







(一)CV
CNN中特征图的计算
CNN中卷积层的计算细节 - Michael Yuan的文章 - 知乎
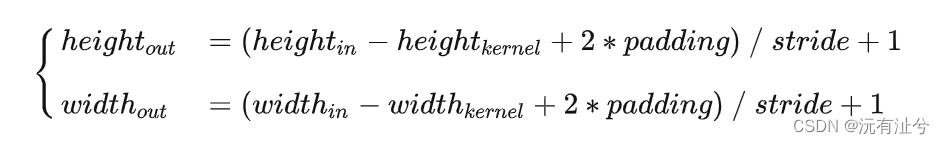
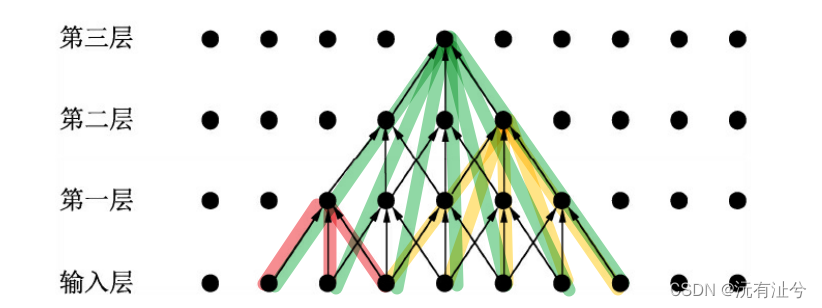
CNN中的感受野含义及计算




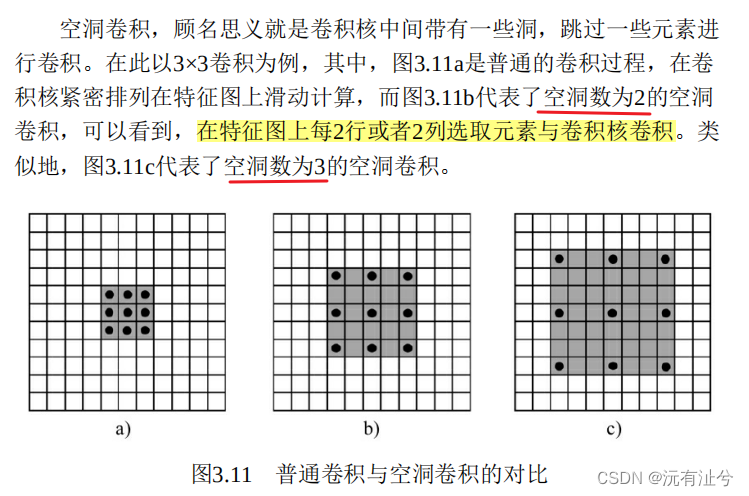
空洞卷积(Dilated Convolution)




CNN中的上采样方法

dropout可以防止过拟合的解释

BN





IoU计算
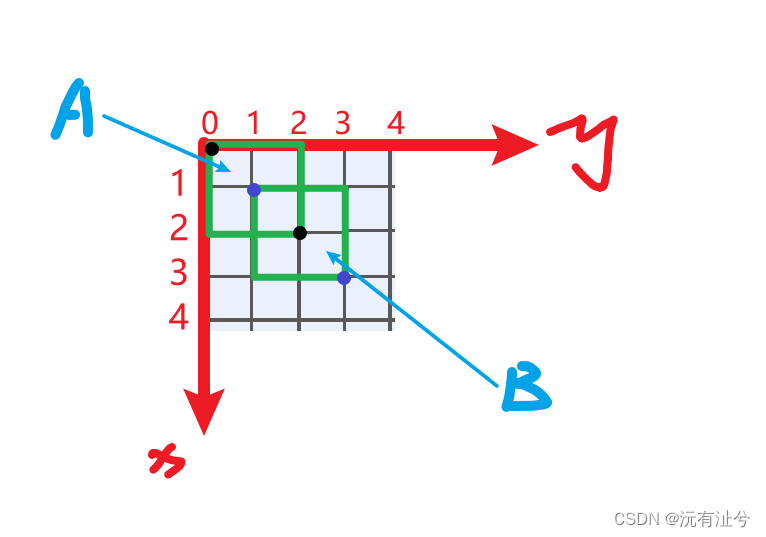
# (x1,y1)(x2,y2)为方框1左上角和右下角坐标
# (a1,b1)(a2,b2)为方框2左上角和右下角坐标
def getIoU(x1, y1, x2, y2, a1, b1, a2, b2):
i1 = max(x1, a1)
j1 = max(y1, b1)
i2 = min(x2, a2)
j2 = min(y2, b2)
# 交叉区域的宽和高,以及交叉区域面积
w = max(0, i2 - i1)
h = max(0, j2 - j1)
ri = w * h
# 两个方框的面积
r1 = (x1 - x2) * (y1 - y2)
r2 = (a1 - a2) * (b1 - b2)
res = ri / (r1 + r2 - ri)
return res
A = [0, 0, 2, 2]
B = [1, 1, 3, 3]
print(getIoU(*(A + B)))
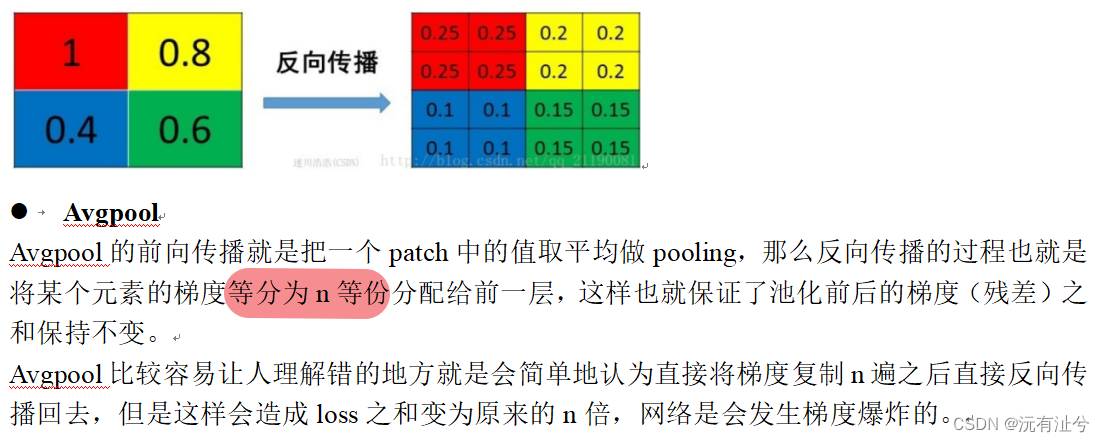
池化层作用及其反向传播原理



(二)NLP
TF-IDF

分别从词表示以及实际应用两个角度分析静态词向量的优缺点。并针对其缺点,思考并提出一种合理的解决方案

针对低频词的词向量学习改进方案

将预训练词向量用于目标任务时,什么情形下,“冻结”词向量比精调词向量更合理?

分别从词表示和语义组合的角度阐述动态词向量的特点,以及其相比于静态词向量的优势

除了以特征形式应用于下游任务,动态词向量还有哪些潜在的应用场景?

从模型的角度对比分析 GPT 和 BERT 各自的优缺点是什么?

BERT 的输入表示中为什么要包含位置向量?如果没有位置向量将有何影响?

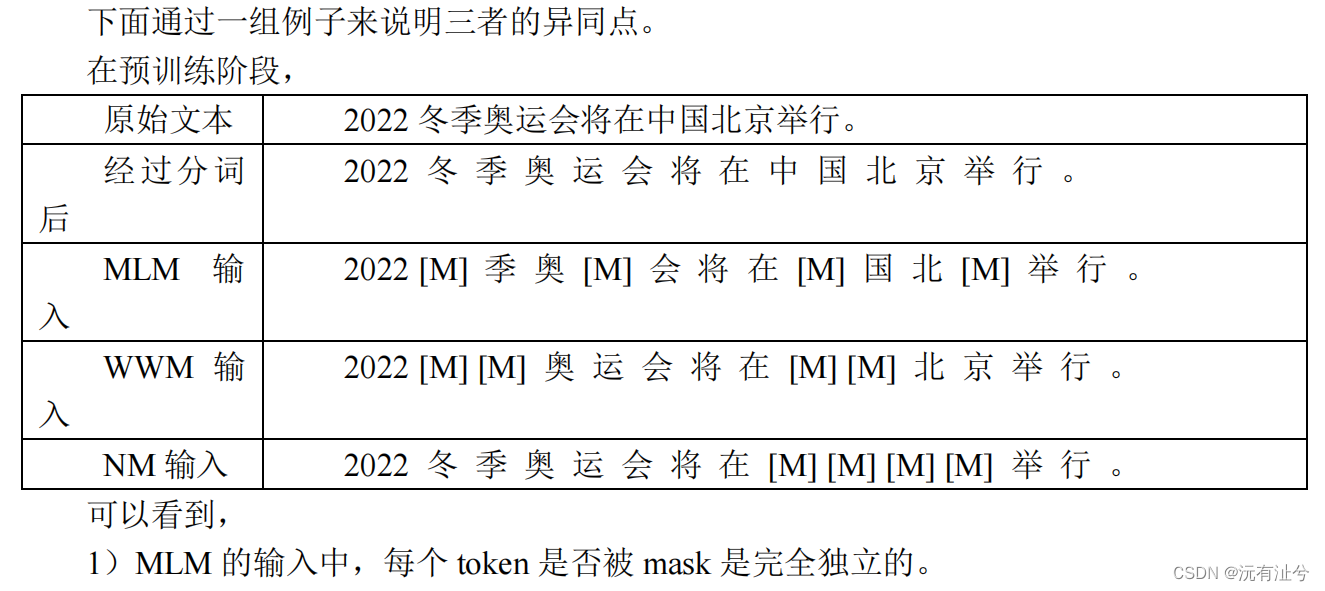
阐述应用三种不同掩码策略(MLM、WWM 和 NM)的 BERT,在预训练阶段和下游任务精调中的异同点。

