







 CryptoGuard是一款高精度检测大规模Java项目中加密API漏洞的工具。它采用静态分析方法,结合新颖的切片技术,解决了现有工具在大规模项目上的局限性。通过对16种加密漏洞的深入分析,CryptoGuard展现了其在检测精度和效率上的优势。
CryptoGuard是一款高精度检测大规模Java项目中加密API漏洞的工具。它采用静态分析方法,结合新颖的切片技术,解决了现有工具在大规模项目上的局限性。通过对16种加密漏洞的深入分析,CryptoGuard展现了其在检测精度和效率上的优势。
本文目标:精度论文 “CryptoGuard: High Precision Detection of Cryptographic Vulnerabilities in Massive-sized Java Projects” 。
主要针对大规模的 JAVA 项目,静态分析加密API漏洞。论文发布于 2019 年的 CCS ,点击即可免费获取该工具,作者甚至提供了基准测试。近些年来,这类分析已经不足为奇了,继续探索无疑是为了提高精度,正是因为问题无法完全解决,研究才有了意义。CryptoGuard 提出了一个新颖的解决方向,或许能带给你一个新的视角~
视角一:关于检测分析,你或许想知道这些
为什么需要检测分析?必然是因为我们的系统不够安全。就密码算法而言,它的设计本身就是为了提供可证明的安全保障而存在的,但由于一些底层的漏洞,使得这些算法的安全性大大降低。虽然攻击还未发生,但我们势必要防患于未然,除了培训相关人员、规避舆论误导外,我们技术人员能做的就是对程序进行检测分析。
一个程序的检测分析一般包括静态分析和动态分析。
- 静态分析: 不需要执行程序,可扩展,覆盖广泛的安全规则,并且不太可能漏检。
- 动态分析: 需要执行程序,实时检测,观察特定症状,往往具有更少的误检。
CryptoGuard 选择了静态分析方法,其所谓依据应该考虑到进行实验的目的性。 CryptoGuard 的目标是检测密码API的误用 ,针对的是大规模的 Java 项目,这就使得我们在进行工具的选择时不能随心所欲。考虑到这类项目一般为部署级代码,那么选择筛选工具时就要考虑其弹性。上面介绍过,静态分析可扩展,因此静态工具将具有很强的可伸缩性,这便是 依据 。
但是现状是什么呢?现有的基于静态分析的工具并不能在大规模的 Java 项目中运行(或者说,不够优化),这就是 突破口 。
具体的:现有检测工具检测 SSL/TLS API 受限;不能检测复杂场景。
什么算大规模的 Java 项目呢? 像那种涉及到数百万LoC的程序就算。
(LoC,the Lines of Code,代码行)
既然提到检测分析,就不得不提一下切片技术。
- 程序切片: 识别影响或受程序变量影响的指令集(大概就是将一部分内容单拎出来分析)。
包括前向和后向的程序切片技术,其算法通过使用流(flow-)、上下文(context-) 和字段敏感(field-sensitive) 的数据流分析来实现。
总之,我们需要一个使用了切片技术的高精度、低消耗的静态分析工具,下面就来看看 CryptoGuard 是怎么做的吧!
视角二:凡事儿都要想清楚问题在哪儿
要检测至少得清楚测啥吧,下面我们仔细分析一下,先贴个表:
文章一共检测了16种漏洞,并对其做了分类,我们从简单的分类属性说起吧。
-
选择评测的 密码属性(Crypto Property) 有这么几个方面:机密性、完整性、真实性、随机性。
-
这些密码易受五大 类型攻击(Attack Type) (根据 攻击收益 和 攻击难度 划分 严重级 ):
- 像密钥、密码这样的可预测 常量 不安全。
本文假设任何 常量 或 由 API 调用派生的值 都不安全,这些都是硬编码密码,即便 Android 的 APP 只能访问自己的 KeyStore ,攻击者也可以通过升级越权,因此 严重级:高(H) ; - Java Secure Socket Extension (JSSE) API 定制不当,导致针对 SSL/TLS 的 中间人(MitM) 攻击;
此类攻击收益高、难度低,因此 严重级:高(H) ; - 伪随机数生成器(PRNG) 可预测。
例:java.util.Random 不安全、 java.security.SecureRandom 可预测;
