






本文为记性不好的菜鸟的函数用法笔记,大佬请自行绕开~
部分函数说明来自 PyTorch中文文档 。
参考代码
代码链接如下,需要的小伙伴可以自行下载:
GitHub - TeeyoHuang/pix2pix-pytorch: the pytorch version of pix2pix
dataset.py
optimizer.py
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
实现Adam算法。
参数:
params (iterable) : 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) : 学习率(默认:1e-3)
betas (Tuple[float, float], 可选) :用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
eps (float, 可选) : 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) : 权重衰减(L2惩罚)(默认: 0)
class torch.nn.BCELoss(weight=None, size_average=True)
计算 target 与 output 之间的二进制交叉熵。
CLASS torch.nn.L1Loss(size_average=None, reduce=None, reduction=‘mean’)
计算input和target的每个元素的平均绝对误差
损失函数详细参考:pytorch常用损失函数 - 慢行厚积 - 博客园
utils.py
torchvision.utils.save_image(tensor, filename, nrow=8, padding=2, normalize=False, range=None, scale_each=False)
将给定的Tensor保存成image文件。如果给定的是mini-batch tensor,那就用make-grid做成雪碧图,再保存。
参数:
若normalize=True ,会将图片的像素值归一化处理。
如果 range=(min, max), min和max是数字,那么min,max用来规范化image。
若scale_each=True ,每个图片独立规范化,而不是根据所有图片的像素最大最小值来规范化。
torch.cat(inputs, dimension=0) → Tensor
在给定维度上对输入的张量序列seq 进行连接操作。
torch.cat()可以看做 torch.split() 和 torch.chunk()的反操作。
参数:
inputs (sequence of Tensors) : 可以是任意相同Tensor 类型的python 序列
dimension (int, optional) :沿着此维连接张量序列。
例子:
>>> x = torch.randn(2, 3)
>>> x
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 2x3]
>>> torch.cat((x, x, x), 0)
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 6x3]
>>> torch.cat((x, x, x), 1)
0.5983 -0.0341 2.4918 0.5983 -0.0341 2.4918 0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735 1.5981 -0.5265 -0.8735 1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 2x9]
models.py
torch.nn.init.normal(tensor, mean=0, std=1)
从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量.
参数:
tensor : n维的torch.Tensor
mean : 正态分布的均值
std : 正态分布的标准差
torch.nn.init.constant(tensor, val)
用val的值填充输入的张量或变量
参数:
tensor – n维的torch.Tensor或autograd.Variable
val – 用来填充张量的值
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
instanceNorm在图像像素上,对HW做归一化,用在风格化迁移。可以加速模型收敛,并且保持每个图像实例之间的独立。
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
计算公式见以下参考链接:
PyTorch学习之归一化层(BatchNorm、LayerNorm、InstanceNorm、GroupNorm)_人工智能_mingo_敏-CSDN博客
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结_人工智能_I am what i am-CSDN博客
class torch.nn.Sequential(* args)
一个时序容器。Modules 会以他们传入的顺序被添加到容器中。当然,也可以传入一个OrderedDict。
为了更容易的理解如何使用Sequential, 下面给出一个例子:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
modules()
返回一个包含 当前模型 所有模块的迭代器。
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv", nn.Conv2d(10, 20, 4))
self.add_module("conv1", nn.Conv2d(20 ,10, 4))
model = Model()
for module in model.modules():
print(module)
打印输出:
Model (
(conv): Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
(conv1): Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
)
Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
class torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True)
2维的转置卷积操作(transposed convolution operator,注意改视作操作可视作解卷积操作,但并不是真正的解卷积操作) 该模块可以看作是Conv2d相对于其输入的梯度,有时(但不正确地)被称为解卷积操作。
说明
stride: 控制相关系数的计算步长
dilation: 用于控制内核点之间的距离
groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
参数kernel_size,stride,padding,dilation数据类型: 可以是一个int类型的数据,此时卷积height和width值相同; 也可以是一个tuple数组(包含来两个int类型的数据),第一个int数据表示height的数值,第二个int类型的数据表示width的数值
参数:
in_channels(int) – 输入信号的通道数
out_channels(int) – 卷积产生的通道数
kerner_size(int or tuple) - 卷积核的大小
stride(int or tuple,optional) - 卷积步长