(三)数据结构
线性表插入和删除时,元素平均移动次数

(四)操作系统
(五)模型
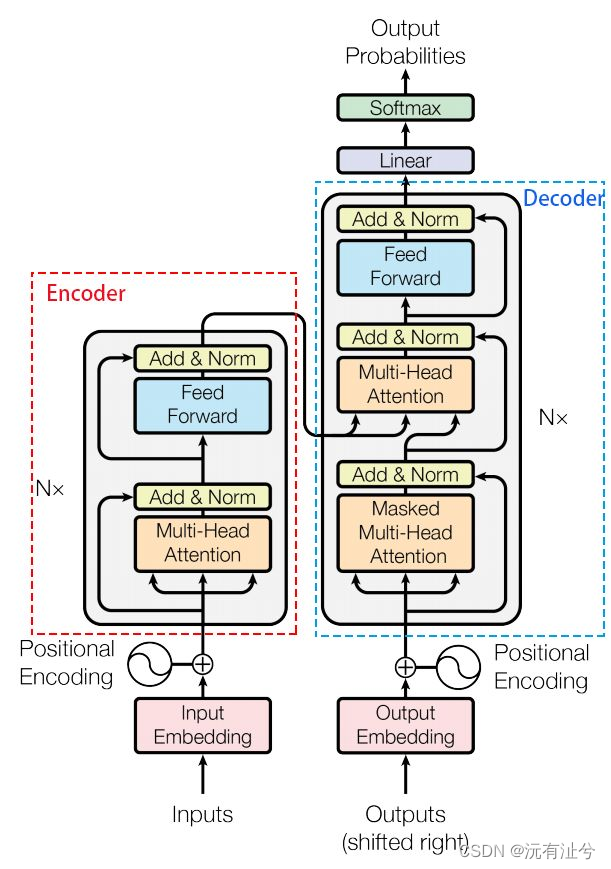
transformer
Transformer - Attention is all you need



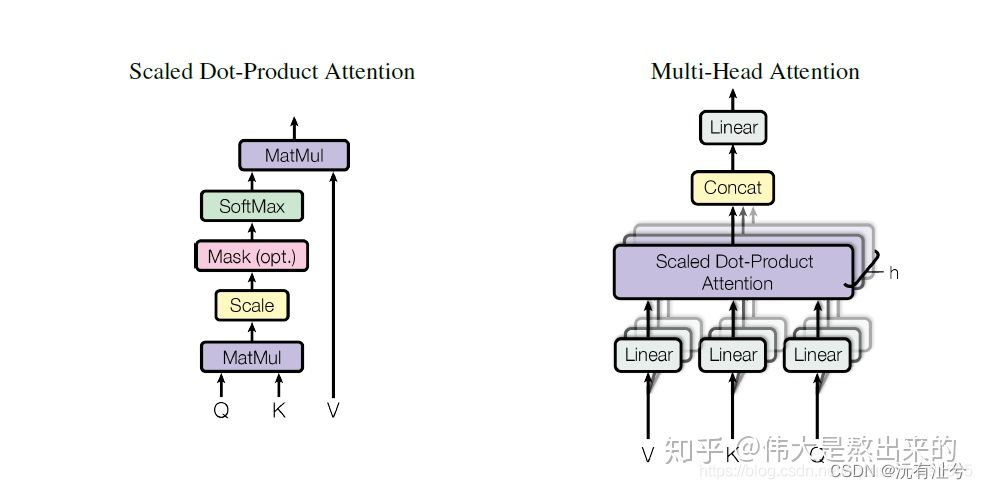
- 计算注意力分数时为什么缩放?
缩放因子的作用是归一化

- 多头
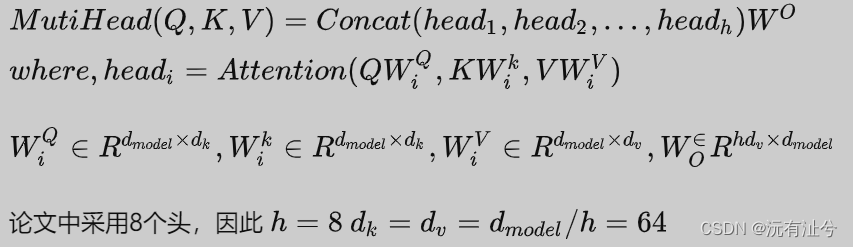

- Position-wise Feed Forward

- Layer Normalization
作用是规范优化空间,加速收敛
随着网络层数的增加,数据分布不断发生变化,偏差越来越大,导致我们不得不使用更小的学习率来稳定梯度。Layer Normalization 的作用就是保证数据特征分布的稳定性,将数据标准化到ReLU激活函数的作用区域,可以使得激活函数更好的发挥作用
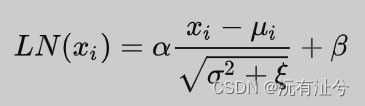
- Positional Encoding
弥补了Attention机制无法捕捉sequence中token位置信息的缺点,使得模型能够充分利用token在sequence中的位置信息。
Positional Embedding的成分直接叠加于Embedding之上,使得每个token的位置信息和它的语义信息(embedding)充分融合
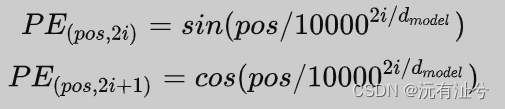

- Mask 机制
它对某些值进行掩盖,使其在参数更新时不产生效果
Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
- padding mask
因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。
因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方(即填充0的地方)就是我们要进行处理的地方。- Sequence mask
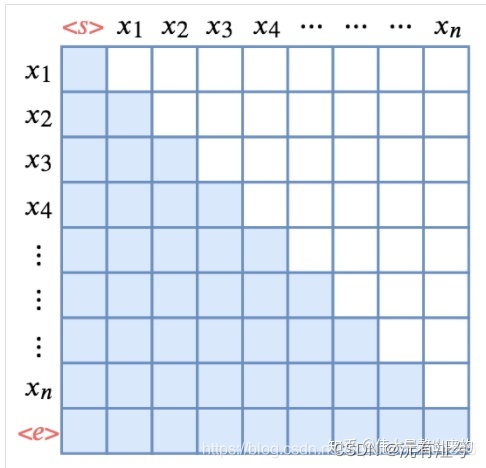
解码过程是一个顺序操作的过程,也就是当解码第K个特征向量时,我们只能看到第K-1及其之前的解码结果,论文中把这种情况下的multi-head attention叫做masked multi-head attention。
sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。

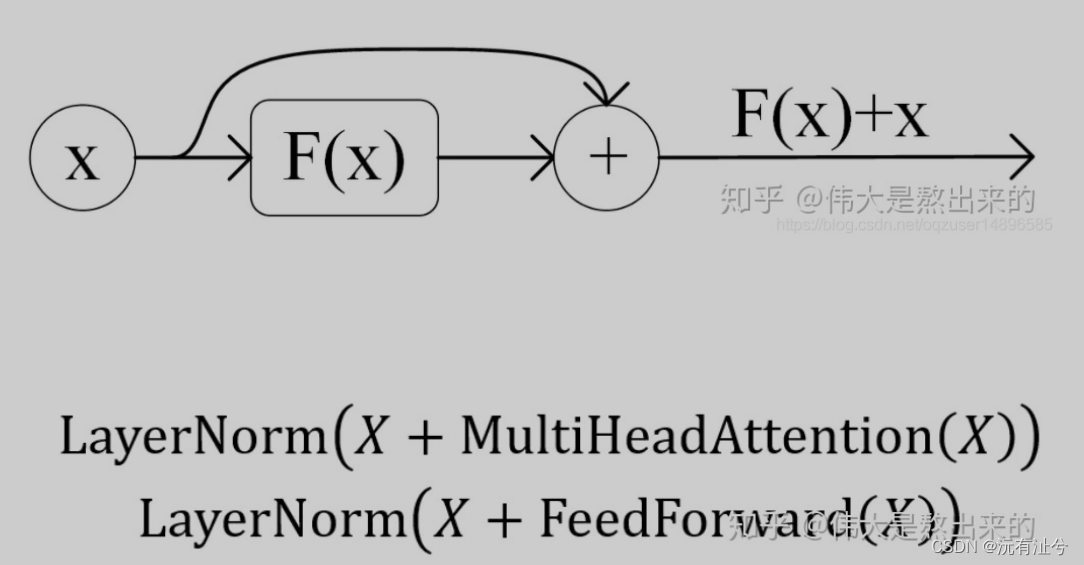
- Residual Network 残差网络

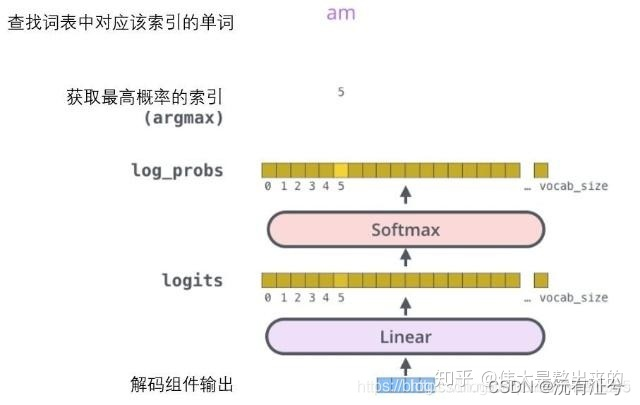
- Linear & Softmax

- 模型整体运行过程
- 细节
- 为什么需要进行Multi-head Attention
- Transformer相比于RNN/LSTM,有什么优势?为什么?
- 为什么说Transformer可以代替seq2seq



