







Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings
摘要
提出绝悟-SL(JueWu-SL)将宏观战略(macro-strategy)和微观管理(micromanagement)以监督和端到端的方式整合到神经网络中。
在王者荣耀上测试,达到有最高的水准
介绍
宏观战略:英雄去哪
微观策略:英雄到了之后,做什么
假设我们可以拥有标注良好的标签(嵌入了团队的策略和行动),已经MOBA游戏中每个小型战斗的表达,那么在足够训练数据的情况下,SL就有可能提炼出从小型战斗到标签的映射
模型
- 特征
- 向量特征
- 类似图像特征
- 标签
- 宏观战略目的标签
- 全局目的
- 局部目的
- 微观管理动作标签
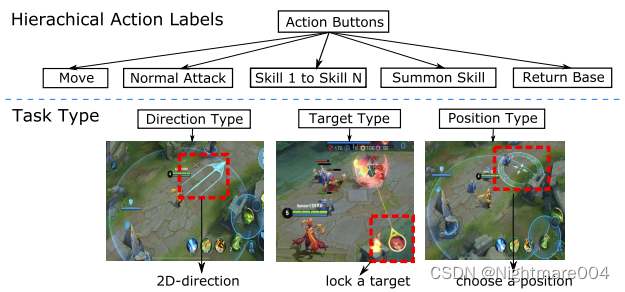
- 高维(high-level action):例如移动
- 具体动作:例如移动方向
- 宏观战略目的标签
模型输出动作标签,目的标签是辅助任务
宏观战略目的
移动区域
哪里发生战斗玩家就有可能去哪,因此标签定义为下次玩家去哪
其中攻击行为不一定是玩家的目标,也可能是去那埋伏
因此我们只考虑存在连续攻击行为的区域(?)
Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings
摘要
提出绝悟-SL(JueWu-SL)将宏观战略(macro-strategy)和微观管理(micromanagement)以监督和端到端的方式整合到神经网络中。
在王者荣耀上测试,达到有最高的水准
介绍
宏观战略:英雄去哪
微观策略:英雄到了之后,做什么
假设我们可以拥有标注良好的标签(嵌入了团队的策略和行动),已经MOBA游戏中每个小型战斗的表达,那么在足够训练数据的情况下,SL就有可能提炼出从小型战斗到标签的映射
模型
- 特征
- 向量特征
- 类似图像特征
- 标签
- 宏观战略目的标签
- 全局目的
- 局部目的
- 微观管理动作标签
- 高维(high-level action):例如移动
- 具体动作:例如移动方向
- 宏观战略目的标签
模型输出动作标签,目的标签是辅助任务
宏观战略目的
移动区域
哪里发生战斗玩家就有可能去哪,因此标签定义为下次玩家去哪
其中攻击行为不一定是玩家的目标,也可能是去那埋伏
因此我们只考虑存在连续攻击行为的区域(?)
全局目的
玩家下次攻击的目标或区域
例如:刷兵,刷野,推塔
将小地图分为
N
×
N
N \times N
N×N个区域
标签:下一次去哪个区域
设
s
s
s是一个session,每个session以攻击行为结束
t
s
t_s
ts是
s
s
s的开始帧
y
s
y_s
ys:区域
s
−
1
s-1
s−1的标签是
y
s
y_s
ys,代表想要移动到这
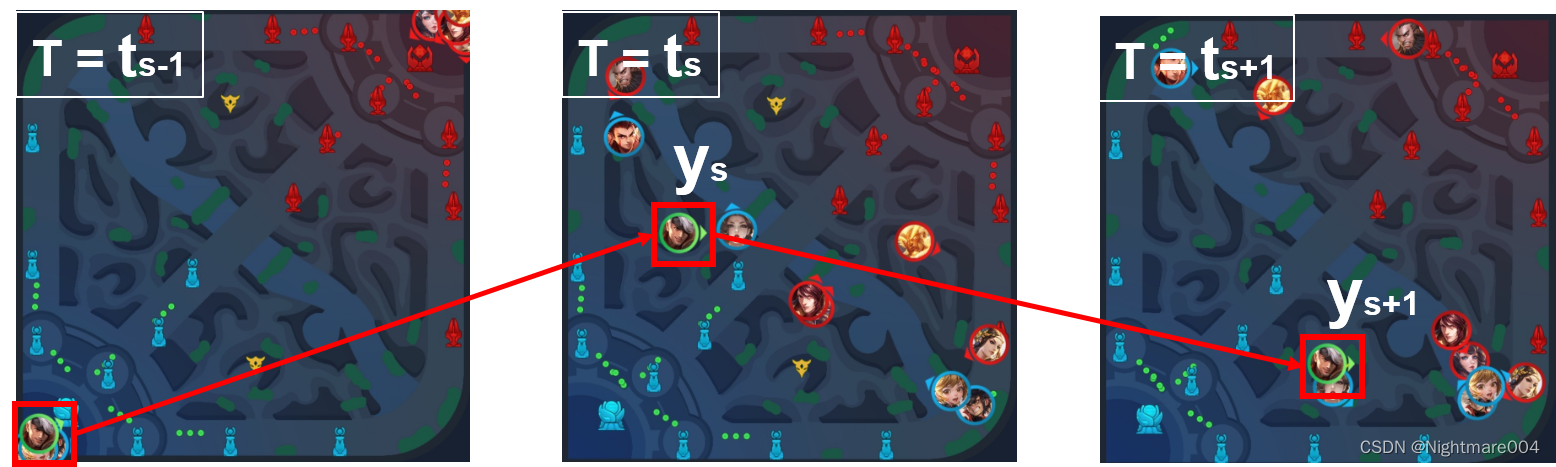
局部目的
局部战斗的短期计划
例如躲草丛,回塔下,等待目标英雄
将玩家局部地图分为
M
×
M
M \times M
M×M
标签:局部地图的区域,通过两次攻击事件中玩家的中间位置提取(?)
