







目录
引言
我们最新的工作 TransRank 在今年的 CVPR 中以 Oral Presentation 被接收。这项工作主要回顾了基于识别数据增强类型(Recognizing Transformation)的自监督学习方法,并提出了 TransRank 框架,通过使用排序损失替代传统的交叉熵损失进行训练以提升自监督学习的性能,并最终证明 RecogTrans 自监督学习方法依然具有可观的潜力。
TransRank 框架可以兼容多种不同的 RecogTrans 任务,并且在多项包含 recognition 和 retrieval 的下游任务上都取得了优秀的效果,较之前的 RecogTrans 方法取得了较大提升,并拥有与基于实例区分(InstDisc)的自监督学习方法近似的性能。
Paper:https://arxiv.org/abs/2205.02028
什么是 RecogTrans 自监督学习方法?
Recognizing Transformation 是自监督学习领域中的一大类方法,这些方法设计了一种 pretext task 并在 pretext task 上训练以进行表征学习。这类 pretext task 通常对输入的图片、视频进行不同种类的 Transformation,并训练网络以识别施加 Transformation 的种类。在视频自监督学习领域,RecogTrans 方法中具有代表性的 pretext task 主要分为以下两类。
- Spatial Task:人为改变视频的旋转朝向 [1]、长宽比例 [2] 等,并对施加的改变进行预测。 下图(图片来自 [1])展示了以预测视频旋转朝向作为 pretext task 的训练过程。

- Temporal Task:人为改变视频的播放速度、模式,并对其进行识别,这类方法在视频自监督学习中使用较多。AoT [3] 使用 RGB、光流等模态识别一段视频是正放还是倒放;SpeedNet [4] 训练网络判断视频为单倍速还是两倍速播放;RTT [5] 除去不同播放倍速以外,还在 Transformation 中加入了 random、 periodic、warp 等播放模式。此外,也有尝试将识别播放倍速这一 pretext task 与 InstDisc 方法相结合([6])。
下图(图片来自 [5])展示了基于识别 Temporal Transformation 进行视频自监督学习的过程,这里的 Temporal Transformation 包含了不同的播放倍速以及 random、 periodic、 warp 等播放模式。
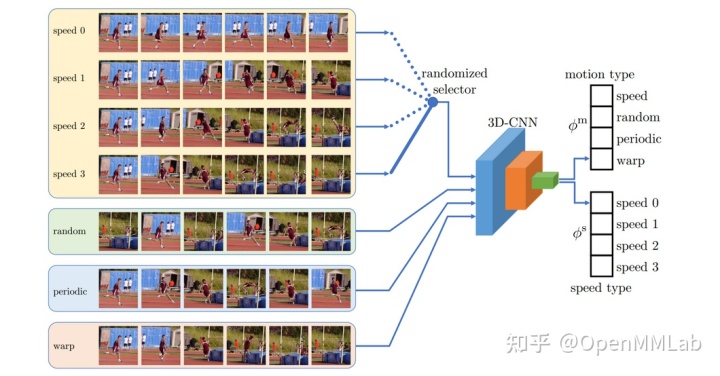
RecogTrans 方法具有可观的潜力
在过去呈现的一些结果中,RecogTrans 自监督学习方法通常距离 InstDisc 自监督学习方法有较大的 performance gap。我们首先进行了一系列初步实验,以了解这两大类方法的特点。