- 损失函数
解码器解码之后,解码的特征向量经过一层激活函数为softmax的全连接层之后得到反映每个单词概率的输出向量。此时我们便可以通过CTC等损失函数训练模型了
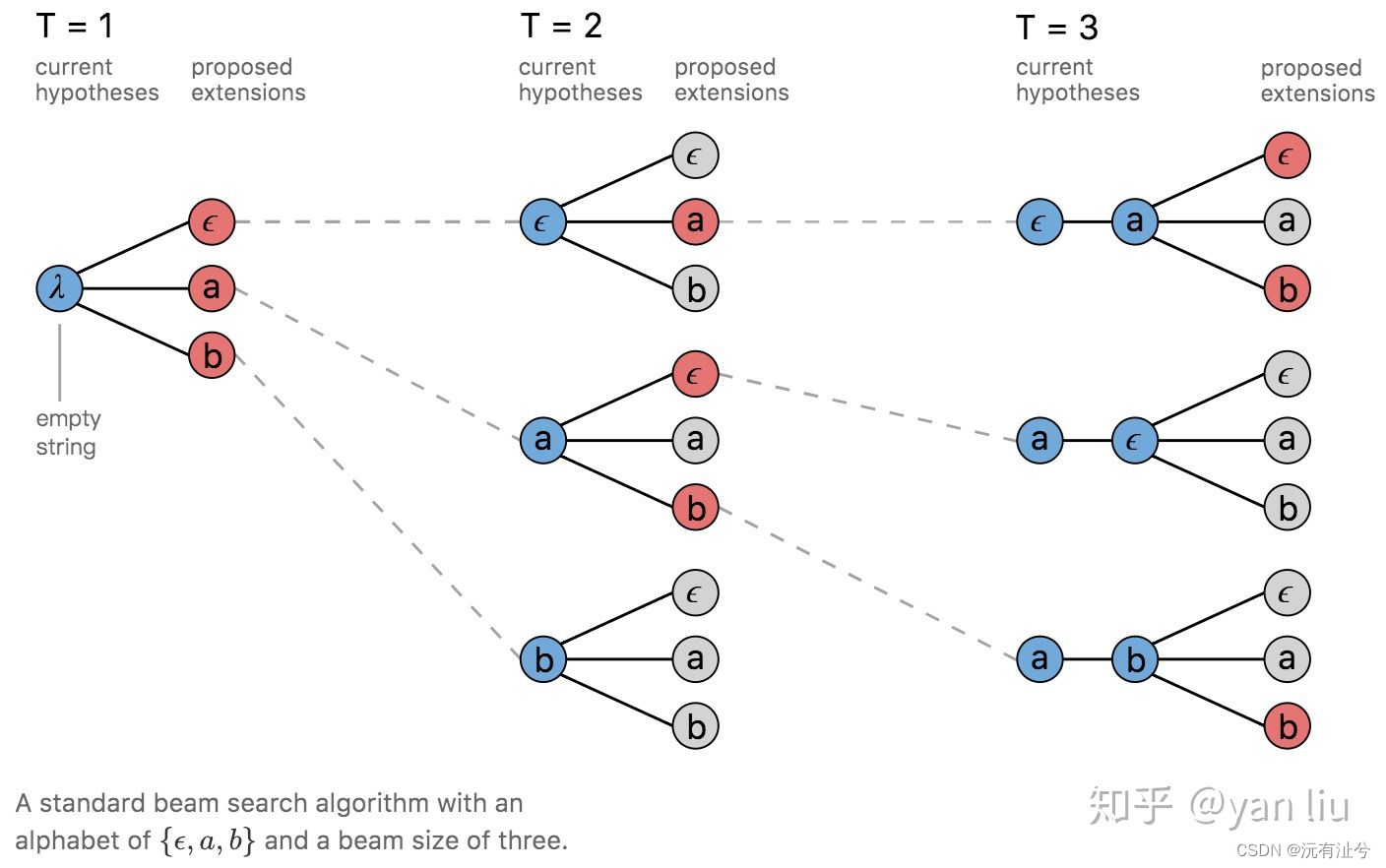
- beam_search


-
为什么Transformer要用LayerNorm?


-
优点
- 与RNN相比长序列建模能力更强
与RNN相比可以直接建模输入序列单元之间更长距离的依赖关系- encoder部分的多头计算可以并行,训练速度快
- 缺陷
3. 参数量过于庞大,不容易训练
参数主要集中在qkv的权重网络和多层感知器中

参考文章:
https://zhuanlan.zhihu.com/p/311156298
https://blog.csdn.net/longxinchen_ml/article/details/86533005
详解CTC
为什么Transformer要用LayerNorm?
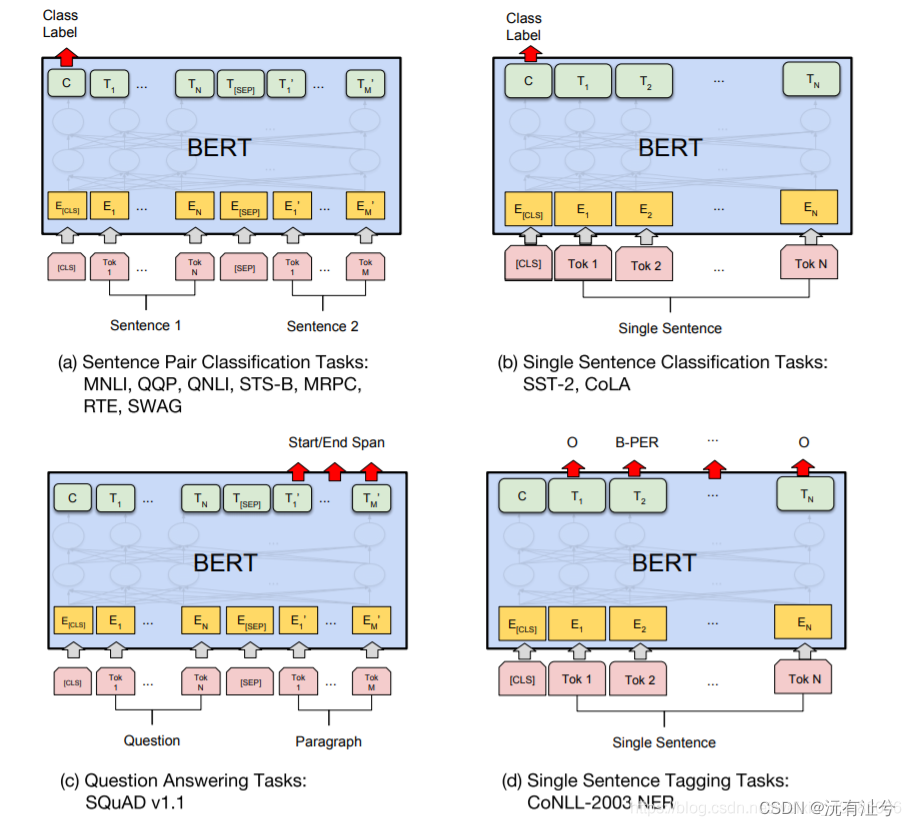
bert
BERT全称为“Bidirectional Encoder Representations from Transformers”。它是一个基于Transformer结构的双向编码器。其结构可以简单理解为Transformer的encoder部分
\quad 在上面的超参数中,L表示网络的层数(即Transformer blocks的数量),A表示Multi-Head Attention中self-Attention的数量,filter的尺寸是4H。
\quad BERT主要分为三层,embedding层、encoder层、prediction层。


-
Embedding层

-
Encoder层
Encoder层则和Transformer encoder基本相同,主要完成两个自监督任务,即MLM和NSP。- Masked Language Model

- Next Sentence Prediction

- Masked Language Model
-
prediction层

-
bert和位置编码方式与transformer有何不同?


- 优缺点

参考资料
(六)机器学习
缺失值处理
(七)Pytorch
Pytorch常用创建Tensor方法总结
(八)Python
赋值(引用)、浅复制、深复制
函数
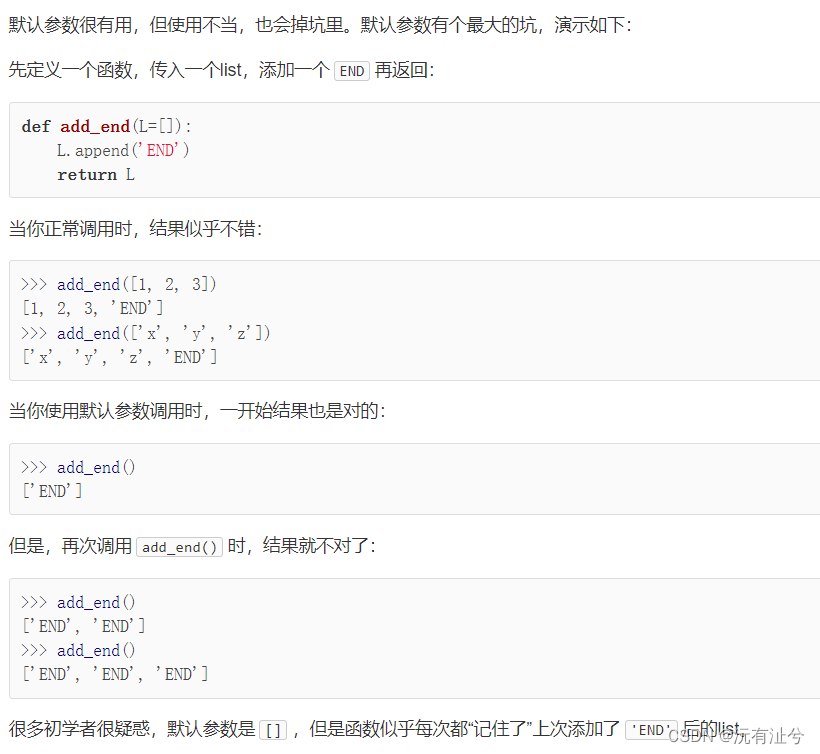
默认参数