可预测性降低了攻击难度,因此 严重级:中(M) ; - 基于密码的加密(PBE) 的 盐值 易受 选择明文攻击(CPA) 以及 字典攻击。
静态初始化向量(IV) 的密码分组链接模式(CBC) 和 电子密码本模式(ECB) 不安全;
CPA 也降低了攻击难度,因此 严重级:中(M) ; - 密码机制 不够安全,暴力攻击仍未被解决。
像伪造数字签名引起的哈希冲突、pre-image 攻击等能够破坏完整性,因此这部分 严重级:高(H)
一些我们熟知的 密码机制 ——如 MD5、SHA1;64 位对称密码(如 DES、3DES、IDEA、Blowfish);1024 位的 RSA、DSA、DH;160 位的 ECC ;少于 1000 次迭代的 PBE ——都会被暴力攻击,但攻击难度较大,因此 严重级:低(L) 。
- 像密钥、密码这样的可预测 常量 不安全。
(我认为啊,不管是密钥、密码啊,还是随机数、盐值,基本上都是在讲数的问题,或者说,在解决常量的问题)
- 分析方法(Our Analysis Method) 分为 前向切片(↑) 和 后向切片(↓) 。进程间前向切片按需地用于仅数据类的敏感性字段,过程间后向切片一般按需地用于向上传播的敏感性字段。当然,切片需要一套切片标准,后面我们会提到。
ok,分类属性介绍得差不多了,但是计算机要怎么使用这个表呢?首先我们得让程序清楚检测过程,也就是将密码漏洞映射到具体的程序分析任务中去,注意:这个映射过程是手动的,且每个漏洞也只需执行一次。具体步骤让例子来说话吧:
- 第4条漏洞—— Custom Hostname verifiers to accept all hosts ,属于 API 定制不当,我们需要检验主机名是否经历过验证。
参数验证方法一般为 javax.net.ssl.SSLSession ,实现接口为 HostnameVerifier 。
清楚这一系列关系后,我们就可以去对程序切片了,以验证方法的 return 语句 为切片标准,进行 进程间后向切片 。 - 第5条漏洞—— Custom TrustManager to trust all certificates ,也属于 API 定制不当,我们需要检验证书是否有效。
验证方法实现接口为 X509TrustManager 。
我们以验证方法的 Throw 语句 或 抛出异常的类型 为切片标准,进行 进程间后向切片 。
验证证书一般使用 checkServerTrusted ,我们要检查它是否通过 ═▶ 要检查自签名证书是否过期 ═▶ 要通过 getAcceptedIssuers 检查程序是否提供了有效的证书列表。 - 第6条漏洞—— Custom SSLSocketFactory w/o manual Hostname verification ,也属于 API 定制不当,我们需要检测是否正确使用带有正确主机名验证的SSLSocket,也就是说,不能有方法直接使用 SSLSocket 而不执行主机名验证。
我们以验证方法的 return 语句 为切片标准,进行 进程间前向切片 。
我们需要检查 SSLSocket 是否被 SSLSocketFactory 创建 ═▶ 验证方法 HostnameVerifier 会调用 SSLSession 参数,我们要检查这个参数是否被 SSLSocket 影响 ═▶ 验证方法 HostnameVerifier 有返回值,我们要检查这个返回值是否在条件语句中使用(如 if )。 - 第15条漏洞—— Insecure asymmetric ciphers (e.g, RSA, ECC) ,属于密码机制不够安全,我们需要检测不安全的非对称密码配置(例:1024位的RSA),这是最复杂的一项检查。
我们使用 前向切片 确定密钥大小是显式定义的还是默认定义的;使用 两轮后向切片 确定密钥大小的静态定义以及密钥生成算法,其中对仅数据类的敏感性字段要采用按需后向切片。 - 其他规则的映射都可以从表中推导出来。比如说,第1条和第2条中的 ↑ 表示要使用 进程间后向切片 ,↓ 表示要使用 进程间前向切片,按需要用于仅数据类的敏感性字段。
一些切片标准如下:
标准 Java API 的实现方法及其相应的切片标准(使用 进程间后向切片) ——
 标准 Java API 的实现方法及其相应的切片标准(使用 进程间前向切片) ——
标准 Java API 的实现方法及其相应的切片标准(使用 进程间前向切片) ——