在实验中,我们分别选取了 RecogTrans 中的 SpeedNet [4](mporal RecogTrans)、3D-RotNet [1] 算法,InstDisc 中的 MoCo [7] (InstDisc)、SimSiam [8] (InstDisc)算法, 并使用统一的 backbone (R3D-18) 在 MiniKinetics [9] 统一进行了 200 Epoch 的预训练。我们使用以下三种下游任务来评估学到的自监督表征:
- Retrieval: 直接使用学到的表征,以每个测试集视频作为 query,在训练集中寻找最近邻,并报告不同 top-k 下 的 recall。
- Classification:使用预训练得到的模型参数作为初始化,在下游分类数据集上重新训练,可以选择冻结或不冻结 backbone 参数 (linear probe / finetune)。
- Temporal Related Tasks:除去传统的 retrieval 和 classification,我们还参照过去的工作 [5],测试了三种 temporal related tasks:1. 判断视频中 Motion 的种类(Motion); 2. 判断两个来源于同一视频的重叠 clip 的重叠模式(Sync);3. 判断两个来源于同一视频的不重叠 clip 的先后顺序 (Order)。
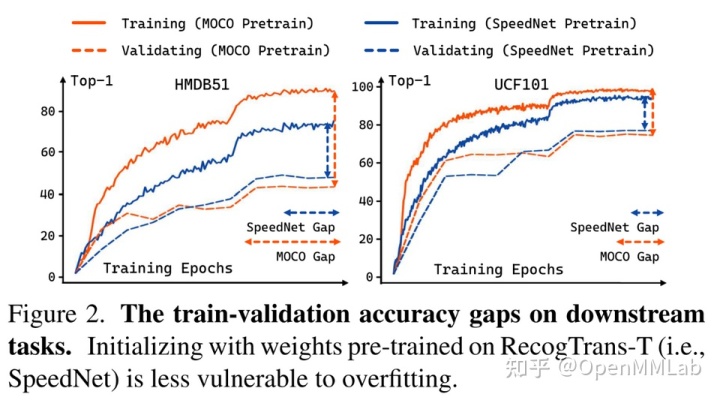
下表展示了不同表征在 Retrieval 和 Classification 两种任务上的性能。得益于 Contrastive Pretraining, MoCo 在 Retrieval 和 Linear Probe 上都取得了最好的性能。然而,在 finetune 过后,SpeedNet 能快速 adapt 到分类任务上,能取得比其他方法更好的性能。

同时,从下图可以看出:相比 MoCo,基于 RecogTrans 的 SpeedNet 在 finetune 过程中更不易 overfit。
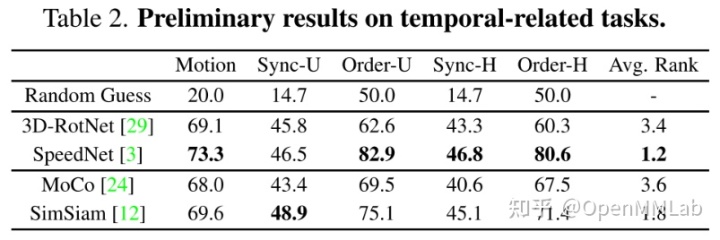
不仅如此,SpeedNet 在三种不同的下游 Temporal Related Tasks 上也有着更好的性能,如下表所示:
基于 Ranking Loss 的 RecogTrans
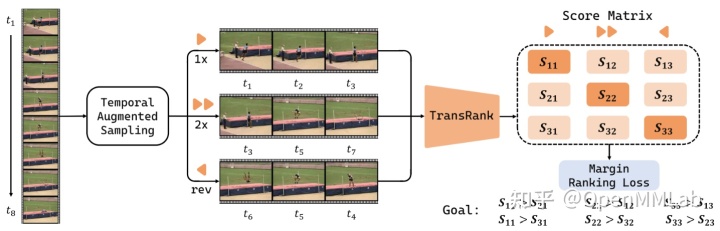
在说明 Ranking Loss 的优势之前,我们先来看下图这个例子。图中 3 个 clip 使用了 2 种不同的 Temporal Transformation:单倍速播放(1x)和二倍速播放(2x)。在两对 clip (A, B)、 (B, C)中,每对 clip 分别使用了两种 Transformation 中的一个。

在上面这张图中,A、 C 两个 clip 使用的是 1x 播放,而 B 使用的是 2x 播放。但显然,A 中人物的奔跑速度要远快 B。这时,如果仍然使用 hard classification,将 A 分类为 1x,B 分类为 2x 就显得不合情理。相反,使用 Ranking Loss 的情况下,我们只需要预测出 B 的播放速度比 C 更快即可,而不会涉及到 A 和 B 的比较。这样的损失函数无疑更加合理。