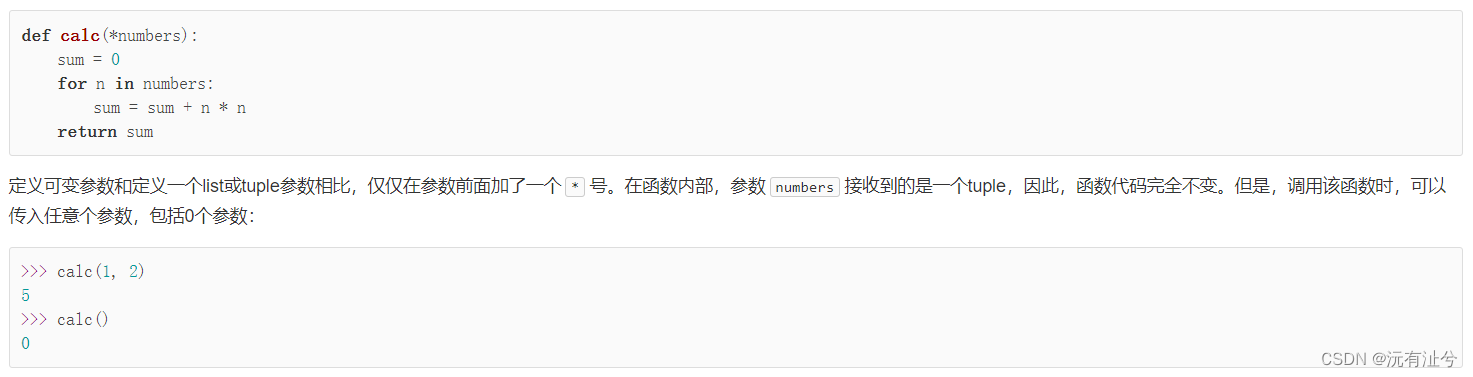
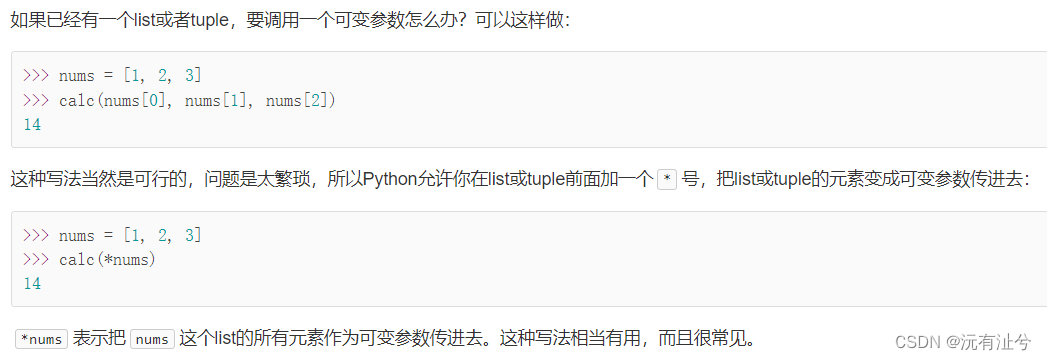
可变参数
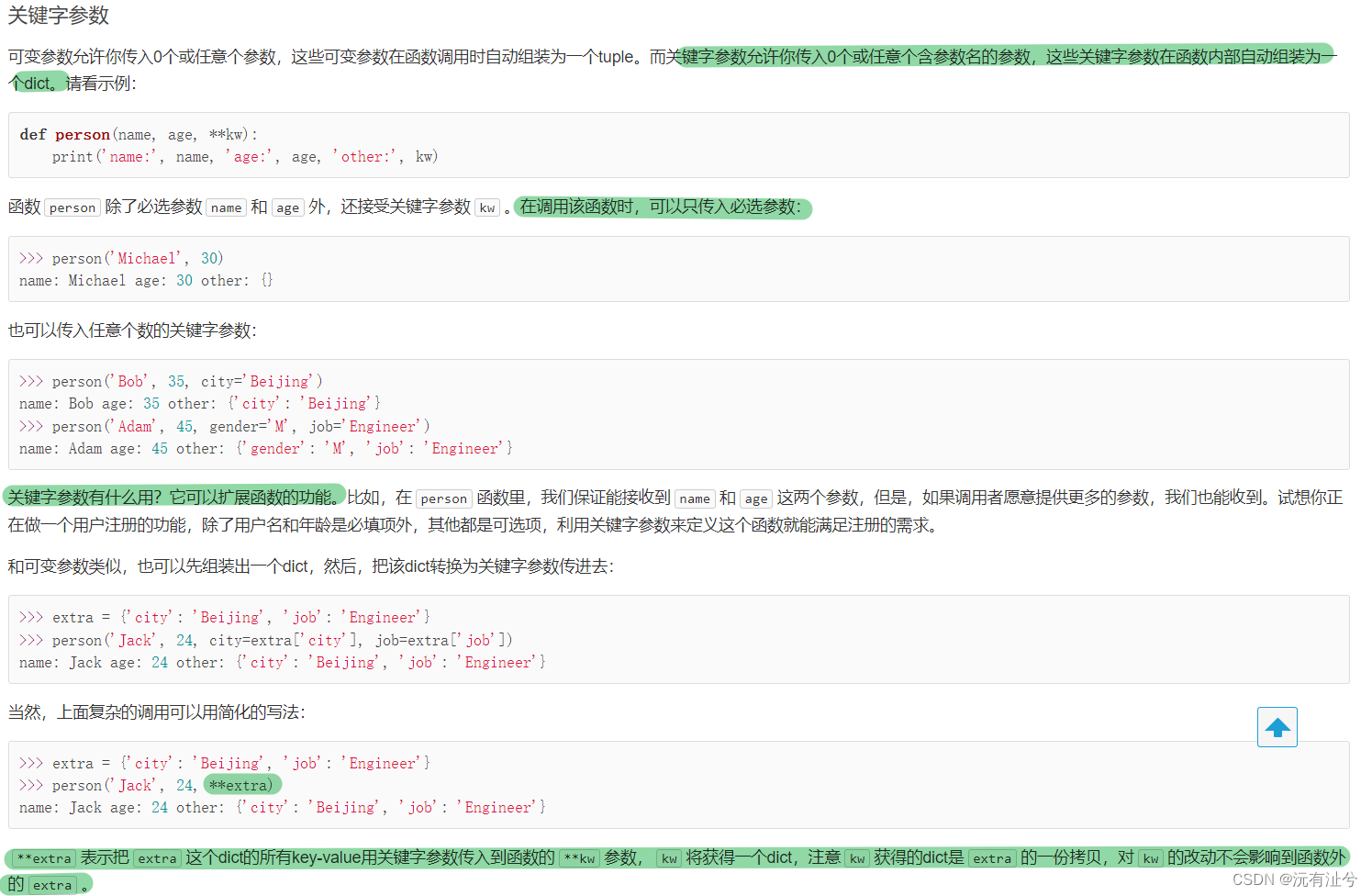
关键字参数