微观管理层级动作设计
第一层:什么动作(eg.移动
第二层:动作怎么执行(eg.移动方向
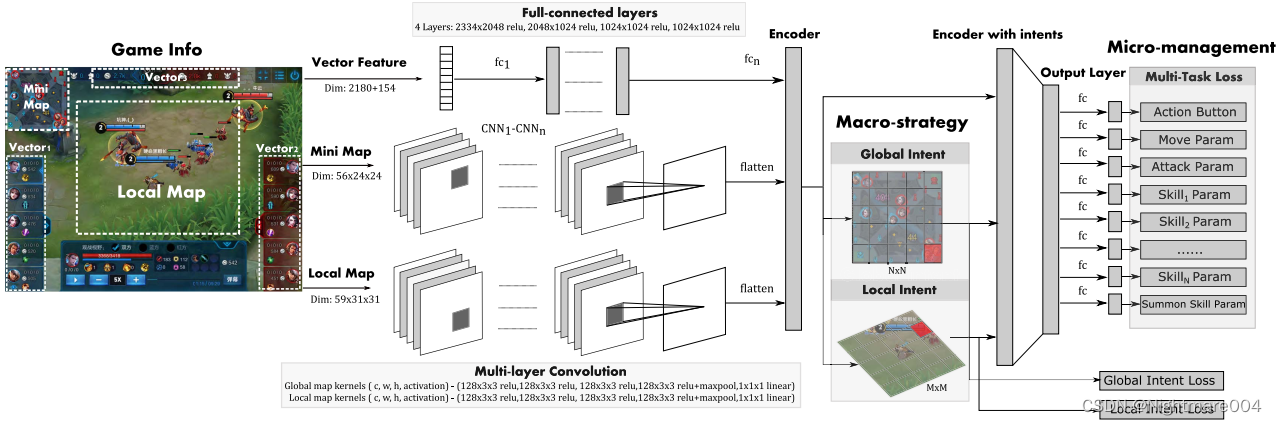
多模态特征
- 向量特征
- 英雄属性
- hp
- 过去帧hp(过去某一帧?过去几帧?)
- 技能冷却
- 伤害属性
- 防御属性
- 经济
- 等级
- buff
- 过去帧位置
- …
- 游戏状态
- 团队击杀差
- 经济差
- 游戏时间
- 塔
- …
- 英雄属性
- 类似图像特征
- 全局类似图像特征
- 能观察到的英雄
- 建筑
- 小兵、野怪
- …
- 局部类似图像特征
- 敌方技能伤害
- 小兵、野怪
- 英雄位置
- …
- 全局类似图像特征
类似图像特征从游戏引擎中提取
全局的从小地图中提取
局部的从英雄局部地图
过去帧的作用(判断敌人目的?
网络结构
一个英雄一个模型
数据集
{
(
x
i
,
y
i
)
:
i
=
1
,
⋯
,
n
}
\left\{ \left( x_{i},y_{i} \right) : i=1,\cdots, n \right\}
{(xi,yi):i=1,⋯,n}从过去的游戏中提取
每个实例
(
x
i
,
y
i
)
\left( x_{i},y_{i} \right)
(xi,yi)从当前和过去帧提取
(数据集由一堆帧的信息构成?)