padding(int or tuple, optional) - 输入的每一条边补充0的层数
output_padding(int or tuple, optional) - 输出的每一条边补充0的层数
dilation(int or tuple, optional) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,H_in,W_in)
输出: (N,C_out,H_out,W_out)
H
o
u
t
=
(
H
i
n
−
1
)
s
t
r
i
d
e
[
0
]
−
2
p
a
d
d
i
n
g
[
0
]
+
k
e
r
n
e
l
s
i
z
e
[
0
]
+
o
u
t
p
u
t
p
a
d
d
i
n
g
[
0
]
H_{out}=(H_{in}-1)stride[0]-2padding[0]+kernel_size[0]+output_padding[0]
Hout=(Hin−1)stride[0]−2padding[0]+kernelsize[0]+outputpadding[0]
W
o
u
t
=
(
W
i
n
−
1
)
s
t
r
i
d
e
[
1
]
−
2
p
a
d
d
i
n
g
[
1
]
+
k
e
r
n
e
l
s
i
z
e
[
1
]
+
o
u
t
p
u
t
p
a
d
d
i
n
g
[
1
]
W_{out}=(W_{in}-1)stride[1]-2padding[1]+kernel_size[1]+output_padding[1]
Wout=(Win−1)stride[1]−2padding[1]+kernelsize[1]+outputpadding[1]
变量:
- weight(tensor) - 卷积的权重,大小是(in_channels, in_channels,kernel_size)
- bias(tensor) - 卷积的偏置系数,大小是(out_channel)
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)的计算方式:
o
u
t
(
N
i
,
C
o
u
t
j
)
=
b
i
a
s
(
C
o
u
t
j
)
+
∑
k
=
0
C
i
n
−
1
w
e
i
g
h
t
(
C
o
u
t
j
,
k
)
⨂
i
n
p
u
t
(
N
i
,
k
)
out(N_i, C_{out_j})=bias(C_{out_j})+\sum^{C_{in}-1}_{k=0}weight(C{out_j},k)\bigotimes input(N_i,k)
out(Ni,Coutj)=bias(Coutj)+k=0∑Cin−1weight(Coutj,k)⨂input(Ni,k)
说明
bigotimes: 表示二维的相关系数计算 stride: 控制相关系数的计算步长
dilation: 用于控制内核点之间的距离,详细描述在这里
groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
参数kernel_size,stride,padding,dilation也可以是一个int的数据,此时卷积height和width值相同;也可以是一个tuple数组,tuple的第一维度表示height的数值,tuple的第二维度表示width的数值
参数:
in_channels(int) – 输入信号的通道
out_channels(int) – 卷积产生的通道
kerner_size(int or tuple) - 卷积核的尺寸
stride(int or tuple, optional) - 卷积步长
padding(int or tuple, optional) - 输入的每一条边补充0的层数
dilation(int or tuple, optional) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
shape:
input: (N,C_in,H_in,W_in)
output: (N,C_out,H_out,W_out)
H
o
u
t
=
f
l
o
o
r
(
(
H
i
n
+
2
p
a
d
d
i
n
g
[
0
]
−
d
i
l
a
t
i
o
n
[
0
]
(
k
e
r
n
e
r
l
s
i
z
e
[
0
]
−
1
)
−
1
)
/
s
t
r
i
d
e
[
0
]
+
1
)
H_{out}=floor((H_{in}+2padding[0]-dilation[0](kernerl_size[0]-1)-1)/stride[0]+1)
Hout=floor((Hin+2padding[0]−dilation[0](kernerlsize[0]−1)−1)/stride[0]+1)
W o u t = f l o o r ( ( W i n + 2 p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] ( k e r n e r l s i z e [ 1 ] − 1 ) − 1 ) / s t r i d e [ 1 ] + 1 ) W_{out}=floor((W_{in}+2padding[1]-dilation[1](kernerl_size[1]-1)-1)/stride[1]+1) Wout=floor((Win+2padding[1]−dilation[1](kernerlsize[1]−1)−1)/stride[1]+1)
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels,kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
对小批量(mini-batch)3d数据组成的4d输入进行批标准化(Batch Normalization)操作
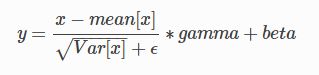
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)
在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证时,训练求得的均值/方差将用于标准化验证数据。
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features x height x width’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
Shape: - 输入:(N, C,H, W) - 输出:(N, C, H, W)(输入输出相同)
pix2pix_train.py
enumerate(sequence, [start=0])
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
参数
sequence – 一个序列、迭代器或其他支持迭代对象。
start – 下标起始位置。
例子:
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
普通的 for 循环
>>>i = 0
>>> seq = ['one', 'two', 'three']
>>> for element in seq:
... print i, seq[i]
... i +=1
...
0 one
1 two
2 three
for 循环使用 enumerate
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 two
2 three
更多详细见参考链接:Python enumerate() 函数 | 菜鸟教程
未完待续














 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