命名关键字参数
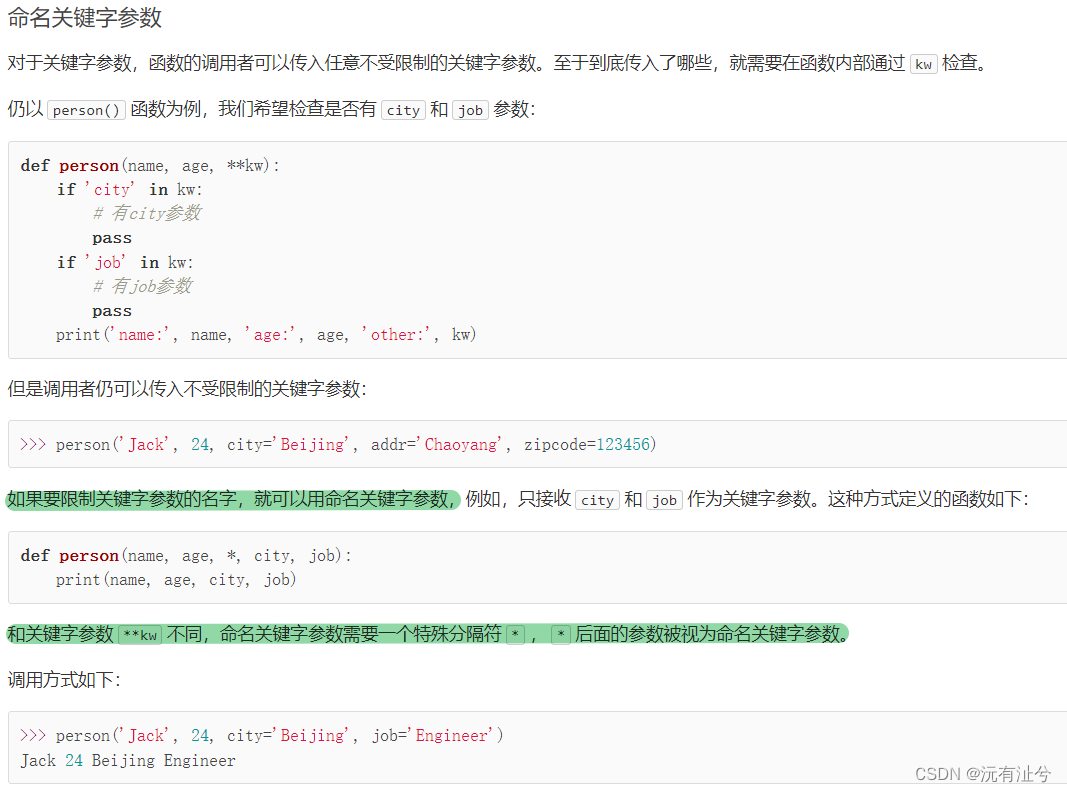
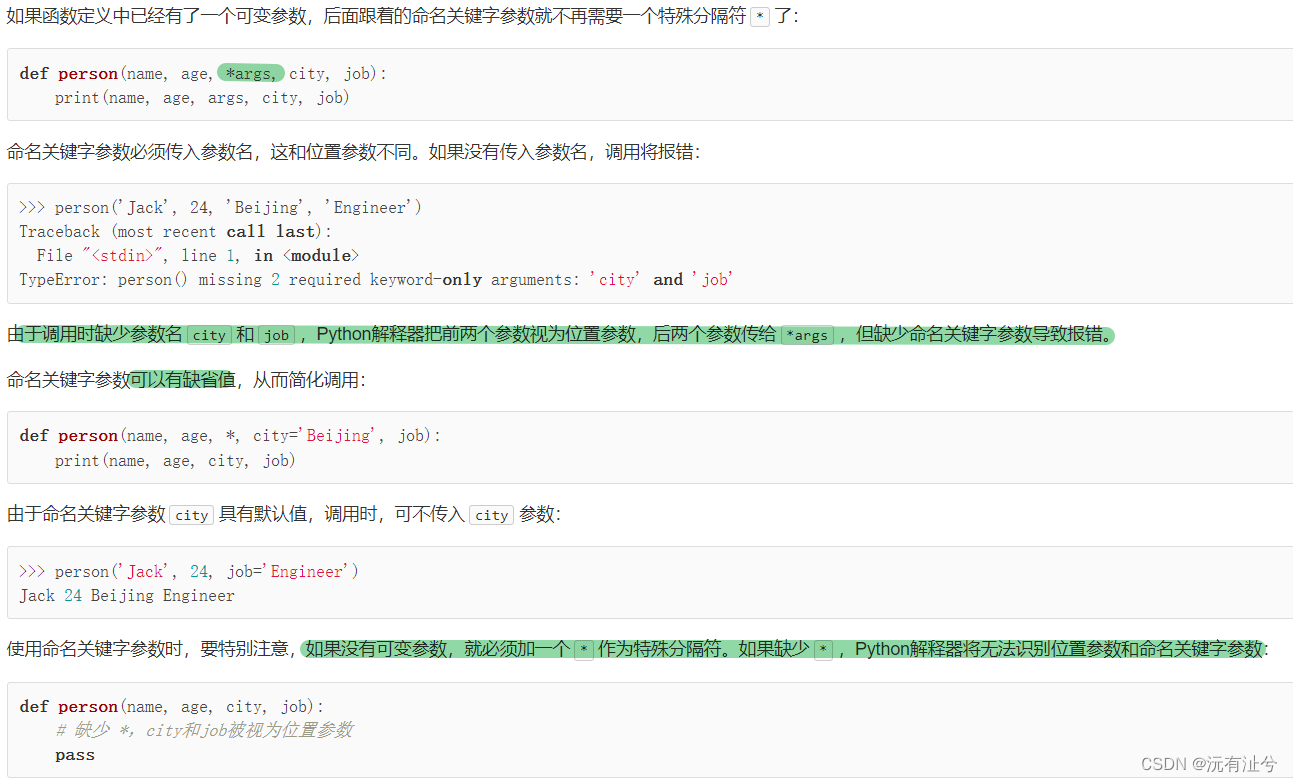
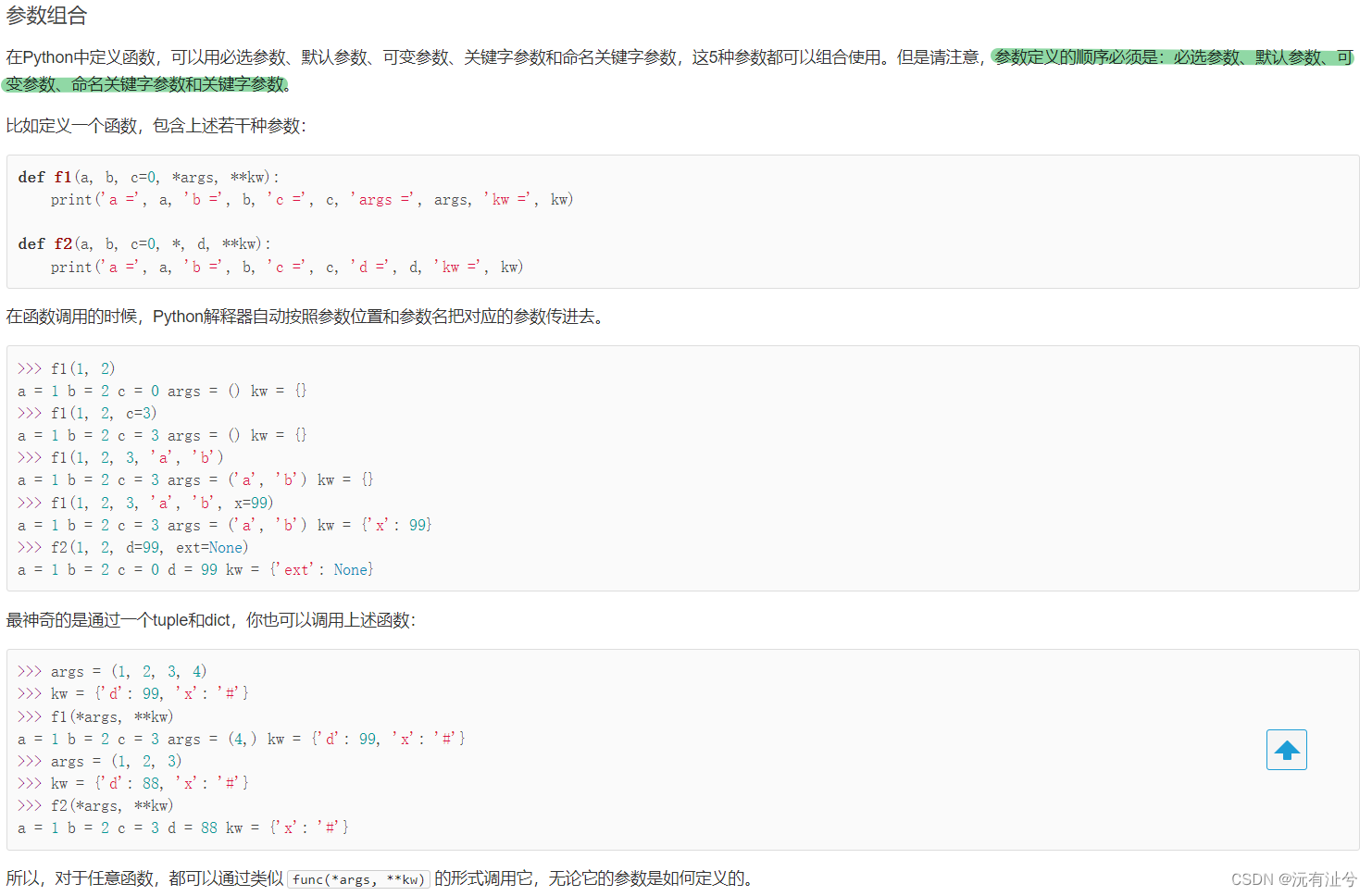
参数组合
高级特性
