使用方式:explain+sql语句
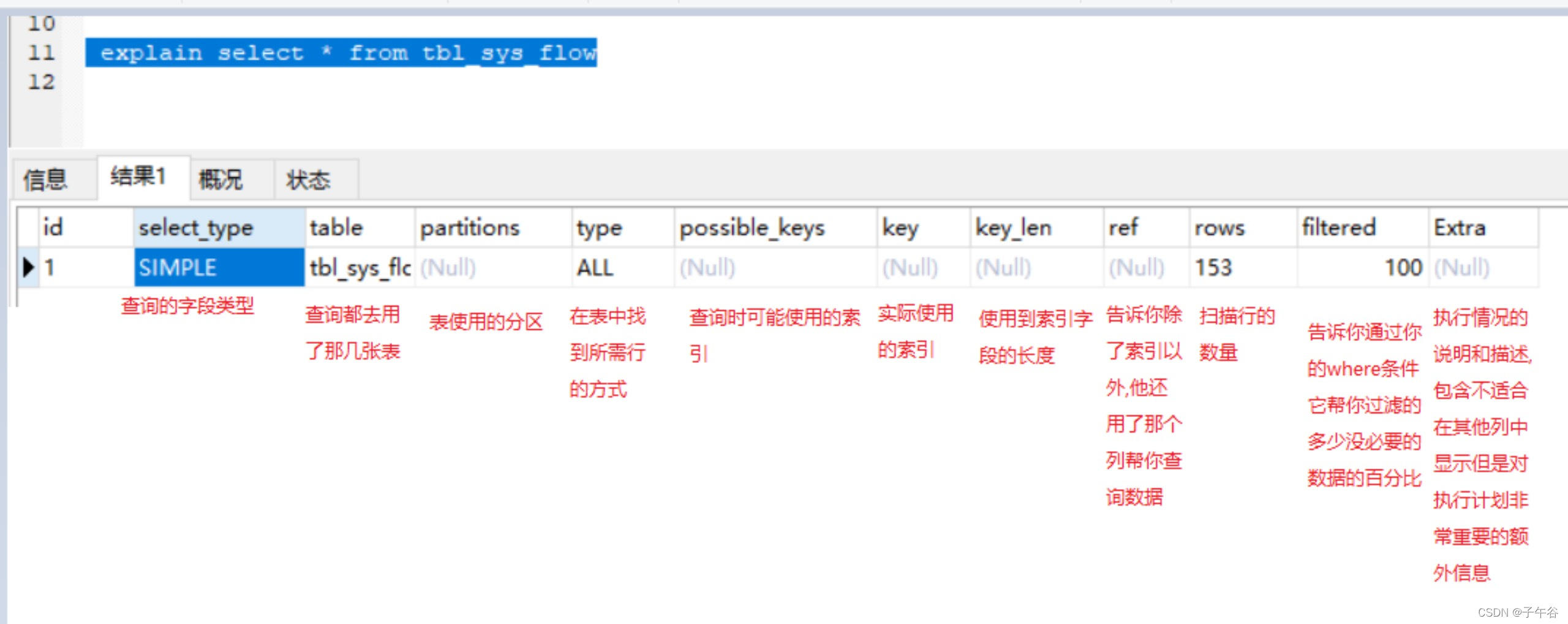
(1)select_type:表示 SELECT 的类型。
常见的取值有
SIMPLE(简单表,即不使用表连接或者子查询)
PRIMARY(主查询,即外层的查询)
UNION(UNION 中的第二个或者后面的查询语句)
SUBQUERY(子查询中的第一个 SELECT)等。
(2)table:输出结果集的表。
type:表示表的连接类型,性能由好到差的连接类型如下
1.system(表中仅有一行,即常量表)
2.const(单表中最多有一个匹配行,例如 primary key 或者 unique index)
3.eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)
4.ref(与eq_ref类似,区别在于不是使用primary key 或者 unique index,而是使用普通的索引)
5.ref_or_null(与 ref 类似,区别在于条件中包含对 NULL 的查询)
6.index_merge(索引合并优化)
7.unique_subquery(in的后面是一个查询主键字段的子查询)
8.index_subquery(与 unique_subquery 类似,区别在于 in 的后面是查询非唯一索引字段的子查询)
9.range(单表中的范围查询)
10.index(对于前面的每一行,都通过查询索引来得到数据)
11.all(对于前面的每一行,都通过全表扫描来得到数据)。
(3)possible_keys:表示查询时,可能使用的索引。
(4)key:表示实际使用的索引。
(5)key_len:索引字段的长度。
(6)rows:扫描行的数量。
(7)Extra:执行情况的说明和描述。
1.Distinct:一旦找到了与行相联合匹配的行就不再搜索了;
2.Using filesort:使用了文件排序,性能非常慢,需要优化。
3.Using index:查询使用到了索引,列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回 的,这发生在对表的全部的请求列都是同一个索引的部分的时候。
4.Using temporary:使用了临时表排序,性能非常慢,需要优化。
5.Using where:表示使用了where进行查询,不是很重要。
6.ALL:这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,需要优化























 1847
1847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