特征
x
i
=
{
x
i
v
,
x
i
g
,
x
i
l
}
x_{i}=\left\{ x_{i}^{v},x_{i}^{g}, x_{i}^{l} \right\}
xi={xiv,xig,xil}
标签
y
i
=
(
y
a
i
0
,
y
a
i
1
,
y
b
i
g
,
y
b
i
l
)
y_{i}=\left( y_{ai}^{0},y_{ai}^{1}, y_{bi}^{g},y_{bi}^{l} \right)
yi=(yai0,yai1,ybig,ybil)
y
a
i
0
∈
{
1
,
⋯
,
m
}
y_{ai}^{0}\in \left\{ 1,\cdots, m \right\}
yai0∈{1,⋯,m}和
y
a
i
1
y_{ai}^{1}
yai1是一级动作标签和二级动作标签,
m
m
m表示1级动作数量
全局目的和局部目的
p
m
+
1
=
e
g
(
[
h
l
(
x
l
;
ψ
l
)
,
h
g
(
x
g
;
ψ
g
)
]
;
ϕ
g
)
p
m
+
2
=
e
g
(
[
h
l
(
x
l
;
ψ
l
)
,
h
g
(
x
g
;
ψ
g
)
]
;
ϕ
l
)
\begin{aligned} p^{m+1} &= e_{g}\left( \left[ h_{l}\left( x^{l};\psi_{l} \right), h_{g}\left( x^{g};\psi_{g} \right) \right] ;\phi_{g} \right) \\ p^{m+2} &= e_{g}\left( \left[ h_{l}\left( x^{l};\psi_{l} \right), h_{g}\left( x^{g};\psi_{g} \right) \right] ;\phi_{l} \right) \end{aligned}
pm+1pm+2=eg([hl(xl;ψl),hg(xg;ψg)];ϕg)=eg([hl(xl;ψl),hg(xg;ψg)];ϕl)
向量特征:
分成11个部分,分别过FC然后再合并(但是你看网络图,是直接过fc的)
h
(
x
)
=
h
m
(
[
h
v
(
x
v
;
ψ
v
)
,
h
g
(
x
g
;
ψ
g
)
,
h
l
(
x
l
;
ψ
l
)
,
p
m
+
1
,
p
m
+
2
]
;
μ
)
h\left( x \right) =h_{m}\left( \left[ h_{v}\left( x^{v};\psi_{v} \right),h_{g}\left( x^{g};\psi_{g} \right), h_{l}\left( x^{l};\psi_{l} \right) ,p^{m+1},p^{m+2} \right];\mu \right)
h(x)=hm([hv(xv;ψv),hg(xg;ψg),hl(xl;ψl),pm+1,pm+2];μ)
m
+
1
m+1
m+1个函数
{
f
i
(
⋅
;
ω
i
)
:
i
=
0
,
⋯
,
m
}
\left\{ f^{i}\left( \cdot;\omega_{i} \right): i=0,\cdots,m \right\}
{fi(⋅;ωi):i=0,⋯,m}
p
=
(
p
0
,
⋯
,
p
(
m
+
2
)
)
p=\left( p^{0},\cdots,p^{\left( m+2 \right)} \right)
p=(p0,⋯,p(m+2))
p
i
=
f
i
(
h
(
x
)
;
ω
i
)
,
i
=
0
,
⋯
,
m
p^i=f^{i}\left( h\left( x \right);\omega_{i} \right), i=0,\cdots, m
pi=fi(h(x);ωi),i=0,⋯,m
目测
p
0
p^{0}
p0是
m
+
1
m+1
m+1维向量,每个代表动作概率
目测
p
i
p^i
pi是每个目标的概率(动态的?召唤物?方向?)
损失:
l
(
p
,
y
)
=
w
a
0
l
C
E
(
p
0
,
y
a
0
)
+
w
a
1
l
C
E
(
p
y
a
0
,
y
a
1
)
+
w
b
g
l
C
E
(
p
m
+
1
,
y
b
g
)
+
w
b
l
l
C
E
(
p
m
+
2
,
y
b
l
)