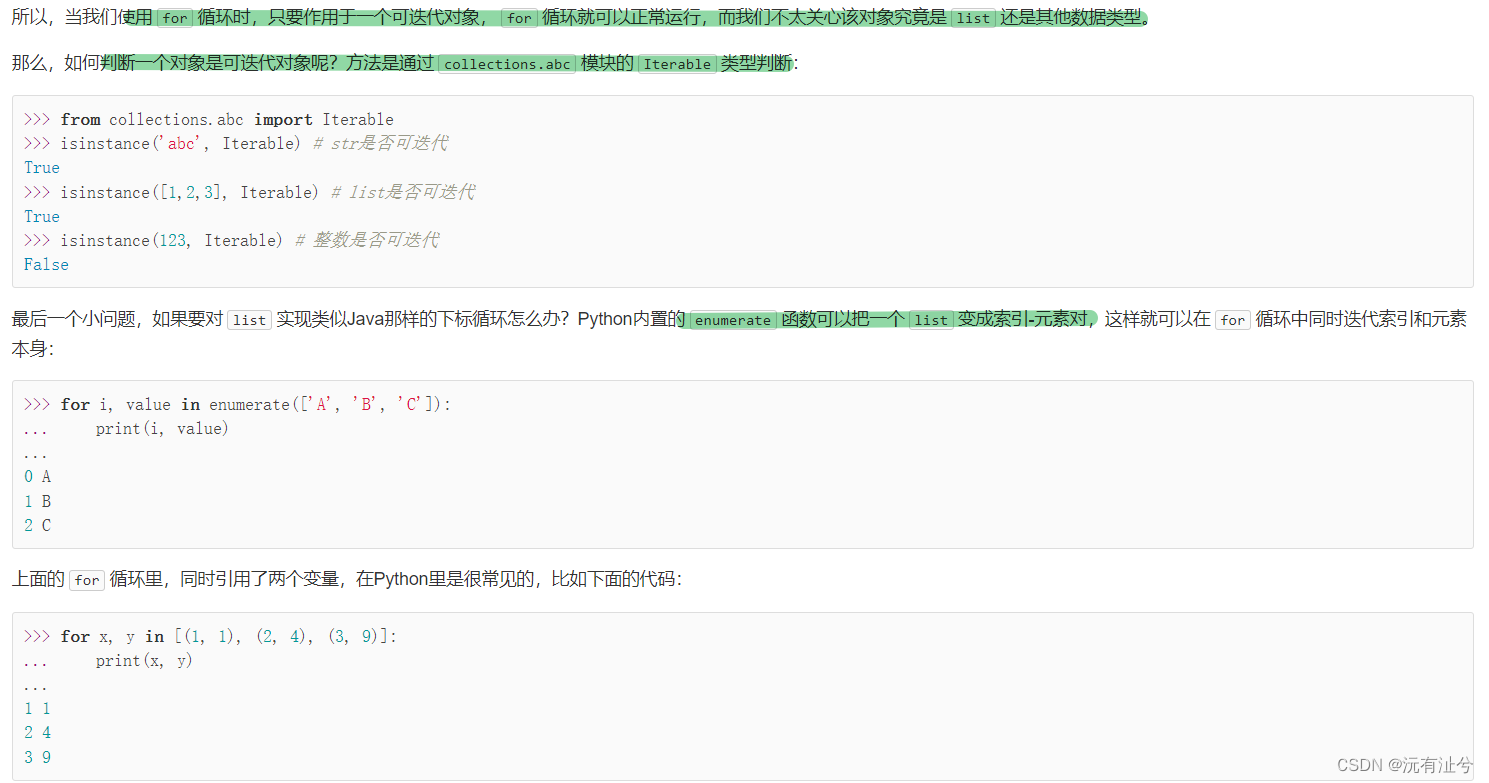
迭代
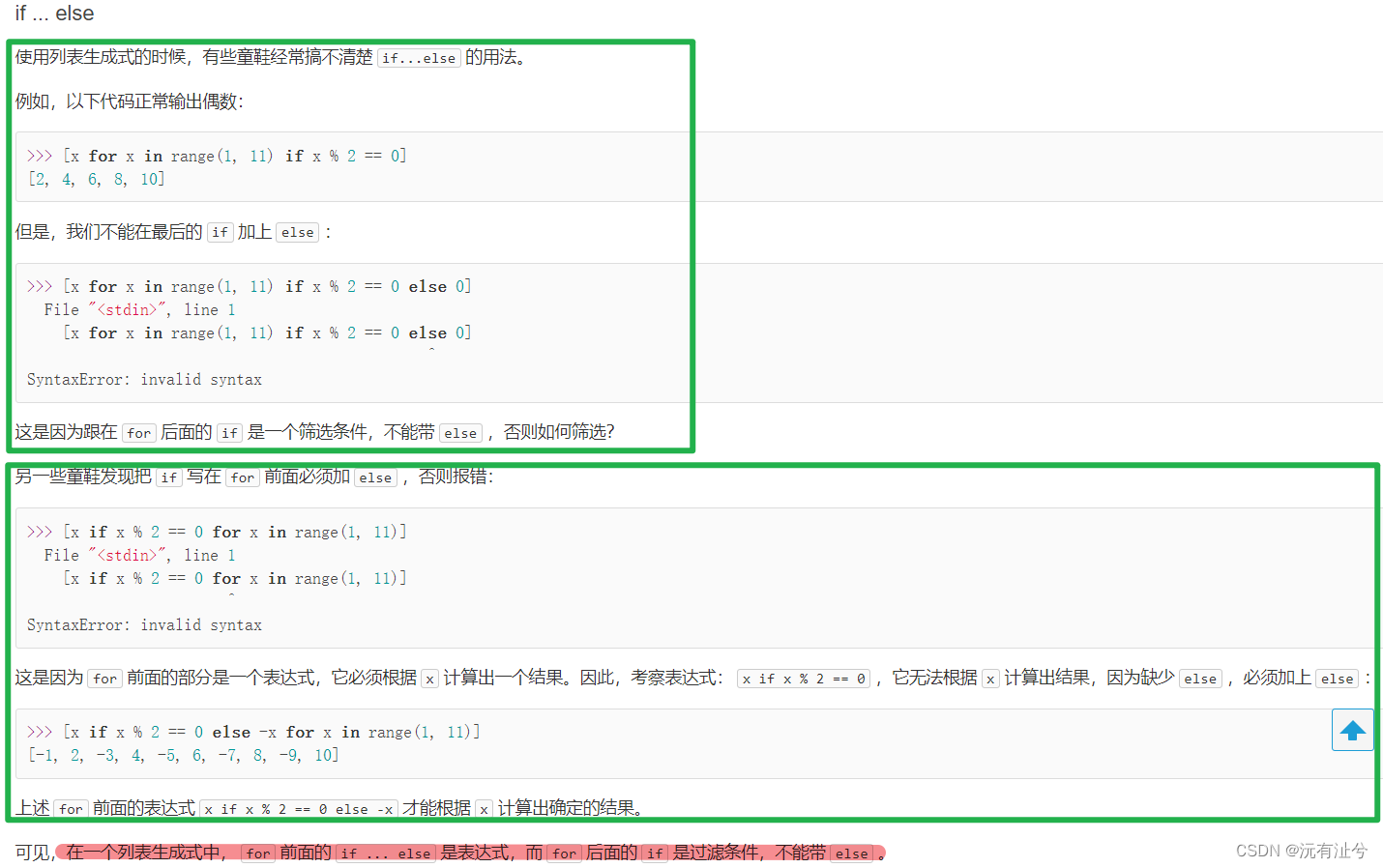
列表生成式
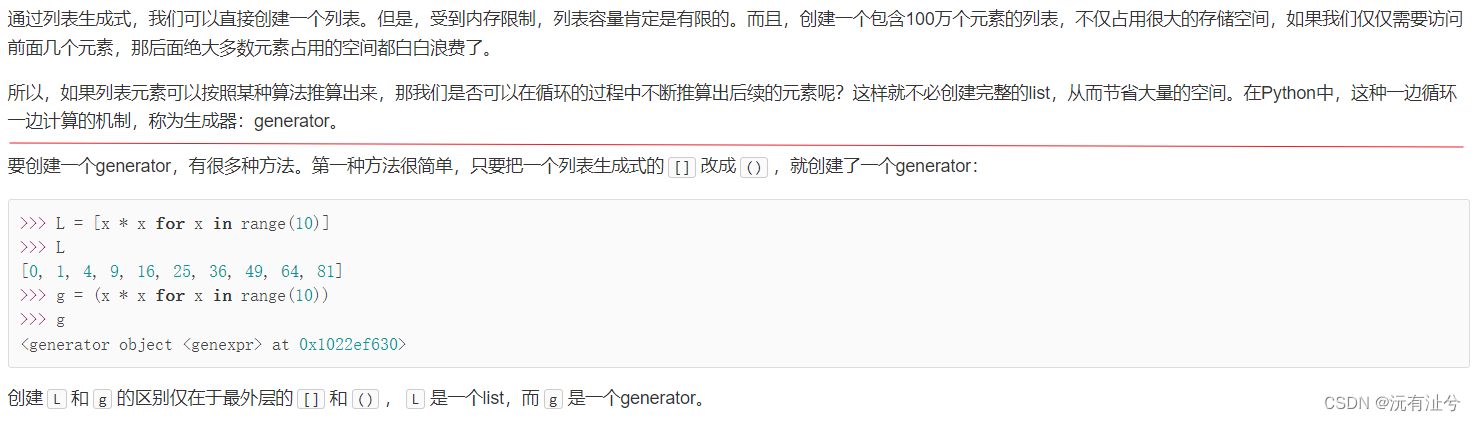
生成器

