







场景: 从一张单词表中随机刷选出三个单词
建表语句和存储过程如下:
mysql> CREATE TABLE `words` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=0;
while i<10000 do
insert into words(word) values(concat(char(97+(i div 1000)), char(97+(i % 1000 div 100)), char(97+(i % 100 div 10)), char(97+(i % 10))));
set i=i+1;
end while;
end;;
delimiter ;
call idata();
17.1 内存临时表
rand()函数有两种用法:
- rand():产生0~1之间的随机值。
- rand(整数参数):根据给出的整数参数每次都会给出重复的0~1之间的随机值。

随机得到单词表前三的sql语句:
select * from words order by rand() limit 3;
我们来看下语句的预估情况:

发现如下情况:Extra中显示Using temporary表示要使用临时表;Using filesort表示要数据排序。
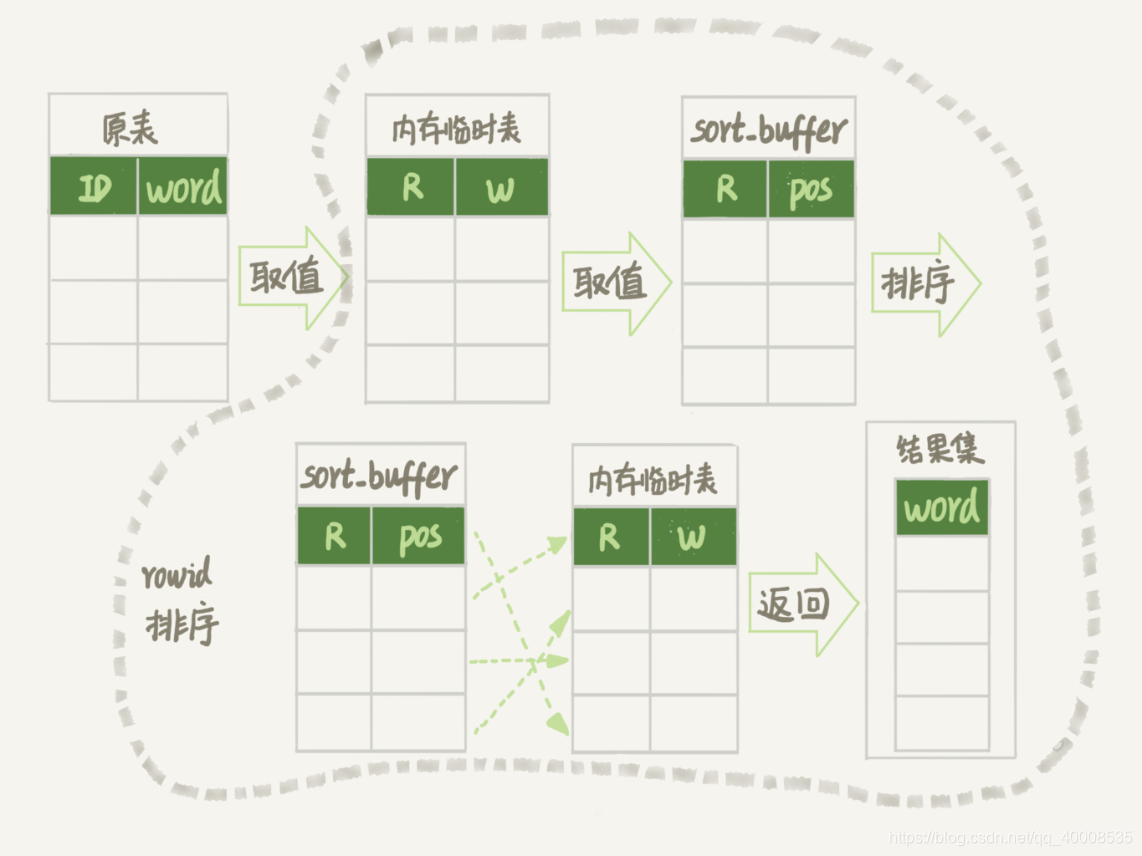
sql执行流程:
- 初始化内存临时表,doble类型字段记作R,varchar(64)类型字段记作W。
- 给单词表的每一个word执行rand(),将计算后的结果和位置信息放入临时表的R和W字段。
- 初始化sort_buffer,确定两个字段,一个是double,一个是整形
- 将临时表中的数据取到,放到sort_buffer中
- sort_buffer根据R值进行排序
- 取前三个位置信息,依次到内存临时表中取得word值并返回。
慢日志开启,关闭与查看,生成的日志在data目录下
# 将慢查询日志的阀值设为0,这样后续的语句都会写入slow_log
set long_query_time=0;
SELECT * from words order by RAND() LIMIT 3;
查看慢查询日志:得出扫描的行数为20003行,步骤2扫描10000行,步骤4扫描10000行,步骤6扫描3行。

示意流程图如下:
位置信息:
MySQL会给没有主键的表,生成一个长度为6字节的rowid,用来表示当前行在表中的位置信息;如果有主键id,则用主键id来表示。
位置信息就是数据库用来确定一行数据位置的方式。
17.2 磁盘临时表
临时表分为内存临时表和磁盘临时表,取决于参数tmp_table_size,默认为16M,如果所需要的内存超过参数指定值,则就回去使用磁盘临时表。
磁盘临时表的默认引擎为InnoDB,由参数 internal_tmp_disk_storage_engine 决定。
OPTIMIZER_TRACE的使用
执行如下sql进行复现:
#
set tmp_table_size=1024;
#
set sort_buffer_size=32768;
# 设置长度小于word的长度,选用rowid排序
set max_length_for_sort_data=16;
# 开启 optimizer_trace
SET optimizer_trace="enabled=on";
SELECT * from words order by RAND() LIMIT 3;
# 查看
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
# 关闭 optimizer_trace
SET optimizer_trace="enabled=off";
查看optimizer_trace:

我们得到如下结果:sort_mode表明使用rowid排序;number_of_tmp_files表明没有使用磁盘临时文件;examined_rows表示扫描行数共计10000行。
sort_buffer_size定义的大小为32768字节,它需要存储的信息有位置信息(4字节/6字节)和word rand()后的值(8字节),无论怎样都会比sort_buffer_size设置的大小会大,但为什么磁盘临时文件使用量显示为0个呢?
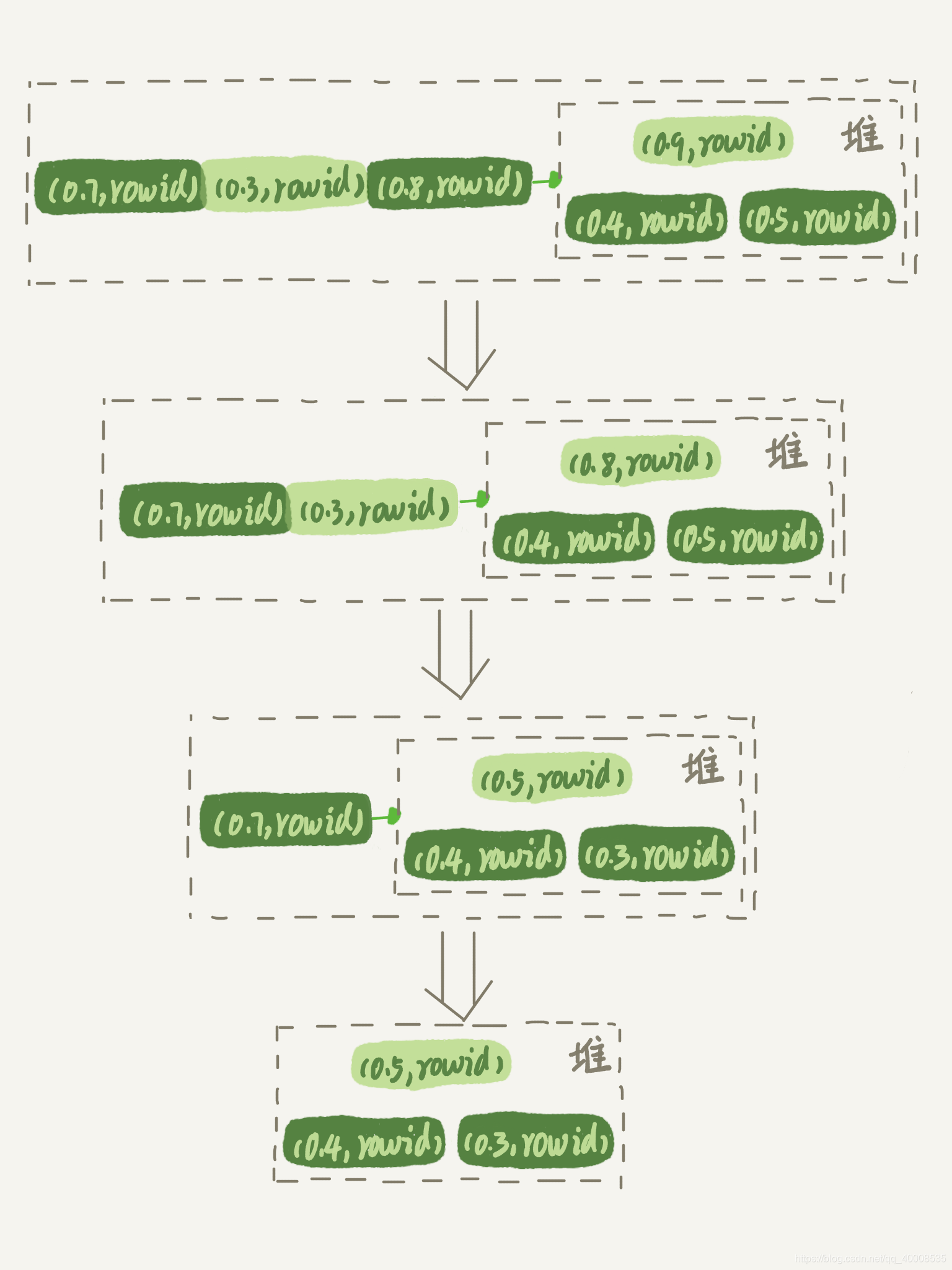
优先队列算法:
这种情况下在sort_buffer中使用最大堆排序算法,因为排序的数据为3个,就不需要用到临时表,对应的就是 number_of_tmp_files 是 0。
我们可以从上面optimizer_trace中file_priority_queue_optimization.chosen = true看出,的确是这样的,但是如果sort_buffer中用堆排序的数据量超出了设定值,也还是会用临时表的,比如 limit 5000;
算法的流程图如下:
17.随机排序算法
第一种:
- 取得主键最大值M和最小N
- 用随机函数在最大值M和最小值N之间生成一个随机数X = (M-N)*rand()+N
- 取表中不小于X的第一行
第二种:
- 取表的行数,记为C
- 计算 Y = floor(C * rand())
- 用limit Y,1来取得一行
第三种: 随机取三个值
- 取表的行数,记为C,
- 同样计算得到Y1,Y2,Y3
- 执行limit Y,1得到三个数据














 3844
3844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