下图展示了使用 Ranking Loss 的 TransRank 框架架构。在这个例子中,我们从一个视频中 sample 了 3 个 clip,分别施加了 1x、 2x, 倒放 3 种 Transformation。对每个 clip, TransRank 预测 3 个 score,分别对应 3 种 Transformation。我们对于这 3x3 个 score 计算 Margin Ranking Loss。简单来说:由于 clip 2 (
) 使用了 2x Transformation (这个组合对应 score ), 因此 Ranking Loss 要求
大于其他 clip 的 2x Transformation score (即
)。
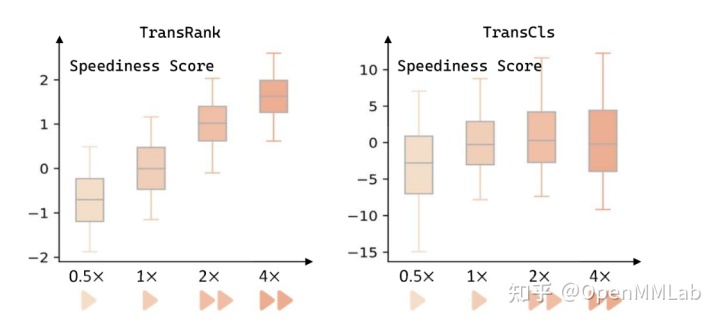
通过一个 Toy Example,我们可以展示基于 Ranking Loss 训练得到的表征相比基于 Cross Entropy Loss 训练(TransCls)得到的表征具有更好的性质。我们在训练时使用 1x、2x 两种 Transformation,并定义 score[2x] - score[1x] 为 speediness score (越大,播放速度越快)。我们使用训好的模型在 0.5x、4x 两种未曾见过的 Transformation 上预测 speediness score。从下图容易看出:TransRank 预测出的 speediness score 分布符合应有的趋势,而 TransCls 未能做到这一点。
应用 TransRank 的实践
在实际应用 TransRank 的过程中,我们总结出了以下的经验。
1.如何选择 Temporal Transformation 类型:选择 Temporal Transformation 时,为防止模型学习过程中走捷径,需要尽可能使选择的 Transformation 不能仅通过几帧就能识别出来。我们在实验中验证了,加入 shuffle、palindrome 等通过少量帧就能识别的 Transformation,无法提升表征学习的效果。
2.Spatial Transformation:TransRank 框架也兼容 Spatial Transformation,在实验中,我们还在预训练阶段加入了 Estimate Aspect Ratio、Estimate Rotation 一类的 Spatial Task。
3.数据增强:TransRank 需要大量数据增强以达到较好的性能。在实验中,我们使用了较强的 Temporal Augmentation 和 Spatial Augmentation,这些 Augmentation 均为 clip-wise,即同视频中不同 clip 使用的 Augmentation 不同。Temporal Augmentation 指在进行倍速播放的时候,对倍速进行 0.8x - 1.2x 的扰动。Spatial Augmentation 包括 RandomResizedCrop、RandomGrayScale、RandomColorJitter 等多种数据增强。