标准 Java API 的实现方法及其相应的切片标准(使用 进程间后向切片;粗体表示值得关注的参数) ——
 有了这个表,计算机就清楚问题所在了,接下来说说切片细节以及实验难点。
有了这个表,计算机就清楚问题所在了,接下来说说切片细节以及实验难点。
视角三:细枝末节的切片技术
重新声明主题——针对大规模的 JAVA 项目,静态分析加密API漏洞。上一节我们介绍了一张漏洞描述表,根据这张表,我们就可以展开分析工作了。
可以发现作者划分了16个漏洞类别,这16类漏洞需要用不同的程序分析方法来检测,也就是说,这不是一个通用切片能解决的事情,所以,切片方式也很重要。总体来说,对一个程序进行切片分析,首先要用 def-use 属性判断是否进行切片,确定切片后,需要给定一个 切片标准 ,以此进行 后向切片 或 前向切片 。
💨def -use 分析计算进程内切片语句
一般为数据流分析,分析识别程序语句,并描述它们之间的依赖关系。
💨 切片标准 很重要 ,它的选择会直接影响分析结果,这应该是切片分析的起点。
🔘切片标准一般是一条语句,或者语句中的一个变量,甚至是 API 的一个参数。
🔘选择切片标准时,我们会考虑这段代码与漏洞的相关性、其检查规则的简单性,以及其是否在多个项目之间共享。
具体的切片标准以及其对应的 API ,在上一节最后的三个表格中有详细说明,这里不再赘述。
💨 后向切片 ,从数据流的角度来说,其标准能够影响到的语句都要切片(起点)
🔘表中的 ↑ 表示使用后向切片。
🔘其切片标准一般被定义为:某目标方法所调用的参数;赋值(变量);throw 及 return 语句。
🔘比如说,对于像密钥、密码这样的可预测常量(表中第1-3条描述的漏洞),其切片标准为 SecretKeySpec 的构造函数的参数 key ;对于与 API 相关的主机名验证器(表中第4条描述的漏洞),其切片标准为 return 语句。
🔘目的:加强安全性;作为构建块。
🔘关于某语句是否应该包含在切片中,由该语句的 def-use 属性来确定。本文利用了Soot框架的工作列表算法。
🔘遇到正交方法,调用递归切片。这里可能要预配置一个切片递归深度,这个我们下一节会分析。
🟠按需进程间后向切片算法主要步骤为:使用类层次结构分析,构建 call 图 ═▶ 识别切片标准中所有方法的调用点 ═▶ 调用点递归成调用链 ═▶ 程序字段级敏感,从语句初始化赋值开始,递归跟踪被字段影响的语句/变量。
(为了在安全代码区域内限制进程间后向切片,从加密api开始分析,递归地跟踪它们的影响。这种方法有效地跳过了大量的函数代码,极大地加快了分析速度。)
💨前向切片 ,从数据流的角度来说,能够影响到其标准的语句都要切片(终点)
🔘表中的 ↓ 表示对按需仅数据类的敏感字段使用前向切片。
🔘其切片标准一般为:赋值指令;常数。
🔘比如说,对于无主机名验证的 SSLSocketFactory (表中第6条描述的漏洞)和弱非对称加密(表中第15条描述的漏洞),其切片标准为赋值语句,且被限制在了一个方法内,不需要考虑跨进程的问题。
🔘前向切片对后向切片产生被访问方法的有序集。(前向切片可能会处理后向切片过程中的调用链)
🔘切片过程与后向切片操作类似,这里主要介绍仅数据类:
🟠仅数据类是只在正交方法调用中可见的类,此类使用前向切片。首先通过判断是否使用了间接调用,以此来判断该类是否为仅数据类 ═▶ 接着,判断常量是否影响这个仅数据类的任何字段,并记录详情 ═▶ 报告影响到 return 语句的常量,还要判断常量是否为硬编码的 key。
比如下图,我们要判断常量 mytext 是否为硬编码的 key 。首先 $r1 是一个仅数据类,因为它是通过正交方法 getKey() 调用而间接访问类内常量 key 的;我们发现常量 mytext 或许影响类内常量 text 的值,但并不影响类内常量 key 的值;可以推断出常量 mytext 不影响返回值 key ,由于常量 mytext 不需要分析,所以我们认为它不算硬编码。

