







 本文回顾了2017年AI领域的关键进展,包括AlphaGo Zero的通用人工智能突破、GAN技术的广泛应用、Capsule网络的提出以及CTR预估的深度学习升级。AlphaGo Zero通过自我对弈学习,实现了从零开始的围棋高手。GAN在图像生成和风格转换方面取得进展,而Capsule网络试图解决CNN的视角不变性问题。在CTR预估领域,深度学习开始用于特征组合和离散特征表示。此外,计算机视觉和自然语言处理领域也持续发展,寻求新技术突破。
本文回顾了2017年AI领域的关键进展,包括AlphaGo Zero的通用人工智能突破、GAN技术的广泛应用、Capsule网络的提出以及CTR预估的深度学习升级。AlphaGo Zero通过自我对弈学习,实现了从零开始的围棋高手。GAN在图像生成和风格转换方面取得进展,而Capsule网络试图解决CNN的视角不变性问题。在CTR预估领域,深度学习开始用于特征组合和离散特征表示。此外,计算机视觉和自然语言处理领域也持续发展,寻求新技术突破。
作者 | 张俊林,新浪微博AI实验室资深算法专家
责编 | 何永灿
人工智能最近三年发展如火如荼,学术界、工业界、投资界各方一起发力,硬件、算法与数据共同发展,不仅仅是大型互联网公司,包括大量创业公司以及传统行业的公司都开始涉足人工智能。2017年人工智能行业延续了2016年蓬勃发展的势头,那么在过去的一年里AI行业从技术发展角度有哪些重要进展?未来又有哪些发展趋势?本文从大家比较关注的若干领域作为代表,来归纳AI领域一些方向的重要技术进展。
从AlphaGo Zero到Alpha Zero:迈向通用人工智能的关键一步
DeepMind携深度增强学习利器总是能够给人带来震撼性的技术创新,2016年横空出世的AlphaGo彻底粉碎了普遍存在的“围棋领域机器无法战败人类最强手”的执念,但是毕竟李世石还是赢了一局,不少人对于人类翻盘大逆转还是抱有希望,紧接着Master通过60连胜诸多顶尖围棋高手彻底浇灭了这种期待。2017年AlphaGo Zero作为AlphaGo二代做了进一步的技术升级,把AlphaGo一代虐得体无完肤,这时候人类已经没有资格上场对局了。2017年底AlphaGo的棋类游戏通用版本Alpha Zero问世,不仅仅围棋,对于国际象棋、日本将棋等其他棋类游戏,Alpha Zero也以压倒性优势战胜包括AlphaGo Zero在内的目前最强的AI程序。
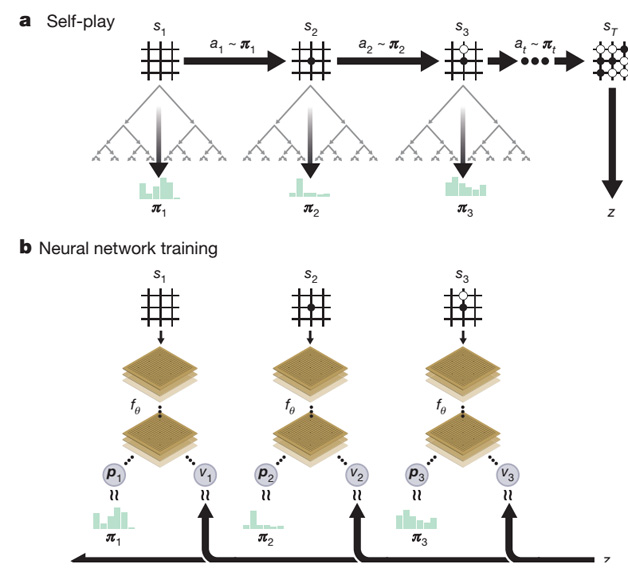
AlphaGo Zero从技术手段上和AlphaGo相比并未有本质上的改进,主体仍然是MCST蒙特卡洛搜索树加神经网络的结构以及深度增强学习训练方法,但是技术实现上简单优雅很多(参考图1)。主要的改动包含两处:一处是将AlphaGo的两个预测网络(策略网络和价值网络)合并成一个网络,但是同时产生两类所需的输出;第二处是网络结构从CNN结构升级为ResNet。虽说如此,AlphaGo Zero给人带来的触动和启发丝毫不比AlphaGo少,主要原因是AlphaGo Zero完全放弃了从人类棋局来进行下棋经验的学习,直接从一张白纸开始通过自我对弈的方式进行学习,并仅仅通过三天的自我学习便获得了远超人类千年积累的围棋经验。
这引发了一个之前一般人很期待但是同时又认为很难完成的问题:机器能够不依赖有监督方式的训练数据或者极少的训练数据自我进化与学习吗?如果真的能够做到这一点,那么是否意味着机器会快速进化并淘汰人类?第二个问题甚至会引起部分人的恐慌。但是其实这个问题本身问的就有问题,因为它做了一个错误的假设:AlphaGo Zero是不需要训练数据的。首先,AlphaGo Zero确实做到了通过自我对弈的方式进行学习,但是仍然需要大量训练数据,无非这些训练数据是通过自我对弈来产生的。而且更根本的一点是应该意识到:对于AlphaGo Zero来说,其本质其实还是MCST蒙特卡洛树搜索。围棋之所以看着难度大难以克服,主要是搜索空间实在太大,单纯靠暴力搜索完全不可行。如果我们假设现在有个机器无限强大,能够快速遍历所有搜索空间,那么其实单纯使用MCST树搜索,不依靠机器学习,机器也能达到完美的博弈状态。AlphaGo Zero通过自我对弈以及深度增强学习主要达到了能够更好地评估棋盘状态和落子质量,优先选择走那些赢面大的博弈路径,这样能够舍弃大量的劣质路径,从而极大减少了需要搜索的空间,自我进化主要体现在评估棋面状态越来越准。而之所以能够通过自我对弈产生大量训练数据,是因为下棋是个规则定义很清晰的任务,到了一定状态就能够赢或者输,无非这种最终的赢或者输来得晚一些,不是每一步落子就能看到的,现实生活中的任务是很难达到这一点的,这是为何很多任务仍然需要人类提供大量训练数据的原因。如果从这个角度考虑,就不会错误地产生以上的疑虑。
Alpha Zero相对AlphaGo Zero则更进一步,将只能让机器下围棋拓展到能够进行规则定义清晰的更多棋类问题,使得这种技术往通用人工智能的路上迈出了重要一步。其技术手段和AlphaGo Zero基本是相同的,只是去除掉所有跟围棋有关的一些处理措施和技术手段,只告诉机器游戏规则是什么,然后使用MCST树搜索+深度神经网络并结合深度增强学习自我对弈的统一技术方案和训练手段解决一切棋类问题。
从AlphaGo的一步步进化策略可以看出,DeepMind正在考虑这套扩展技术方案的通用性,使得它能够使用一套技术解决更多问题,尤其是那些非游戏类的真实生活中有现实价值的问题。同时,AlphaGo系列技术也向机器学习从业人员展示了深度增强学习的强大威力,并进一步推动了相关的技术进步,目前也可以看到深度增强学习在更多领域应用的实例。
GAN:前景广阔,理论与应用极速发展中
GAN,全称为Generative Adversarial Nets&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









