







我这里暂时只考虑图片,不考虑视频
mat
http://human-pose.mpi-inf.mpg.de/#download
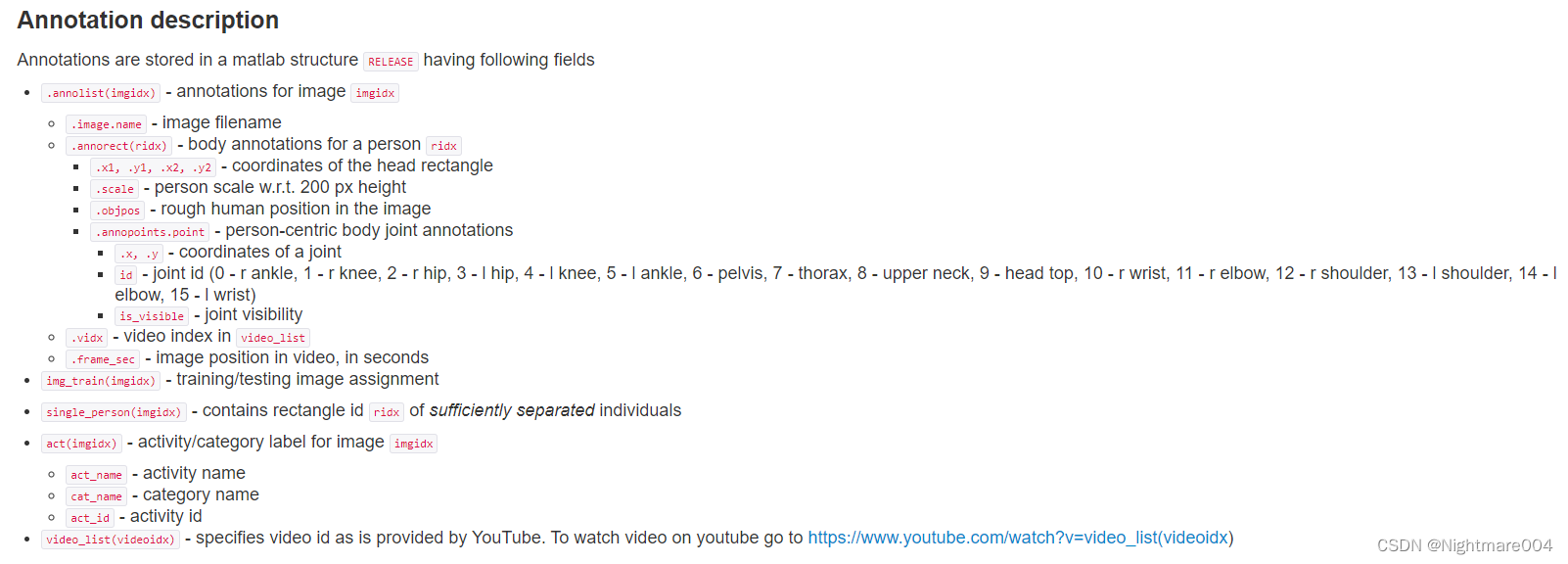
这里的
o
b
j
p
o
s
objpos
objpos是人的一个大概的位置
s
c
a
l
e
∗
200
scale*200
scale∗200是一个人框的大小
所以每一个人的bbox,就是以
o
b
j
p
o
s
objpos
objpos为中心,
s
c
a
l
e
∗
200
scale*200
scale∗200为边长的正方形
x
1
,
y
1
,
x
2
,
y
2
x1,y1,x2,y2
x1,y1,x2,y2是每个人的头部的大小,用于后续计算
p
c
k
pck
pck
p
o
i
n
t
point
point是关键点
由于一个图片可能不止一个人,所以这几个属性可能不止一套
i m g t r a i n img_train imgtrain为是否是训练集
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
import shutil
from cv2 import cv2
from scipy.io import loadmat
from tqdm import tqdm
img_path = '/mnt/data/datasets/mpii_human_pose_v1/images'
annotation_path = '/mnt/data/datasets/mpii_human_pose_v1/mpii_human_pose_v1_u12_2/mpii_human_pose_v1_u12_1.mat'
store_path = '/mnt/data/datasets/temp'
no_rect = os.path.join(store_path, 'no_rect')
one_rect = os.path.join(store_path, 'one_rect')
multi_rect = os.path.join(store_path, 'multi_rect')
os.makedirs(no_rect, exist_ok=True)
os.makedirs(one_rect, exist_ok=True)
os.makedirs(multi_rect, exist_ok=True)
if __name__ == '__main__':
mat = loadmat(annotation_path)
annolist = mat['RELEASE']['annolist'][0, 0][0]
for cur_annolist in tqdm(annolist):
img_name = cur_annolist['image']['name'].item()[0]
abs_img_path = os.path.join(img_path, img_name)
if not os.path.exists(abs_img_path):
# # 040348287.jpg
# # 013401523.jpg
# # 002878268.jpg
continue
annorect = cur_annolist['annorect']
# {(1, 12), (1, 2), (1, 5), (1, 11), (0, 0), (1, 1), (1, 8), (1, 14), (1, 4), (1, 17), (1, 7),
# (1, 13), (1, 10), (1, 16), (1, 6), (1, 3), (1, 9)}
if 0 in annorect.shape:
# print(annorect.dtype)
shutil.copy(abs_img_path, no_rect)
continue
is_multi = annorect.shape[1] > 1
img = cv2.imread(abs_img_path)
for cur_annorect in annorect[0]:
if cur_annorect is None:
continue
if 'scale' in cur_annorect.dtype.names and 0 not in cur_annorect['scale'].shape:
scale = cur_annorect['scale'].item()
if 'objpos' in cur_annorect.dtype.names and 0 not in cur_annorect['objpos'].shape:
objpos = cur_annorect['objpos']
x = objpos['x'].item().item()
y = objpos['y'].item().item()
img = cv2.circle(img, (x, y), 5, (0, 255, 0), thickness=-1, lineType=cv2.LINE_AA)
rect_size = scale * 200
left_x = int(x - rect_size / 2)
left_y = int(y - rect_size / 2)
right_x = int(left_x + rect_size)
right_y = int(left_y + rect_size)
img = cv2.rectangle(img, (left_x, left_y), (right_x, right_y), (0, 255, 0), lineType=cv2.LINE_AA)
if 'x1' in cur_annorect.dtype.names:
x1 = cur_annorect['x1'].item()
y1 = cur_annorect['y1'].item()
x2 = cur_annorect['x2'].item()
y2 = cur_annorect['y2'].item()
img = cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 255), lineType=cv2.LINE_AA)
if 'annopoints' in cur_annorect.dtype.names and 0 not in cur_annorect['annopoints'].shape:
point = cur_annorect['annopoints']['point'].item()
for p in point[0]:
p_x = p['x'].item()
p_y = p['y'].item()
p_id = p['id'].item()
if 'is_visible' in p.dtype.names and 0 not in p['is_visible'].shape:
p_is_visible = p['is_visible'].item()
if 1 == p_is_visible:
img = cv2.circle(img, (p_x, p_y), 5, (255, 255, 0), thickness=-1, lineType=cv2.LINE_AA)
img = cv2.putText(img, str(p_id), (p_x, p_y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255))
if is_multi:
cv2.imwrite(os.path.join(multi_rect, img_name), img)
else:
cv2.imwrite(os.path.join(one_rect, img_name), img)
绿色的点是
o
b
j
p
o
s
objpos
objpos,绿色的框是根据
o
b
j
p
o
s
objpos
objpos和
s
c
a
l
e
∗
200
scale*200
scale∗200计算出来的bbox
黄色的是
x
1
,
y
1
,
x
2
,
y
2
x1,y1,x2,y2
x1,y1,x2,y2(头bbox)
青色的是关键点,红色的是关键点的标号