💨 工具使用
输入:切片标准(一条语句或语句中的一个变量);
后向切片程序输出:一组影响切片标准的程序语句;
前向切片程序输出:一组受切片标准影响的程序语句;
~
输入:一个程序和一个切片标准;
输出:一个程序切片列表;
💨 实验难点——2个问题:误报问题、代码量过大
🔘 误报 :
1)未打包的、需要动态加载的二进制库。这种会被称为幻想库,静态分析时容易由于检测不到此类库而误报。(下一节会详细介绍去除无用值的方法);
2)存储常量的数据结构(中的一些标识符、描述符等)。程序会把这部分也当作硬编码,认为它不安全。(下一节会详细介绍丢弃数据结构常量的方法);
(我们常常认为常量都不安全,所以会针对一些硬编码的语句/变量,但其实有些硬编码对系统的影响不大,所以我们要把这部分无用值去掉。)
🔘 代码量过大 :
1)有太多的常量(下一节会详细介绍控制正交深度的方法);
2)存在无用的内容(本节内容的按需切片细节就可以解决这一问题);
3)jar包(.jars)太多(通过构建DAG图来解决,DAG——有向无环图);
切片过程应该基本清楚了吧!但本节还有很多未解决的问题,这些问题将在下一节中详述。
视角四:误检?漏检?
重申这篇文章的主旨——制作一个优化的静态检测工具。根据上一节末,我们清楚检测要解决 硬编码误报 以及 代码量过大 的问题。本节主要介绍作者设计的 针对误检的优化算法 。(Refinement Insights,RI)。
什么算误检?检测了与安全无关的指令。
误检判断依据:通过观察常见的编程习惯和语言限制。
首先有一个检测的大范围:硬编码及其派生的数据都不安全。(如密钥、密码、初始化向量(IVs)、随机数等,即常量/可预测值)
前面提到,其实有些硬编码对系统的影响不大,或者说,不影响系统安全性,我们称这部分为 伪影响 ,这是误检的一个主来源,因此我们要优化算法,作者对此提出以下5个策略:
💨 RI-I: 删“状态”——删除状态指示器 ,丢弃在正交方法调用期间用于描述变量状态的常量/可预测值; 【💥裁剪正交方法】
💨 RI-II: 删“标记”——删除资源标识符 ,丢弃在正交方法调用期间作为资源标识符的常量/可预测值; 【💥裁剪正交方法】
💨 RI-III: 删“计数器”——删除记账索引 ,丢弃用作任何数据结构的索引或大小的常量/可预测值,即数组/集合实例化的 size 参数、数组索引、集合索引; 【感知数据结构】
💨 RI-IV: 删“无关语义”——删除上下文不兼容的常量 ,丢弃类型与上下文不兼容的常量/可预测值,如 bool 类型的变量(因为它不可能用作key、IVs 、salt ); 【裁剪正交方法】
💨 RI-V: 删“无效路径”——删除使用在无效路径中的常量 ,丢弃对切片标准没有有效影响的路径上(更新)的初始化常量,因为一些常量的初始化是沿着切片标准的路径更新的。 【裁剪正交方法】
RI-I 、RI-II 和 RI-IV 用于处理裁剪正交方法探索,这可能由于调用了幻像方法或在某个深度的裁剪预配置引起的;
RI-III 用于实现数据结构感知(观察List、Set等集合,删size、索引、以及影响他们的参数);
RI-IV (例子已经说的很明白了,语义应该是很不好判断的,作者认为 key、IVs 、salt 其相应的 API 只允许二进制数值,一些硬编码 size 参数也只可能是 Integer 类型,其他类型都要丢弃)。
RI-V 用于补偿路径不敏感性(一些常量初始化会覆盖POI(兴趣点),我的理解就是有些变量在程序未运行时保持空字符串或null状态,静态检测会出错,这部分探测分支可以直接删除)。
重点介绍前两个策略,放段示例代码:

