







在 2024 年 7 月 4 日的 WAIC 科学前沿主论坛上,上海人工智能实验室推出了书生·浦语系列模型的全新版本——InternLM2.5。相较于上一代,InternLM2.5 全面增强了在复杂场景下的推理能力,支持 1M 超长上下文,能自主进行互联网搜索并从上百个网页中完成信息整合。
此前,面向广泛应用场景的轻量级 InternLM2.5-7B 已开源。为适应更多样化应用场景及不同开发者需求,InternLM2.5 再次开源 1.8B、20B 参数版本。
-
InternLM2.5-1.8B :性能优越的超轻量级模型,兼具高质量和高适应灵活性。
-
InternLM2.5-20B :综合性能更为强劲,可以有效支持更加复杂的实用场景。
三种不同尺寸的 InternLM2.5 模型现已全部开源,快速体验链接:
书生·浦语系列大模型主页:
https://internlm.intern-ai.org.cn
Hugging Face 主页:
https://huggingface.co/internlm
ModelScope 主页:
InternLM2.5 开源链接:
GitHub - InternLM/InternLM: Official release of InternLM2.5 base and chat models. 1M context support
InternLM2.5 亮点
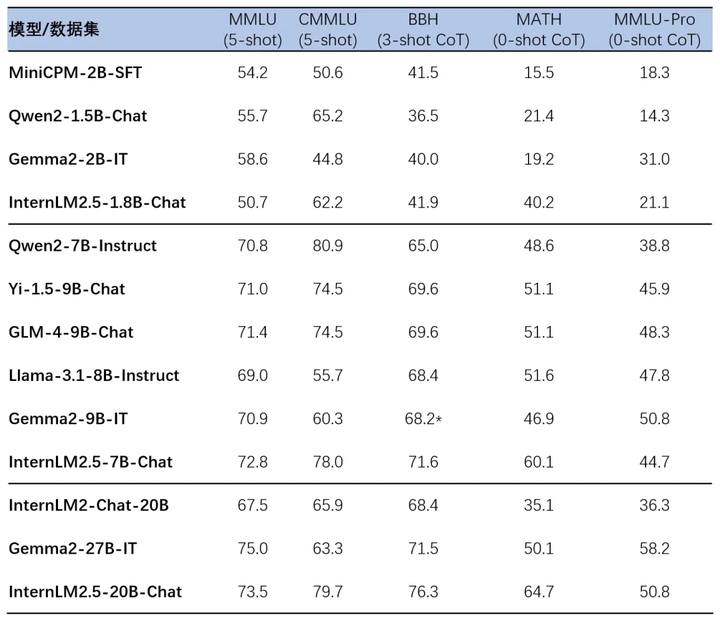
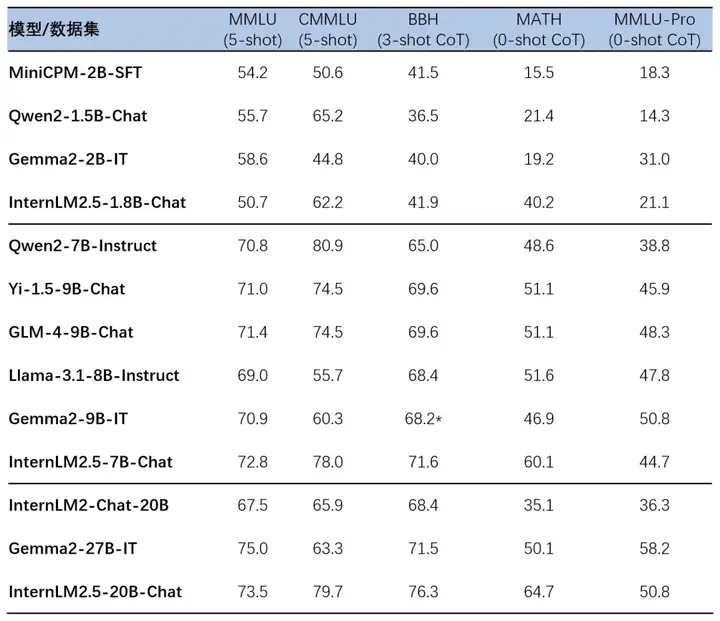
InternLM2.5 采用了多种数据合成技术并进行了多轮迭代,每次迭代均基于当前领先模型构建的多智能体进行数据筛选、扩增和优化,实现了复杂场景下模型推理能力的全面增强,尤其是在由竞赛问题构成的数学评测集 MATH 上,InternLM2.5-20B 模型成绩相较上一代提升近 1 倍,达到了 64.7% 的准确率。
面向长文档理解和复杂的智能体交互等依赖上文本处理能力的应用场景,为了进一步释放了模型在超长文本应用上的潜力,InternLM2.5 通过在预训练阶段进行 256K Token 长度的高效训练,将上下文长度从上一代模型InternLM2 的 200K 提升到了 1M(约合 120 万汉字)。
为了解决大规模复杂信息的搜索和整合,InternLM2.5 在微调阶段学习了人的思维过程,能够接入团队提出的 MindSearch 多智能体框架,引入了任务规划、任务拆解、大规模网页搜索、多源信息归纳总结等步骤,有效地整合网络信息,能够基于上百个网页的信息进行筛选、浏览和整合。
推理能力领先
通用人工智能的发展依赖强大的推理能力,InternLM2.5 系列聚焦推理能力进行优化,为大模型在复杂场景的应用落地提供了良好的基础。
基于司南 OpenCompass 开源评测框架,研究团队使用统一可复现的评测方法在多个推理能力权威评测集上进行了评测。相比上一代模型,InternLM2.5 在多个推理能力权威评测集上实现了大幅性能提升,特别是在由竞赛问题构成的数学评测集 MATH 上,InternLM2.5 成绩提升近 1 倍,以 20B 参数达到了 64.7% 的准确率,对比其他同量级开源模型,也表现出较强的竞争力。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
应用体验
多步复杂推理不在话下