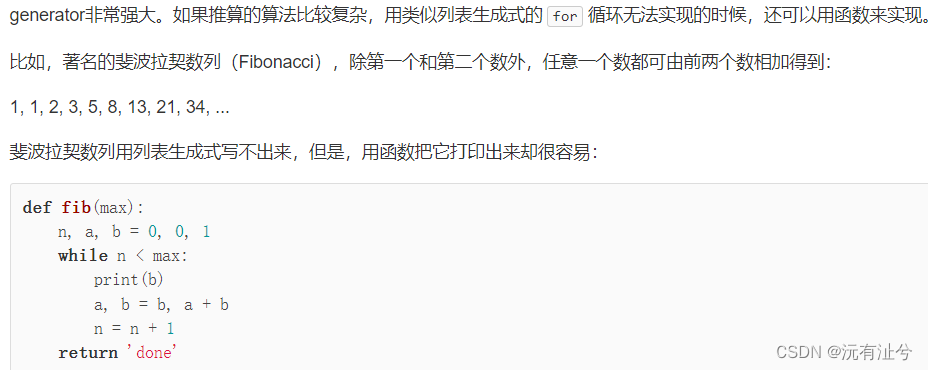
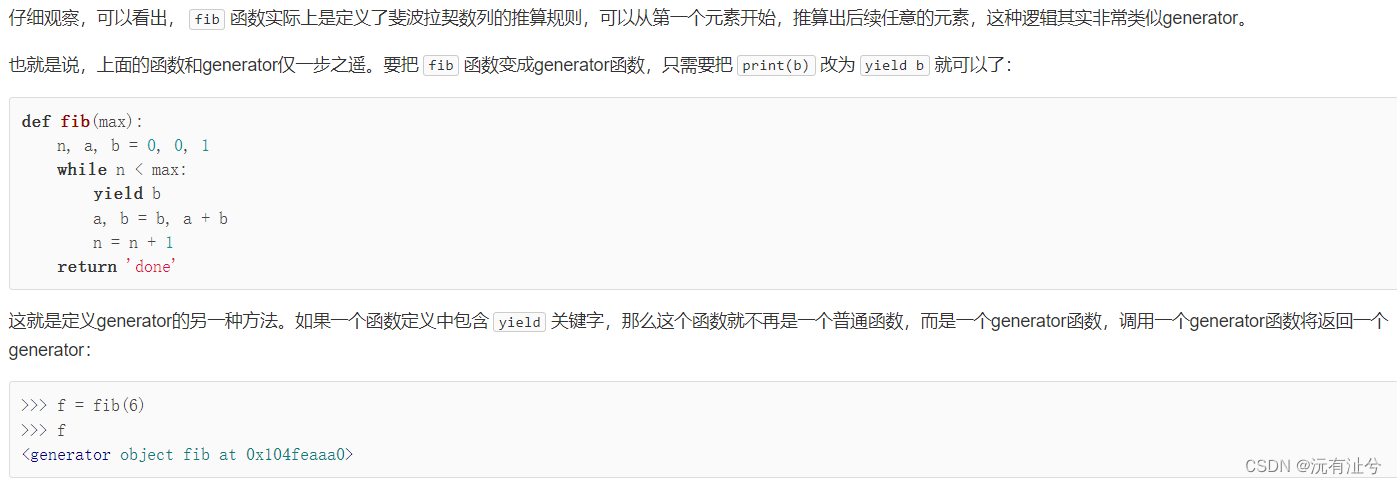
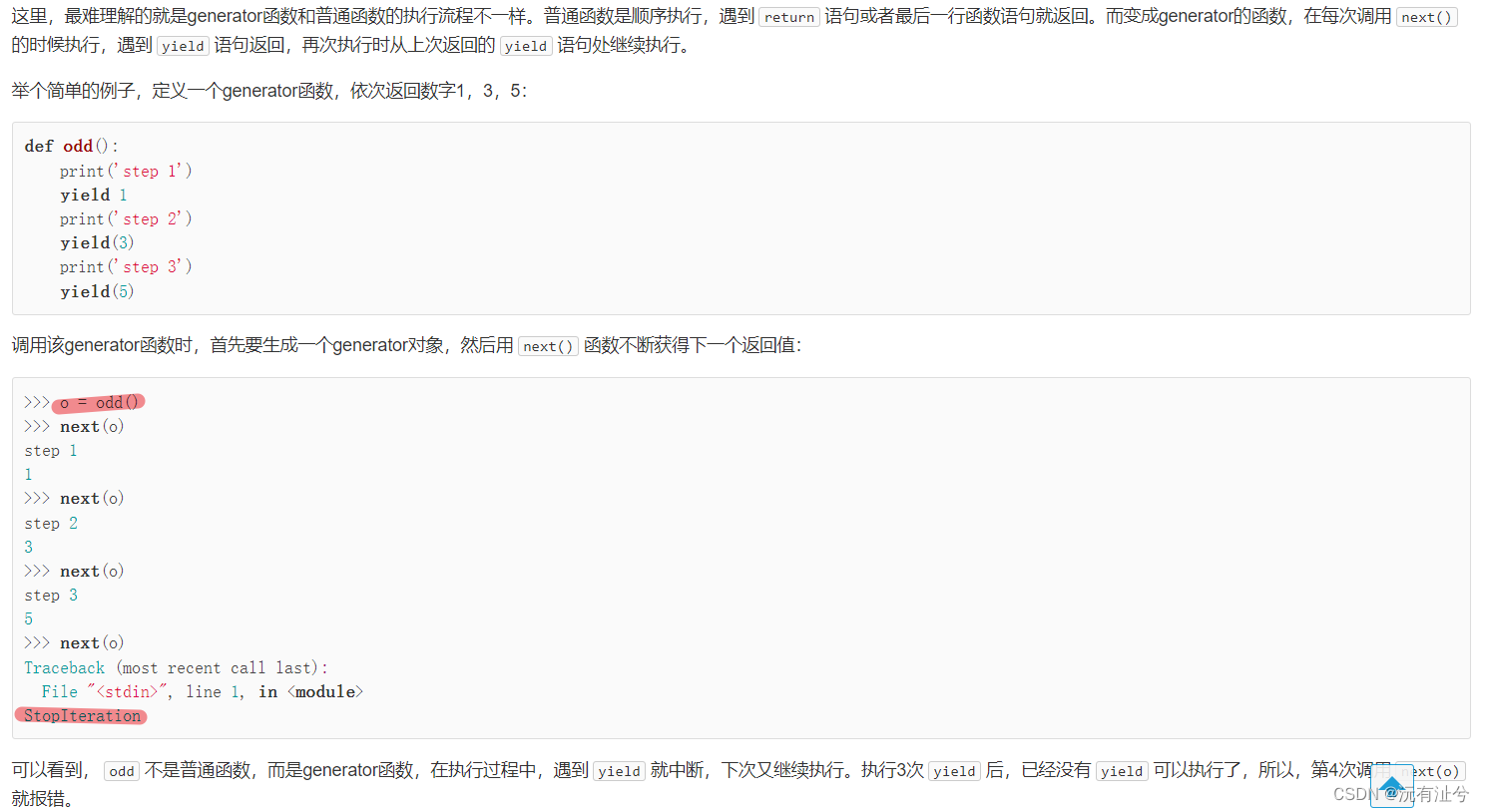
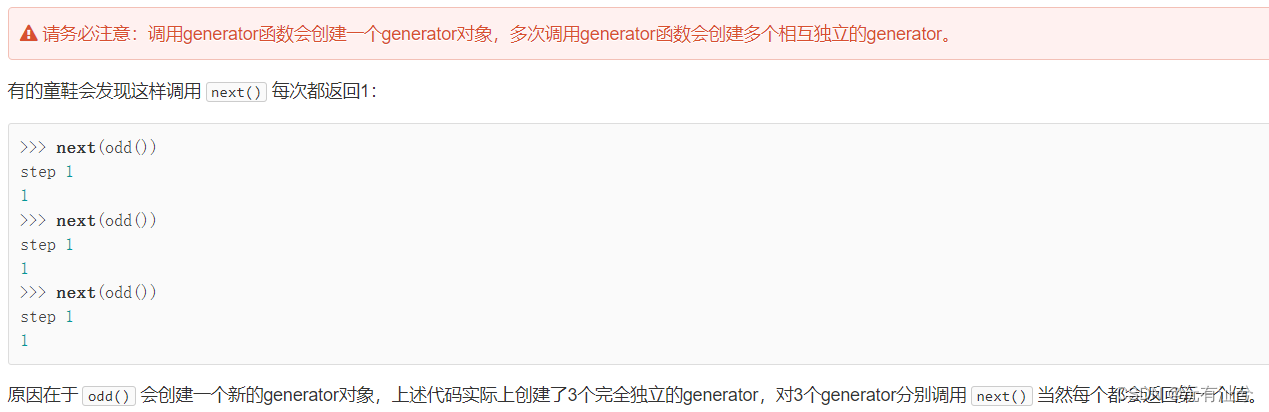
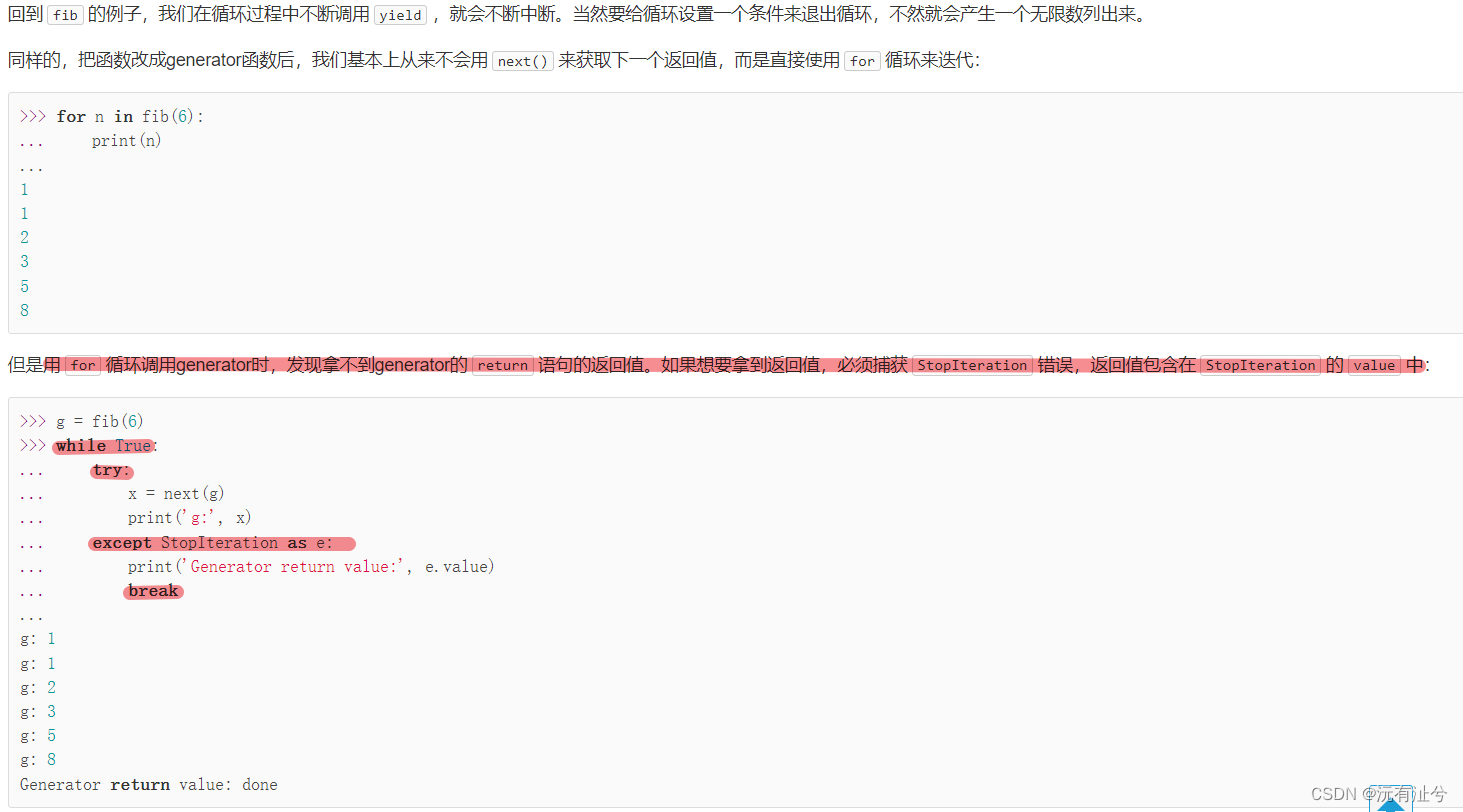
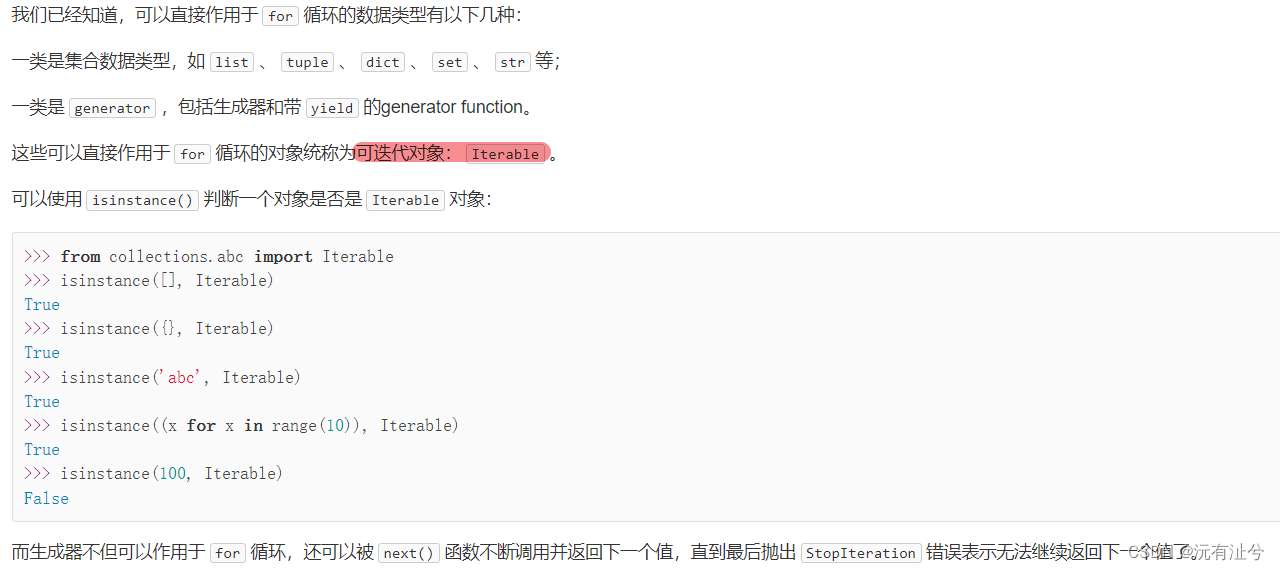
迭代器
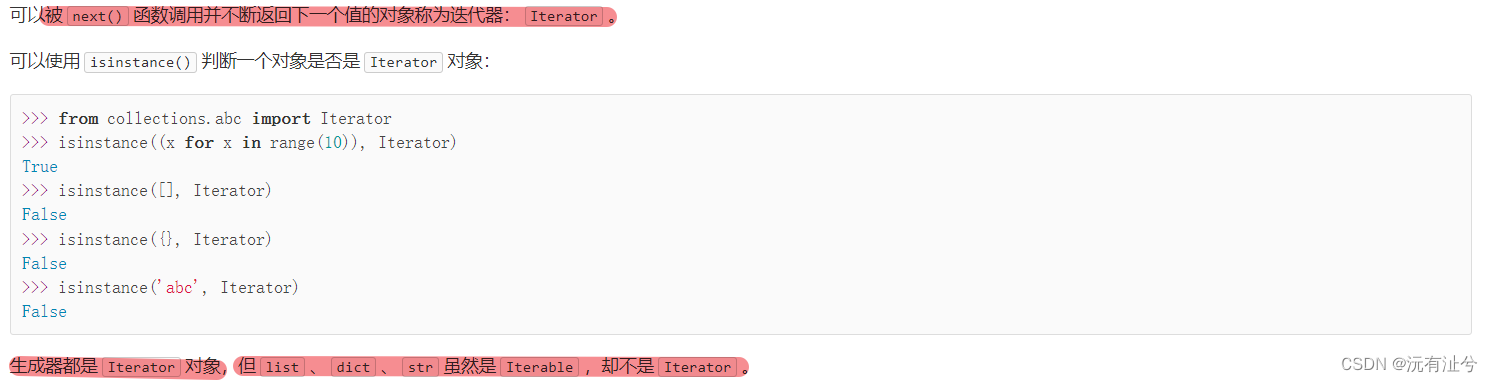
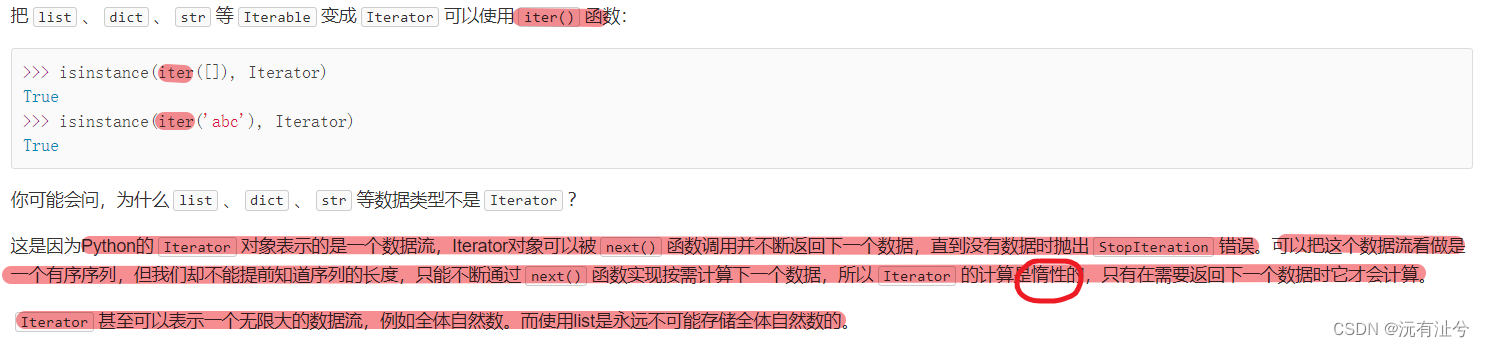
函数式编程
高阶函数
- map/reduce
- filter
- sorted
返回函数
匿名函数
装饰器
偏函数
模块
使用模块
使用第三方模块
面向对象编程
