






文章目录
[2020 NIPS]Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
- 作者:Jaehyeon Kim
- 韩国Kakao Enterprise
abstract
- motivation:不需要额外的对齐,高度并行化
method
- 认为文本
c
c
c可以转换到对应的mel spec ,记为
x
x
x。两个用相同的分布约束,P(Z|c)用encoder 先验概率表示,P(Z|X)也成立,因此使用
D
−
1
D^{-1}
D−1,即使用z的分布约束x,后验概率。因此,D需要设计成一个flow。
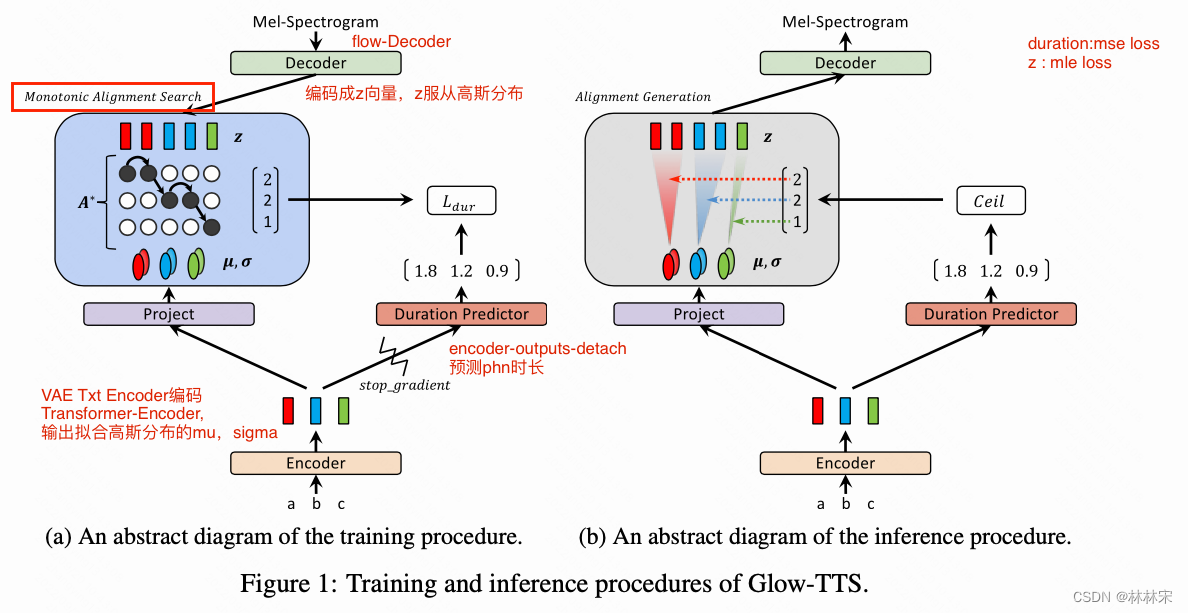
- Encoder:将文本进行编码,编码后的向量符合高斯分布,求均值方差 μ , σ \mu, \sigma μ,σ;Encoder采用transformer-encoder的结构(slf-attn + feed forward conv)
- Decoder:flow的结构,将mel spec编码成符合高斯分布的 z z z向量;
- 通过动态规划算法找到mel spec和txt之间的对齐矩阵 A A A 。通过语音合成的先验知识,可以限制对齐矩阵为单向对齐。
- 训练阶段:需要训练模型的参数 θ \theta θ 以及最大对数似然的对齐矩阵 A ∗ A^* A∗,对齐的结果同时训练一个额外的duration predictor。
- 预测阶段:模型参数已经固定,对齐矩阵不再需要,直接从duration predictor中拿到音素时长,展开合成。
Monotonic Alignment Search