4.Finetune 阶段时,如使用 TransRank 预训练模型进行初始化的话,则需要更大的 Learning Rate。如下图所示, 使用不同初始 LR 进行模型 finetune,对 TransRank 而言,使用更大的 Finetune LR 尤为重要 (x-axis:LR;y-axis:Top-1 Accuracy),但对 MoCo 影响并不大。

5.在预训练阶段,可以使用 MLP Layer 代替单独的 FC Head 进行 score 预测,这样并不会对 Finetune Performance 带来影响,但可以大幅提升 Retrieval Performance。
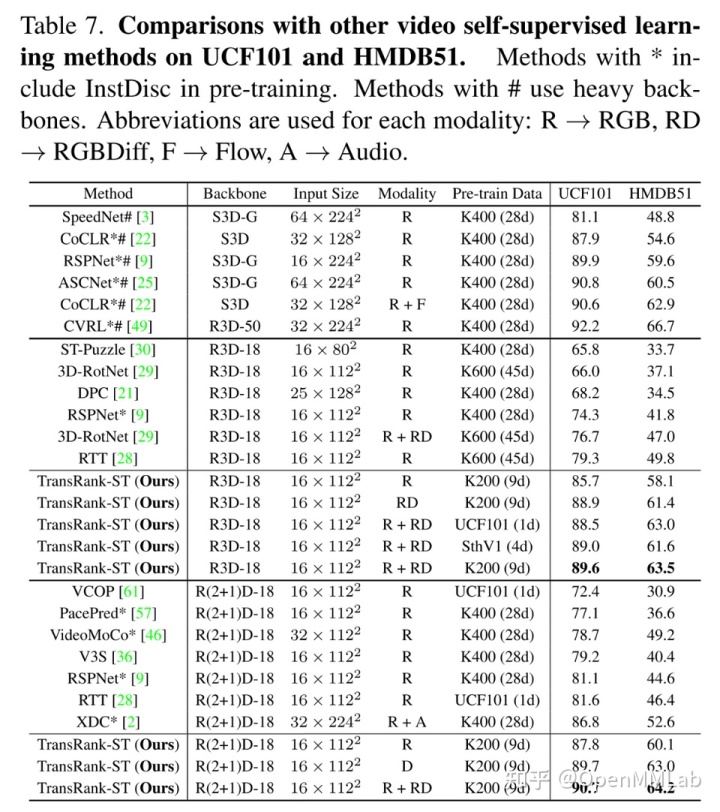
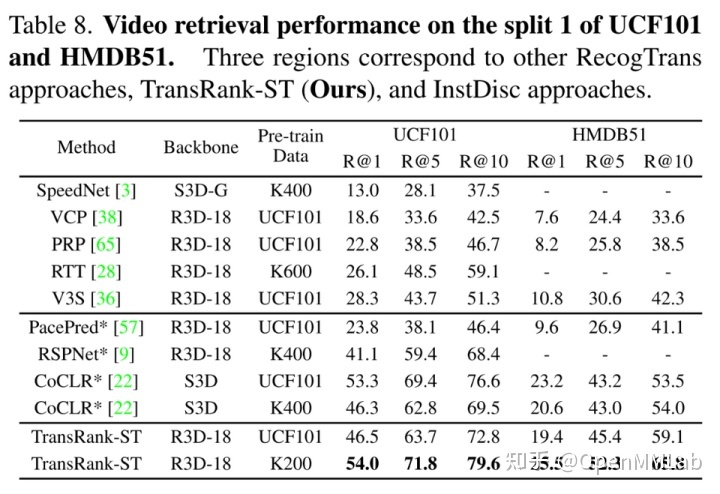
得益于以上这些良好的实践,TransRank 在 Classification 和 Retrieval 两个下游任务上大幅超越了原有的 RecogTrans 方法,能取得和 InstDisc 方法相似的性能(如下面两张表所示)。
Classification Performance
Video Retrieval Performance
这样的结果证明了基于 RecogTrans 的自监督学习方法依然具有较大的潜力可以挖掘。
Reference
[1] Self-Supervised Spatiotemporal Feature Learning via Video Rotation Prediction
[2] Video 3d sampling for self-supervised representation learning
[3] Learning and using the arrow of time
[4] Speednet: Learning the speediness in videos
[5] Video representation learning by recognizing temporal transformations
[6] Self-supervised video representation learning by pace prediction
[7] Momentum contrast for unsupervised visual representation learning
[8] Exploring simple siamese representation learning
[9] Rethinking spatiotemporal feature learning for video understanding















 2500
2500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