l \left( p,y \right) =w_{a 0} l_{CE}\left( p^{0},y_{a}^{0} \right)+w_{a 1} l_{CE}\left( p^{y_{a}^{0}}, y_{a}^{1} \right) +w_{bg}l_{CE}\left( p^{m+1},y_{b}^g \right) +w_{bl}l_{CE}\left( p^{m+2}, y_{b}^{l} \right)
l(p,y)=wa0lCE(p0,ya0)+wa1lCE(pya0,ya1)+wbglCE(pm+1,ybg)+wbllCE(pm+2,ybl)
整体损失
min
θ
∑
i
=
1
n
l
(
p
i
,
y
i
)
+
λ
∥
θ
∥
2
2
\min_{\theta} \sum_{i=1}^{n} l \left( p_{i},y_{i} \right) +\lambda \|\theta \|_{2}^2
θmini=1∑nl(pi,yi)+λ∥θ∥22
预处理
场景识别
- 推塔
- 战斗
- 刷兵
- 刷野
- 回城
- 导航(移动)
每个场景下的数据调整
这种细分使特定英雄再每个场景中打法保持相似,从而方便调整英雄再每个场景中的表现。
例如在导航中,不要漫无目的放技能、战斗中应该重点放技能和攻击,并且走位躲技能
跨场景数据调整
场景比例不平衡(毕竟你也不能一直回城把
根据英雄进行下采样
移动样本增强
因为移动很重要
玩家的走位方向通常随机或者无效,因此不能只用单帧来计算
我们用后
N
N
N帧来确定
在战斗中
N
N
N比较小(因为要细致走位)
其他场景可以粗略
攻击采样归一化
在战斗和推塔场景中,目标选择很重要
在原始数据集中,攻击目标不均衡(高伤低血(HDLH)和低伤高血(LDHH))
攻击LDHH的更多(谁近打谁),但是正常来说应该先打HDLH(切c位)
也是通过采样进行均衡
实验
实验设置
数据集
从前1%的玩家对局中进行采样。采样包括特征、标签、标签权重、帧数…
通过英雄、游戏等级(段位)、红蓝方、表现分数(KDA)、时间来筛选
通过KDA来过滤表现不佳的对局,实验中设置为超过90%实用该英雄的KDA
经过预处理,平均只留下
1
20
\frac{1}{20}
201帧
12万局游戏得到1亿个样本
模型设置
向量特征有2334个特征,其中2180为10个英雄,154个为玩家英雄
局部视野:以英雄为中心,30000长度,然后分成
31
∗
31
31*31
31∗31个格子,目的是每个格子和英雄大小(100)差不多
局部类似图像特征维度
59
∗
31
∗
31
59*31*31
59∗31∗31
小地图分为
24
∗
24
24*24
24∗24个格子(边长113000)
全局类似图像土整维度
56
∗
24
∗
24
56*24*24
56∗24∗24
一个模型训练个英雄。每个英雄在16G P40上大约36h
王者荣耀中,一帧66.7ms(15帧/s)
AI总反应时间188ms,133ms(两帧)观察,55ms反应
评价指标
- 和其他模型的比分
- 5AI vs 5人
- AI+人队友
实验结果
和其他模型
打了100局
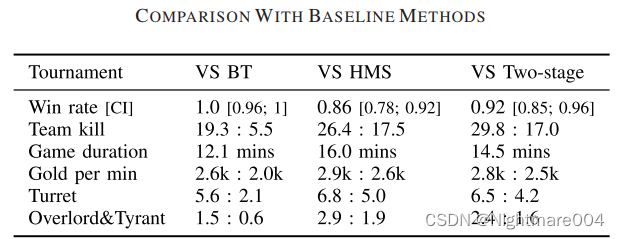
5AI
80星王者
其中输了两把是因为入侵野区+中团推塔
调整:1)将野区划分成自家野区2)过滤在自家野区战斗的场景3)微调
调整后(训了5天接着打是吧),都是赢
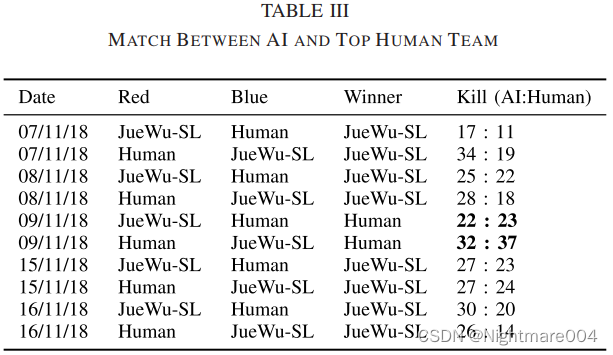
AI经过学习,能学会掩护、蹲草丛等战术
AI+人
1AI+4王者 vs 5王者
配合很好,例如貂蝉40局70%胜率,30%伤害占比
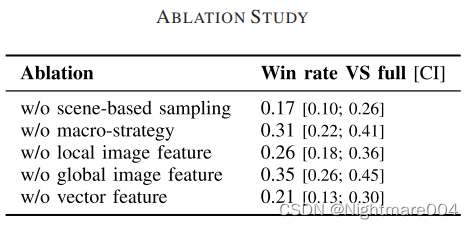
消融
100局
实验表明向量特征和基于场景采样比较重要
讨论
尽管训练集来自前1%玩家,但是训练完了玩的比他好
相比于RL,SL优势
1)快速成型。RL训练时间长,占用资源大
2)SL可以一个个英雄训练。RL,经典方法是自我对战
3)玩的像人
SL缺点:要高质量人类数据,RL上限高
结论和未来工作
将要采取的动作定义为层级多分类问题。
通过意图和动作标签,利用神经网络,从经验丰富的人类数据中捕捉moba的宏观战略和微观管理。
第一次监督AI能达到顶级人类水准


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