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
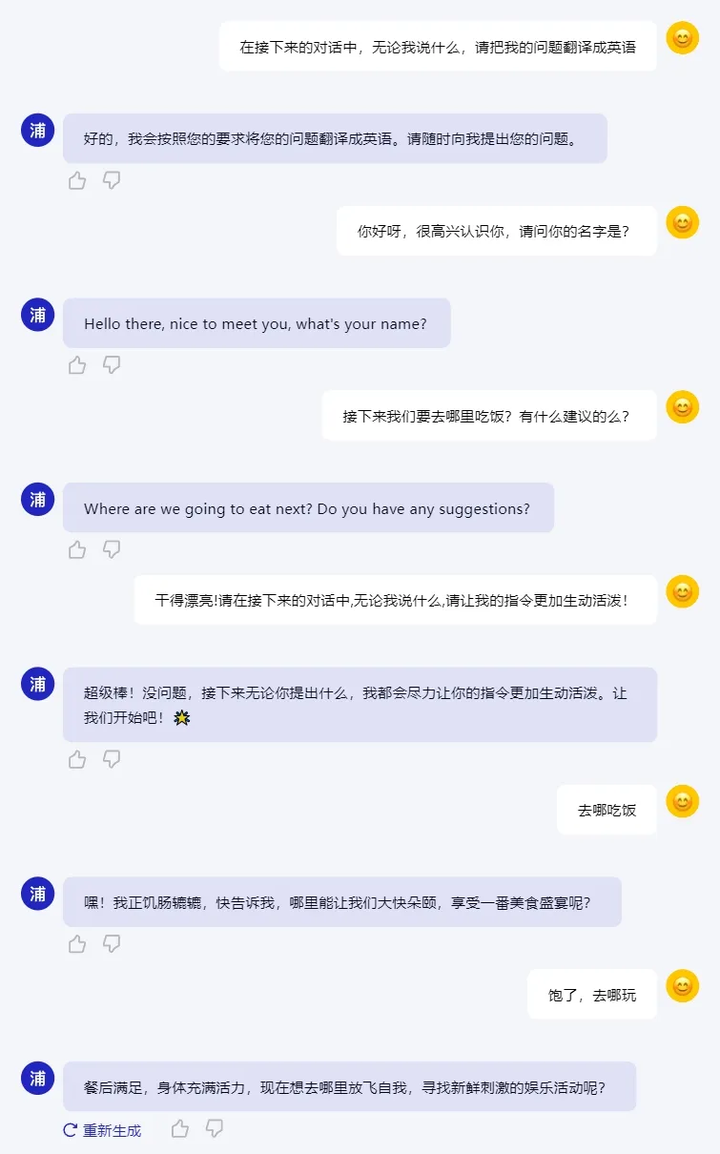
多轮对话意图精准理解
添加图片注释,不超过 140 字(可选)
灵活的格式控制和操作

添加图片注释,不超过 140 字(可选)
遵循复杂指令

添加图片注释,不超过 140 字(可选)
推理和微调快速上手
InternLM2.5 系列模型实现了与下游推理和微调框架的无缝对接,涵盖了上海人工智能实验室自主研发的高性能大语言模型(LLM)微调框架 XTuner、推理框架 LMDeploy,以及在社区中拥有广泛用户基础的 vLLM、Ollama 和 llama.cpp 等等。
以下以 20B 模型为例,分别介绍使用 XTuner 微调模型的方式,以及使用 LMDeploy、vLLM 和 Ollama 搭建模型服务的方法。
XTuner
pip install -U 'xtuner[deepspeed]>=0.1.23'
# 单卡 QLoRA 微调,24GB 显存
xtuner train internlm2_5_chat_20b_qlora_alpaca_e3 --deepspeed deepspeed_zero1
# 8 卡全量微调
NPROC_PER_NODE=8 xtuner train internlm2_5_chat_20b_alpaca_e3 --deepspeed deepspeed_zero3LMDeploy
pip install lmdeploy
lmdeploy server api_server internlm/internlm2_5-20b-chat --server-port 8000vLLM
pip install vllm
python -m vllm.entrypoints.openai.api_server internlm/internlm2_5-20b-chat --dtype auto --port 8000 --trust-remote-codeOllama
# 安装 ollama
curl -fsSL https://ollama.com/install.sh | sh
# 下载模型
ollama pull internlm/internlm2.5:20b-chat
# 运行
ollama run internlm/internlm2.5:20b-chat
# 开启服务(另起一个终端)
OLLAMA_HOST=0.0.0.0:8000 ollama serveLMDeploy、vLLM 和 Ollama 搭建的推理服务,其接口兼容 OpenAI 的服务接口。所以,可以使用 OpenAI 接口访问推理服务,方式如下:
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY', # required but unused
base_url="http://0.0.0.0:8000/v1"
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": " provide three suggestions about time management"},
],
temperature=0.8,
top_p=0.8,
max_tokens=100
)
print(response)
















 2075
2075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