💥RI-I:删“状态”——删除状态指示器
直接举例子🌰,示例代码的第 38 行中的 "UTF-8" :
byte [] keyBytes = key.getBytes("UTF-8");
它的 Jimple(Java程序的中间表示) 如下:
$r4 = virtualinvoke $r2.<java.lang.String: byte[] getBytes(java.lang.String)>("UTF-8")
其中 $r2 表示变量 key ; $r4 表示 keyBytes ; virtualinvoke 调用类的非静态方法。
这里会出现什么问题呢?静态检测方法很可能检测不到 getBytes 方法,那么 def-use 分析将标记常量 "UTF-8" ,它会认为 $r4 = "UTF-8" 或者 keyBytes = "UTF-8" 。但 "UTF-8" 只是用于描述 $r2 的编码,是可以安全地忽略它的,这就是一种伪影响。
但这并不代表要丢弃所有的 virtualinvoke 的参数,因为它还有别的用处,比如在 KeyHolder 实例中设置一个常量:
virtualinvoke $r5.<KeyHolder: void setKey(java.lang.String)>("abcd")
常量 "abcd" 就需要被标记。
总的来说,丢弃 含赋值结构的 virtualinvoke 的参数(这一般用于描述变量状态),以及能够影响到这个参数的常量。
💥删“标记”——删除资源标识符
比如,用于 Java Map 数据结构检索值的标识符常量 "ENCRYPT_KEY" ,没必要被标记:
$r30 = interfaceinvoke r29.<java.util.Map: java.lang.Object get(java.lang.Object)>("ENCRYPT_KEY")
直接举例子🌰,示例代码的第 15 行中的 src :
String key = Context . getProperty ( src );
其 Jimple 使用了 staticinvoke 读取外部资源值:
$r4 = staticinvoke <Context: java.lang.String getProperty(java.lang.String)>(src)
变量 src 就是标识符,与 key 的取值关系不大,这也是一种伪影响。
一般,我们丢弃 含赋值结构的 staticinvoke 的全部参数(这一般用于标识,一般不用于转换常量)。
以上,误检的优化算法规则大致如此了。其实,对于误检问题,作者的主要解决思路就是丢弃常量;而对于代码量过大的问题,作者考虑“构树裁枝”,这在上一节的按需切片思想里已经详细说明过。
这些说法总要有些技术验证吧,作者测试并手动确认了 46 个Apache项目以及 6181 Android应用程序,发现最有效的是策略RI-III(删“计数器”——删除记账索引)。可以理解,我们平时用得最多的就是一些数组、集合等,他们带有太多的安全无关的标记量了。
为了测量正交探索深度(正交方法与主切片之间的距离)的影响,作者对 30 个 Apache 根子项目进行了实验,并将裁剪深度从 1 变动到 10 ,鉴于这些观察结果,我们将正交探索深度(切片迭代深度)设置为1,因为它返回的无关常数的数量最少。


现在误检解决策略也已设计完成,接下来就是效果展示啦!
视角五:奔跑吧,CryptoGuard!
实验环境:
Intel Xeon® X5650 server (2.67GHz CPU and 32GB RAM)。
实验过程:
解析构建脚本 ═▶ 执行子项目的依赖关系 ═▶ 分析构建 DAG 。(根子目录在子项目依赖关系上构建的 DAG 无边)
自动加载 gradle 和 maven ═▶ 手动加载 Ant 。
用 Soot 反编译 .apk 文件为 Java 字节码 ═▶ 用在线 APK 反编译器转换为可读源码 ═▶ 手动验证 CryptoGuard 接口。
实验效果:
Apache 项目,平均运行时间为3.3分钟,中值约为1分钟;
Android 项目,有9%(552个)没有在10分钟内完成,大多由于工具的最后一步(规则7:HTTP的使用)没有完成,因此 CryptoGuard 仅产生了部分结果。
实验分析(解决的问题):
- Apache项目中有什么安全问题?是否有高危漏洞?
作者检测了 46 个 Apache 项目,其中 39 个项目至少有一种类型的密码错误,33个项目至少有两种类型的密码错误,安全问题如下表:

【密码可预测】
源代码中的硬编码 key/password 。16 个 Apache 项目(37 个子根项目)存在此类问题,像硬编码的对称密钥、混淆视听的 DESede (即 Triple DES )、 AES 加密,由于确定性键的存在,这种混淆变得微弱,这些密码也变得易受攻击。更甚,在 Apache Cloudstack 中,使用硬编码 key 的测试代码与生产代码打包在了一起。
配置文件明文存储。PBE 中的大多数硬编码密码都是默认值,最常见的有 masterpassphrase 、NowIsTheTime 。一旦攻击者具有 PBE 密文访问权限,他就可以很轻易地恢复明文密码。Apache Ranger 就使用了硬编码密码作为所有发行版 PBE 的默认值,连维基百科都没有提及其安装,那么对于这一设置不够了解的系统管理员就不会时常更新默认值,这大大削弱了PBE的安全保障。
另外, KeyStores 中存储私钥的最常见的硬编码密码是 changeit 和 none,大多都是默认设置好的,这种编码风格始终是不安全的。
总结 Apache 项目中的不安全问题:
1)源代码硬编码 key/password ;
2)配置文件明文存储 key/password ;
3)配置文件存储加密的密码(password),并以明文形式解密密钥(key)。
即便 Java 提供了一个特殊的安全 API (例如,Callback 和 CallbackHandler ),用来提示用户是否有私密信息,但这些被检测的项目并不支持此选项。因此,他们的系统管理员不得不将明文密码存储在文件系统中,使得这些代码只有他们自己可以修改,这对用户不透明且不安全。
【中间人攻击】
来自SSL/TLS 的中间人(MitM)漏洞,其风险是最高的。5 个 Apache 项目(8 个子根项目)的主机名验证接受任何主机名;6 个 Apache 项目盲目信任任何证书。事实上,大多数项目都将这些作为附加的连接选项,一些示例如下:

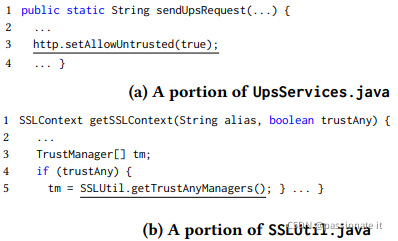
在不同的攻击模型下,风险级别可能不同。
有 4 个项目使用了硬编码的盐值,包括 Apache Ranger 等。
使用 ECB 模式 AES 的5 个项目,其中 2 个项目使用了可预测的 IV ,共出现 40 次。
有 5 个项目使用了少于 1000 次迭代的 PBE ,甚至有些只使用了几十次迭代,比所需的 1000 次少得多。
展示一个存在问题的 Ranger 代码片段:

第6行可以发现,该迭代次数与密码的大小成比例,而我们知道,我们使用的密码大小远远小于 1000 次。另外,通过度量 PBE 执行时间这样的侧信道攻击,攻击者可能会猜测到密码的长度。这些信息都大大降低了字典攻击的难度。
第2-3行明确了该项目的密码使用了带盐值的 MD5 哈希加密。很多平台通过加盐值增大密码的复杂度,但同时,盐值引起了很多问题,攻击者如果获取到盐值,就可以迅速破解密码,另外,带盐值的密码变得特殊,没有了不可区分性,这使得 PBE 不能抵抗选择明文攻击。
作者还发现了显式初始化 key 、使用 java.util.Random 的 PRNG 等,这些在前面也提到过其危险性。
- Android应用程序中有什么安全问题?第三方库有高风险漏洞吗?
我们通常通过使用 AndroidManifest.xml 的包,来区分应用程序自身的代码和第三方库代码。而 Android 为了增大混淆,在 R.java 文件的生成过程中也使用了这一点。作者检测发现, 平均95%的漏洞来自第三方库 (见下表):

可以发现,几乎所有的 KeyStore 硬编码密码漏洞问题,都是由库引起的。最常见的 KeyStore 硬编码密码就是 notassecret ,它用于访问谷歌库中的证书和密钥
如:
*.googleapis.GoogleUtils,*.googleapis.*.GoogleCredential
其他知名库源也存在类似问题。
CryptoGuard 可以检测混淆包中的 API 误用,也就是说,混淆代码中的任何违规都会被报告,除了混淆库的供应商。
【与 Apache 项目的对比】
与上面 Apache 项目的漏洞总结表类似,它也总结了 Android 应用程序中发现的漏洞:

不可信 PRNG 和 Broken Hash 有最多的违规。对于第8条,在作者检测的 544 个例子中,其中有 13 例使用了 <java.lang.System: long currentTimeMillis()> 的 API 调用。
与Apache项目相比, Android应用程序有更高比例的 SL/TLS API 误用和 HTTP 的使用 。就比如第5条的证书验证漏洞,Android 项目就比 Apache 项目多了一倍的占比。
【与 Google Play 的对比】
Google Play 有内置检测,但它只能检测到比较明显的 API 误用,而错过一些复杂的情况。就比如:

上述情况,开发人员仅需通过一个过期检查,就可以允许证书自签名。Google Play 会错过这种误用,而 CryptoGuard 可以检测的到。

再者,开发人员会忽略 checkServerTrusted 方法中抛出的异常。

另外,可以发现,项目在 WebSocketClient 中使用了 SSLSocket ,CryptoGuard 在 210 个应用程序中检测到 271 次未进行手动主机名验证而使用了 SSLSocket 的错误情况,但 Google Play 会错过。
- 在基准测试或真实项目中,CryptoGuard与CrySL、SpotBugs和Coverity的免费试用版相比如何?
【基准测试】
构建用于比较加密漏洞检测工具质量的综合基准 CryptoApiBench ,点击查看Github的最新版本。
没有使用现有的基准 DroidBench 的原因:
1)它没有覆盖到加密 API ;
2)Coverity 的免费 web 版本需要源代码,但 DroidBench 只包含 APK 二进制文件。
CryptoApiBench 涵盖了上述 16 个加密规则,每个规则和每个 API 的测试用例分布如下:
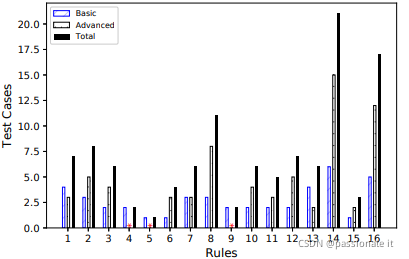
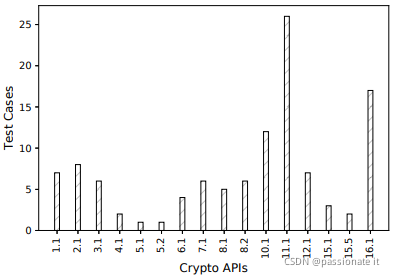
由于缺乏文档,作者根据工具是否在该类别中生成警报来推断工具的覆盖范围,结果显示如下:

SpotBugs、Coverity 以及 CryptoGuard 在基本基准测试中表现良好。
对于 CrySL ,其错误部分是由于它们的规则定义过于具体。就比如说:
- CrySL 不允许加密密钥不直接通过密钥生成器获取,但某些情况下,我们不需要密钥生成器,也可以在代码中安全地使用先前生成的加密密钥;
- 另外,CrySL 不允许加密密码从 string 派生,这可能是因为 Java 建议使用 char[] ,以便密码在使用后易被清除,但这种基于 string 的策略会丢失在 char[] 中定义的硬编码密码,从而误报。
比较结果如下:

作者随机选择了 30 个 Apache 根子项目( LoC 从 471K 到 1K )和 30 个 Android 应用( LoC 从 471K 到 1K ),比较了 CrySL 和 CryptoGuard ( LoC 从 1453k 到 0.4K ),每次运行3次,总结结果如下:

按 LoC 排序的完整的运行时详细信息:

LoC 排序:

对于 Apache 项目来说,CryptoGuard 的总体运行时性能比 CrySL 更好。
对于 Android 项目来说,CrySL 更快,部分原因是 CrySL 只分析应用程序生命周期中可访问的代码,而 CryptoGuard 还涵盖了第三方库(不管生命周期的可达性如何),并生成更多有效的警报。 CryptoGuard 尚未分析使用了 MD5 的来自 Android 核心库 com.google.android 的误报。
关于 Coverity 的免费 web 版本,作者未获得它的运行时间。
作者选择不与 SpotBugs 作对比。因为它的分析主要是基于源代码与已知错误模式的语法匹配,所以作者认为这种比较没有意义。
总结研究结果, CryptoGuard 对 SSL/TLS API 误用的检测比 Google Play 提供的内置检测更全面。

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