h5
下载https://github.com/princeton-vl/pytorch_stacked_hourglass/tree/master/data/MPII/annot
生成方式
https://github.com/princeton-vl/pose-hg-train/blob/master/src/misc/mpii.py
https://github.com/princeton-vl/pose-hg-train/blob/master/src/misc/convert_annot.py
这里
o
b
j
p
o
s
objpos
objpos变成了
c
e
n
t
e
r
center
center
p
o
i
n
t
point
point变成了
p
a
r
t
part
part
n
o
r
m
a
l
i
z
e
normalize
normalize是pck里的归一化系数(头的bbox的对角线的
60
%
60\%
60%)
然后他这里一个标签只会框一个人
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import os
import h5py
import numpy as np
from cv2 import cv2
from tqdm import tqdm
img_path = '/mnt/data/datasets/mpii_human_pose_v1/images'
train_annotation_path = '/mnt/data/datasets/mpii_human_pose_v1/annot/train.h5'
store_path = '/mnt/data/datasets/temp'
os.makedirs(store_path, exist_ok=True)
if __name__ == '__main__':
# 'center', 'imgname', 'index', 'name', 'name_', 'normalize', 'part', 'person', 'scale', 'torsoangle', 'visible'
train_f = h5py.File(train_annotation_path, 'r')
# 22246
t_imgname = np.array([x.decode('UTF-8') for x in train_f['imgname']])
total = t_imgname.shape[0]
t_center = train_f['center'][()]
t_scale = train_f['scale'][()]
t_part = train_f['part'][()]
t_visible = train_f['visible'][()]
t_normalize = train_f['normalize'][()]
# len(set(t_imgname)) # 14679
stored = set()
for center, scale, part, visible, normalize, imgname in tqdm(
zip(t_center, t_scale, t_part, t_visible, t_normalize, t_imgname), total=total):
if imgname in stored:
img = cv2.imread(os.path.join(store_path, imgname))
else:
img = cv2.imread(os.path.join(img_path, imgname))
stored.add(imgname)
x, y = center
if x >= 0:
img = cv2.circle(img, (int(x), int(y)), 5, (0, 255, 0), thickness=-1, lineType=cv2.LINE_AA)
rect_size = scale * 200
left_x = int(x - rect_size / 2)
left_y = int(y - rect_size / 2)
right_x = int(left_x + rect_size)
right_y = int(left_y + rect_size)
img = cv2.rectangle(img, (left_x, left_y), (right_x, right_y), (0, 255, 0), lineType=cv2.LINE_AA)
for p_id, ((p_x, p_y), v) in enumerate(zip(part, visible)):
p_x = int(p_x)
p_y = int(p_y)
v = int(v)
if v <= 0 or p_x <= 0 or p_y <= 0:
continue
img = cv2.circle(img, (p_x, p_y), 5, (255, 255, 0), thickness=-1, lineType=cv2.LINE_AA)
img = cv2.putText(img, str(p_id + 1), (p_x, p_y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255))
cv2.imwrite(os.path.join(store_path, imgname), img)
神奇的是,这个算出来似乎和原版的算出来的不太一样