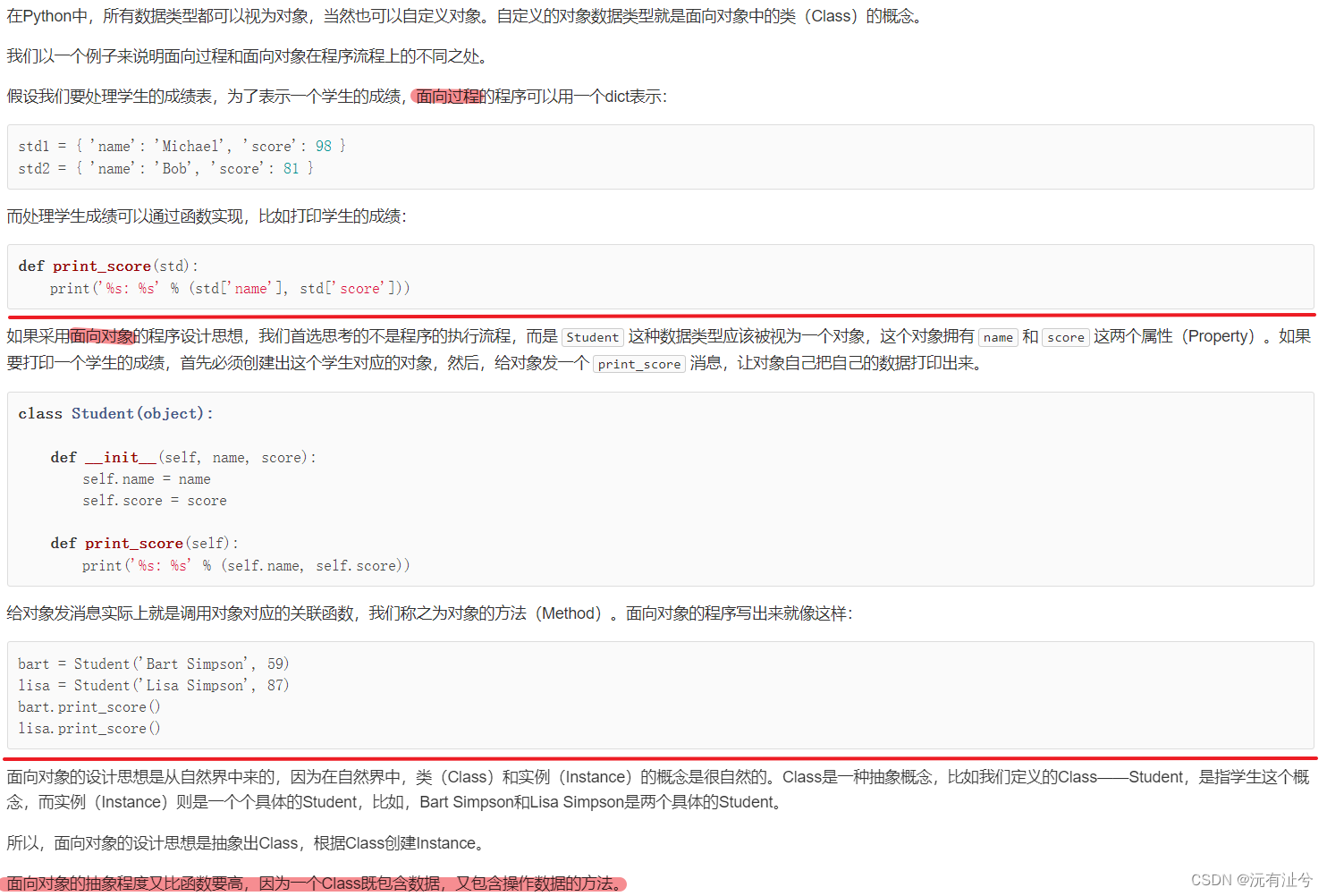
面向对象高级编程
访问限制
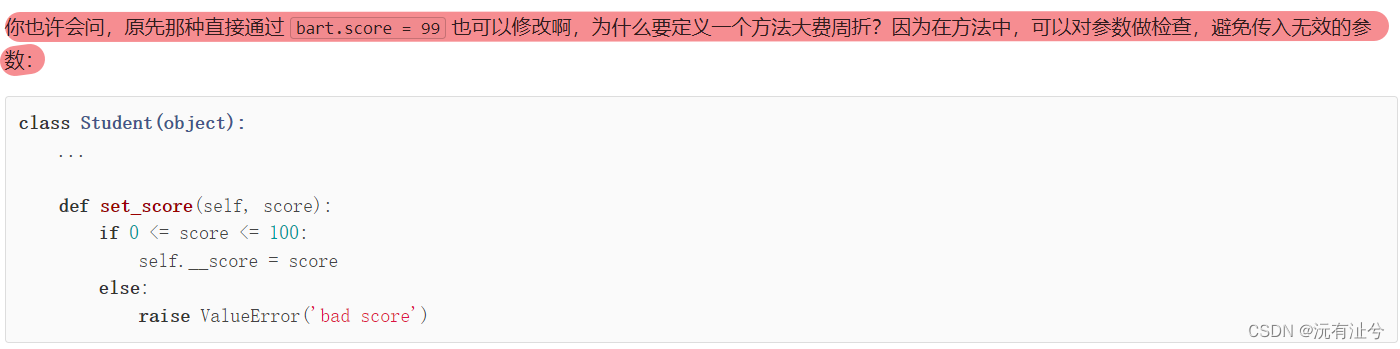
(九)其他
梯度消失,梯度爆炸
详解机器学习中的梯度消失、爆炸原因及其解决方法
基础 | batchnorm原理及代码详解
你必须要知道CNN模型:ResNet
- 关键词
深度神经网络 反向传播 链式求导法则 激活函数的导数值(sigmoid最大0.25,大于1时,小于1时)- 解决梯度爆炸、消失的方法
逐层训练后,再对整个网络进行训练(Hinton)
梯度裁剪
(权重)正则化
使用ReLU、LeakyRuLU、ELU等激活函数
残差结构
LSTM


















 3889
3889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









