







在这里转载只是为了让不能够科学搜索的同学们看到好文章而已,个人无收益只是分享知识(顺手做个记录罢了)
原网址:https://towardsdatascience.com/laplace-smoothing-in-na%C3%AFve-bayes-algorithm-9c237a8bdece
Naïve Bayes is a probabilistic classifier based on Bayes theorem and is used for classification tasks. It works well enough in text classification problems such as spam filtering and the classification of reviews as positive or negative. The algorithm seems perfect at first, but the fundamental representation of Naïve Bayes can create some problems in real-world scenarios.
This article is built upon the assumption that you have a basic understanding of Naïve Bayes. I have written an article on Naïve Bayes. Feel free to check it out.
Understanding Naïve Bayes algorithm
A probabilistic classifier
Example
Let’s take an example of text classification where the task is to classify whether the review Is positive or negative. We build a likelihood table based on the training data. While querying a review, we use the Likelihood table values, but what if a word in a review was not present in the training dataset?
Query review = w1 w2 w3 w’
We have four words in our query review, and let’s assume only w1, w2, and w3 are present in training data. So, we will have a likelihood for those words. To calculate whether the review is positive or negative, we compare P(positive|review) and P(negative|review).
![]()
In the likelihood table, we have P(w1|positive), P(w2|Positive), P(w3|Positive), and P(positive). Oh, wait, but where is P(w’|positive)?
If the word is absent in the training dataset, then we don’t have its likelihood. What should we do?
Approach1- Ignore the term P(w’|positive)
Ignoring means that we are assigning it a value of 1, which means the probability of w’ occurring in positive P(w’|positive) and negative review P(w’|negative) is 1. This approach seems logically incorrect.
Approach 2- In a bag of words model, we count the occurrence of words. The occurrences of word w’ in training are 0. According to that
P(w’|positive)=0 and P(w’|negative)=0, but this will make both P(positive|review) and P(negative|review) equal to 0 since we multiply all the likelihoods. This is the problem of zero probability. So, how to deal with this problem?

Image by Pixabay, from Pexels
Laplace Smoothing
Laplace smoothing is a smoothing technique that handles the problem of zero probability in Naïve Bayes. Using Laplace smoothing, we can represent P(w’|positive) as
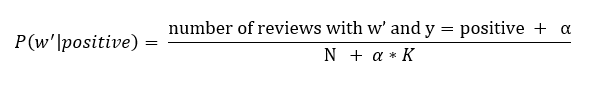
Here,
alpha represents the smoothing parameter,
K represents the number of dimensions (features) in the data, and
N represents the number of reviews with y=positive
If we choose a value of alpha!=0 (not equal to 0), the probability will no longer be zero even if a word is not present in the training dataset.
Interpretation of changing alpha
Let’s say the occurrence of word w is 3 with y=positive in training data. Assuming we have 2 features in our dataset, i.e., K=2 and N=100 (total number of positive reviews).
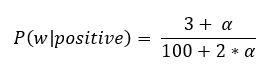
Case 1- when alpha=1
P(w’|positive) = 3/102
Case 2- when alpha = 100
P(w’|positive) = 103/300
Case 3- when alpha=1000
P(w’|positive) = 1003/2100
As alpha increases, the likelihood probability moves towards uniform distribution (0.5). Most of the time, alpha = 1 is being used to remove the problem of zero probability.
Conclusion
Laplace smoothing is a smoothing technique that helps tackle the problem of zero probability in the Naïve Bayes machine learning algorithm. Using higher alpha values will push the likelihood towards a value of 0.5, i.e., the probability of a word equal to 0.5 for both the positive and negative reviews. Since we are not getting much information from that, it is not preferable. Therefore, it is preferred to use alpha=1.
Thanks for reading!

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