json
https://drive.google.com/drive/folders/1En_VqmStnsXMdldXA6qpqEyDQulnmS3a?usp=sharing
https://github.com/ilovepose/fast-human-pose-estimation.pytorch
与h5没什么差别
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import numpy as np
from tqdm import tqdm
import os
import shutil
from cv2 import cv2
import h5py
import json
img_path = '/mnt/data/datasets/mpii_human_pose_v1/images'
train_annotation_path = '/mnt/data/datasets/mpii_human_pose_v1/annot2/train.json'
store_path = '/mnt/data/datasets/temp'
os.makedirs(store_path, exist_ok=True)
if __name__ == '__main__':
with open(train_annotation_path, 'r') as f:
data = json.load(f)
stored = set() # 14679
for cur_data in tqdm(data):
# dict_keys(['joints_vis', 'joints', 'image', 'scale', 'center'])
imgname = cur_data['image']
# break
if imgname in stored:
img = cv2.imread(os.path.join(store_path, imgname))
else:
img = cv2.imread(os.path.join(img_path, imgname))
stored.add(imgname)
x, y = cur_data['center']
if x >= 0 and y >= 0:
scale = cur_data['scale']
img = cv2.circle(img, (int(x), int(y)), 5, (0, 255, 0), thickness=-1, lineType=cv2.LINE_AA)
rect_size = scale * 200
left_x = int(x - rect_size / 2)
left_y = int(y - rect_size / 2)
right_x = int(left_x + rect_size)
right_y = int(left_y + rect_size)
img = cv2.rectangle(img, (left_x, left_y), (right_x, right_y), (0, 255, 0), lineType=cv2.LINE_AA)
for p_id, ((p_x, p_y), v) in enumerate(zip(cur_data['joints'], cur_data['joints_vis'])):
p_x = int(p_x)
p_y = int(p_y)
# v = int(v)
if 0 == v or p_x < 0 or p_y < 0:
continue
img = cv2.circle(img, (p_x, p_y), 5, (255, 255, 0), thickness=-1, lineType=cv2.LINE_AA)
img = cv2.putText(img, str(p_id + 1), (p_x, p_y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255))
cv2.imwrite(os.path.join(store_path, imgname), img)

另一个版本
https://github.com/bearpaw/pytorch-pose/blob/master/data/mpii/mpii_annotations.json

















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











