









详细报错信息如下: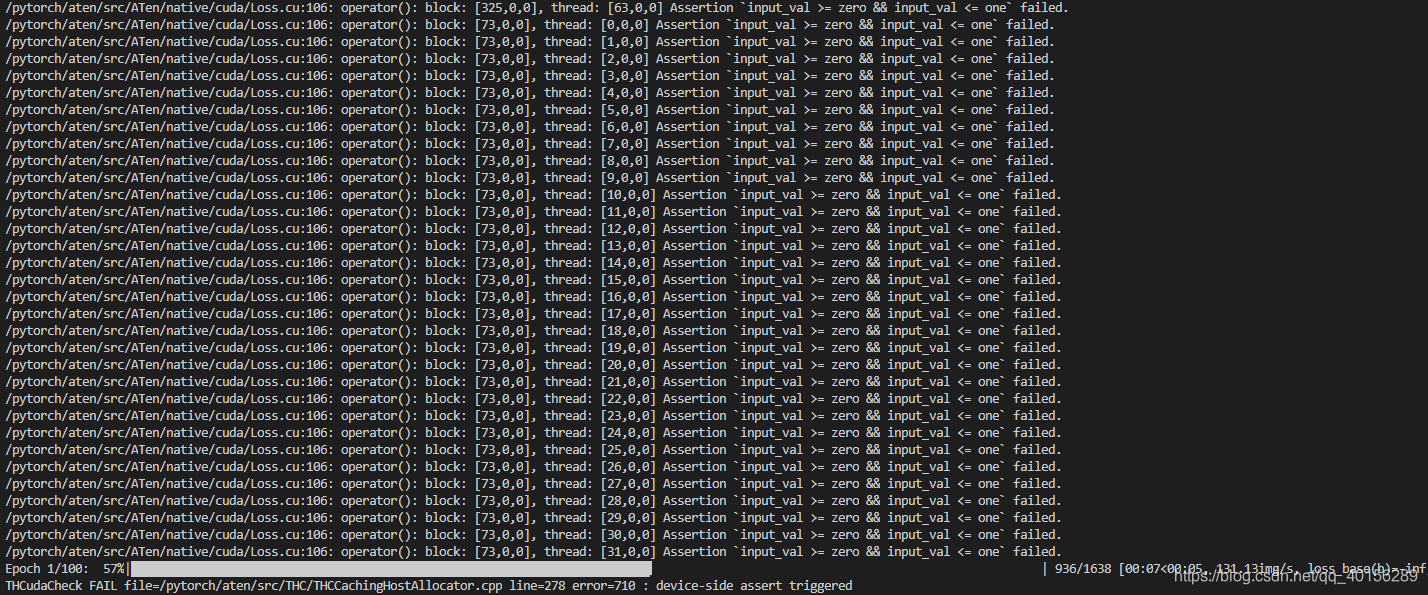
关键错误为:
/pytorch/aten/src/ATen/native/cuda/Loss.cu:106: operator(): block: [73,0,0], thread: [30,0,0] Assertion input_val >= zero && input_val <= one failed.
THCudaCheck FAIL file=/pytorch/aten/src/THC/THCCachingHostAllocator.cpp line=278 error=710 : device-side assert triggered
除此之外还有一个错误信息:
loss_base(b)=-inf
错误原因分析
- 错误定位:
网上大多数解决方案均是检查标签是否越界,如报错信息所知确实说的就是这个问题,有一些童鞋确实是标签问题,但是也有不是的,比如我。另外我这里还有一个额外的错误信息就是报错时的loss值为负无穷,这是不正确的,且必然会导致程序出错误,我不知道标签越界的那些同学是否有这个错误,至少我的有。因此经过排查,我并不是由于标签越界导致的,而是由于loss计算中的数学错误导致的该错误信息。 - 具体原因:
我的loss计算其中一个过程是这样的:torch.log(torch.sum(F_loss))而我在出现上述错误地方的loss值为-inf,也就是负无穷大,因此可知torch.sum(F_loss)的计算结果为0时,0的对数值为负无穷大,因此程序就出现了问题,就导致了上述报错。 - 不过尚不知道为何这个数学问题为何会报这个错误信息。
解决方法
在python前增加命令CUDA_LAUNCH_BLOCKING=1通常可以看到错误原因。
为防止取对数的值为0,需要加一个接近0的值(如:1e-6)就可以了
例如:torch.log(torch.sum(F_loss) + 1e-6)
另:还会报类似错误的其他问题
如:当在两类别分割中,未在BCELoss前使用torch.sigmoid()输出时也会报类似错误。
RuntimeError: CUDA error: device-side assert triggered
update
如果在索引下标超出边界时,也同样会报错。
总结
基本上该类问题除了标签值不正确外,可能大部分与loss计算有关,因此在写代码的过程还是要注意下细节,如还有其他不同的问题导致这个错误,欢迎大家评论补充。















 6053
6053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