[2021 ICML] VITS-Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
- Jaehyeon Kim
- github实现
abstract
motivation:一次性txt2wav,避开两阶段训练的mismatch,提高合成的自然度
基础知识补充
- 先验分布:从大量数据中得到统计规律。
- 后验分布: 已经知道结果,推断原因。
- 先验概率 P ( θ ) P(\theta) P(θ)
- 后验概率 P ( 因 ∣ 果 ) = P ( θ ∣ x ) P(因|果)=P(\theta|x) P(因∣果)=P(θ∣x)
- 似然估计:先定下来原因,根据原因来估计结果的概率分布即似然估计。 P ( 果|因 ) = P ( x ∣ θ ) P(果|因) = P(x∣\theta) P(果|因)=P(x∣θ)
method
- posterior encoder + decoder也是一个VAE,z可以重建KaTeX parse error: Expected group after '^' at position 2: y^̲,
- z 经过flow变换,成
f
θ
(
z
)
f_{\theta}(z)
fθ(z),是对z的缓冲,保证两条支路的变换都有效果。
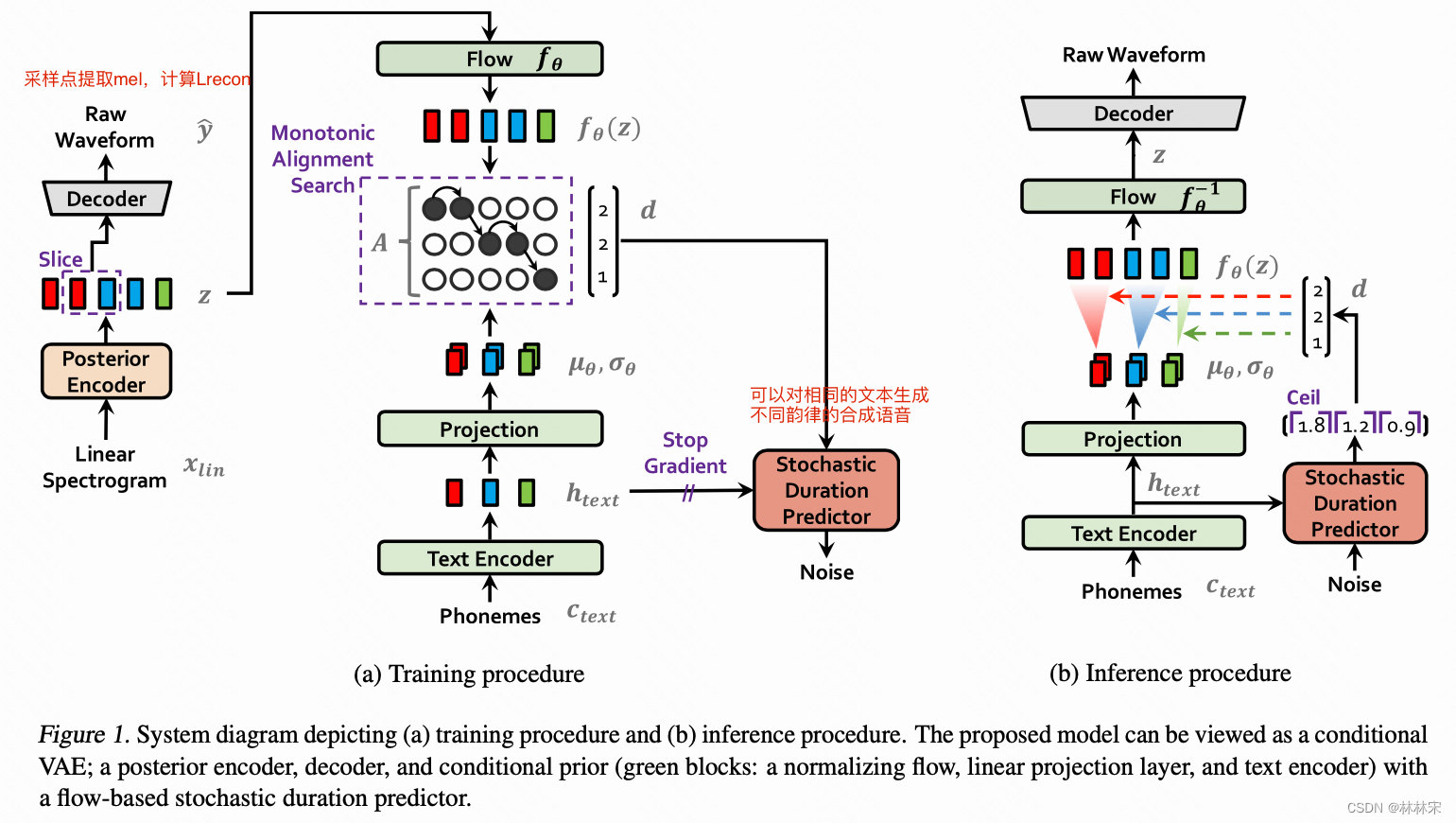
- 从Glow-TTS演变而来,但是依赖的原理和实现有改动。
- Text Encoder:依然是从phn序列编码得到的 h t e x t h_{text} htext,然后卷积计算得到 μ , σ \mu, \sigma μ,σ。先验Encoder, 从数据中得到分布。
- Flow :原来的decoder部分,将z向量编码成 f θ ( z ) f_{\theta}(z) fθ(z)
- Posterior Encoder:从线性谱中编码出高斯分布的 z z z向量, z z z向量经过flow变换之后要符合 μ , σ \mu, \sigma μ,σ的高斯分布,已经知道结果求参数,所以是后验编码。
- Deocder:HiFiGAN V1的结构,每次从 z z z中采部分,用于采样点的生成,然后采样点再提取mel spec,用重建损失约束。是一个vocoder,本身也会用gan loss对生成结果进行约束。
- 对齐矩阵 A A A:和Glow-TTS的计算方式一致。
- Stochastic Duration Predictor : 预测时长,flow结构,预测离散的时长。具体的操作见flow++。

20240423记录
- 训练的过程中,通过MAS做动态搜索,找到text和linear spec之间的长度对齐关系,对text 进行扩帧,这一段是没有参数参与梯度回传的;通过动态搜索的结果,用于训练duration predictor【单独的模块,梯度不会回传给text encoder】;MAS的搜索过程会耗时,但是相对于整个系统的计算量不足2%,可以接受,而且infer阶段因为没有文本对应的linear spec,这个模块已经不复存在;相当于模型训练一个匹配的MFA,会比外挂MFA直接用结果更准确,更soft一些;
- 推理阶段: h t e x t h_{text} htext送给duration predictor,预测音素时长,类似于fastspeech的推理阶段;
- 几种不同的生成式模型:VITS是VAE-Based系统,优化问题是逼近最优对数似然的下界;Glow-TTS是flow问题,优化问题是明确的最大对数似然。GAN是通过判别器来辅助生成器学习目标数据分布,是一个基于对抗学习的生成式框架,没有具体的似然表达式;Diffusion模型它更像是自回归的VAE模型,它学习的也是目标对数似然的下界, 只不过Diffusion的后验编码器是无参的,而VAE的后验编码器是含参的。















 2737
2737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









