对基于深度学习的多任务图像检索进行了研究并提出了改进方法。
多目标学习通常通过共享卷积神经网络的中间层实现,参数共享。然而不同的目标任务之间往往存在冲突,即相消干涉,导致训练难以进行,本文将这种冲突具体化,用训练时的反向传播梯度表示。
如果两个不同任务的梯度经(2)式计算后,等于-1,即两个梯度方向的夹角大于90度(起反作用)则称为有相消干涉:


该文章还定义了UCR(Update Compliance Ratio)指标来进行对相消干涉的定量分析指标,定义如下:在网络训练时,记录一次迭代中上文(2)式的值大于零的比率,以此衡量两不同任务之间的冲突程度。
在定义了相消干涉衡量标准之后,本文提出一种改进方法减小相消干涉,引入调制模块,即引入了线性映射从而针对不同的任务引入了每个任务的特定性。引入的调制模块每个部分通过学习不同任务的损失进行调整权值。
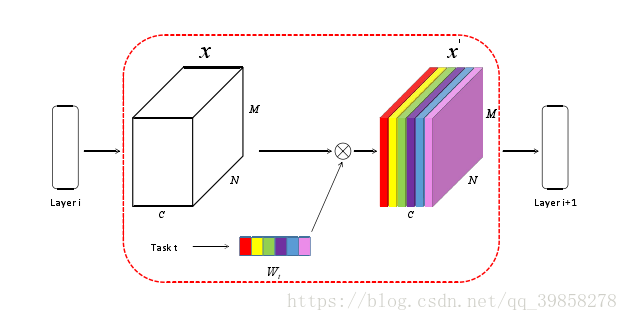
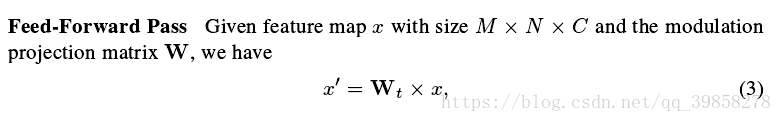
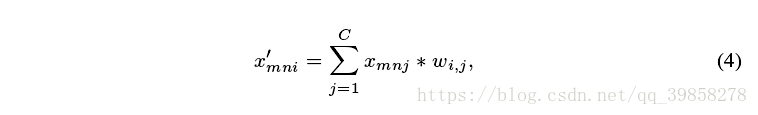

该文使用如下网络结构:
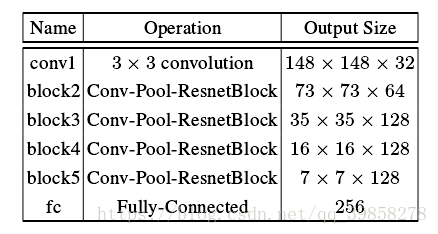
之后本文进行了多个数据集的测试,在大规模数据集上进行图片检索并与许多其他的算法进行了对比分析,效果良好,尤其是多目标任务检索时。
并进行了推广测试,如图所示效果优良。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









