







当字段类型为字符串(varchar,text,longtext等文本字符串类型的字段)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
一、语法
create index idx_xxxx on table_name(column(n)); -- n表示提取字符串的前面几个字符来建立索引
示例:
为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user(email(5));
Sub_part:已截取到的部分;如果对整个字段建立索引,那么就为NULL

二、前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值, 索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
那我们如何来求取它的选择性能呢?此时我们借助两个公式即可。
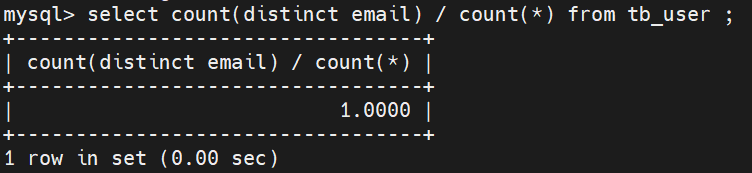
select count(distinct email) / count(*) from tb_user ;
-- 根据email字段来建立前缀索引来降低索引的体积
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
如下图,截取email的前10个字符出来的数据也是1
接下来截取前9个,可以发现就出现重复了,它的选择性就不是1了

紧接着截取前8个,可以发现截取前8个和前9个选择性是一样的,当然截取8个它的索引体积肯定会更小

接下来截取前6个,一样

那截取前5个呢?此时发现,一直都是9583,那也就说明,截取前五个字符串组成的前缀名的选择性和截取前9个是一样的,从体积考虑,我们肯定截取前5个就行了。

那如果我们截取前4个,此时选择性又降低了

这个就得看在我们的业务系统中我们想取多大的选择性,如果选择性尽可能高,那么此时你就取前10个前缀,如果你要去平衡选择性与我们的前缀,或者说索引的体积,那么我们就可以考虑取5个前缀。
三、前缀索引的查询流程
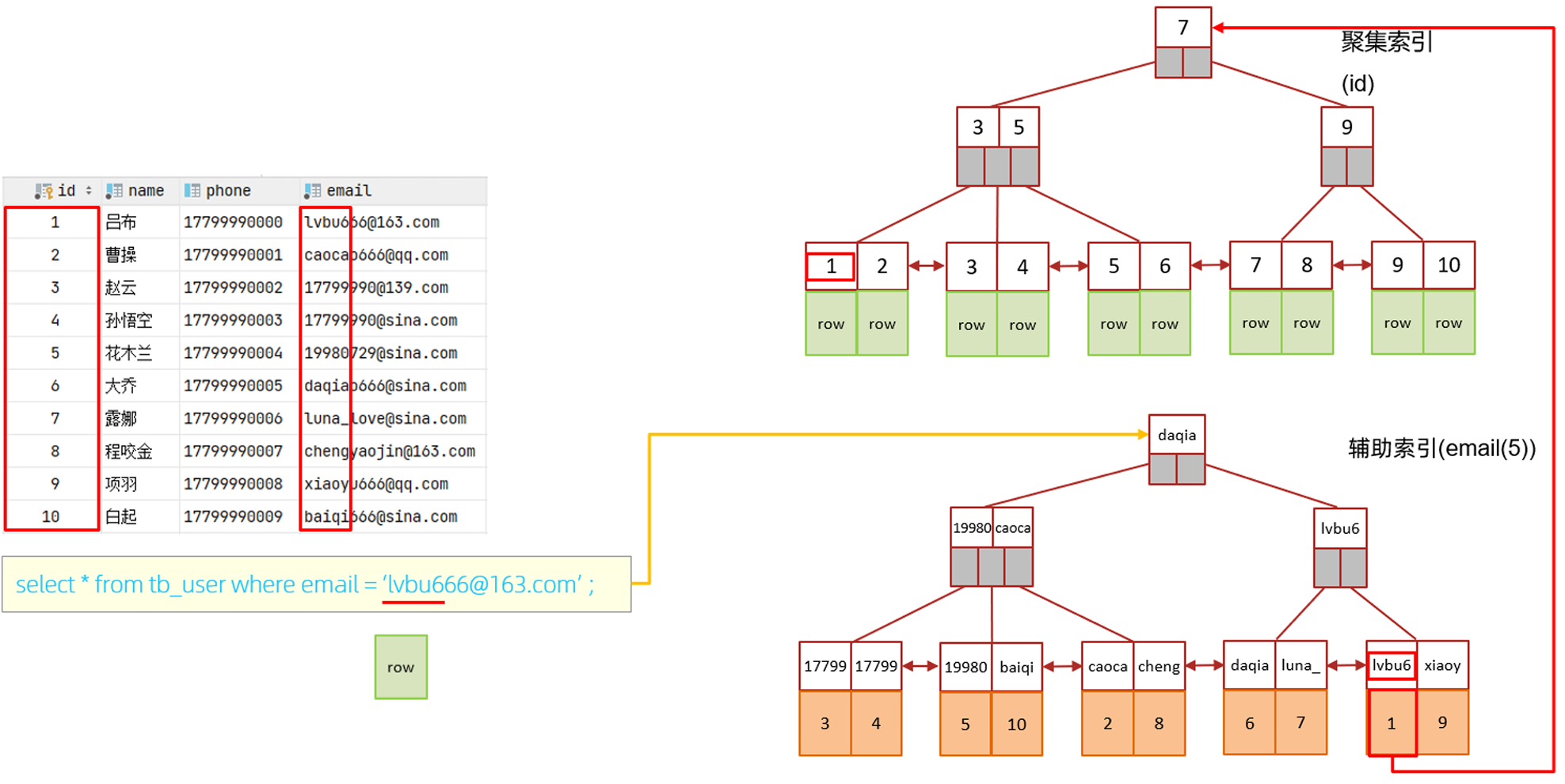
拿到row后,需要查看row中的email的值是不是我所传进来的email,如果是,那么此时我就要将这一行的数据查询到,并返回;然后再往 lvbu6 的下一个结点走(因为它是一个链表),再去看下一个元素是不是 lvbu6,如果不是,我直接返回这一行数据,如果不是,还需要再查询下一行数据,最终组装数据并返回。
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









