









 论文介绍了一种结合VAE、GAN和FLOW的端到端TTS模型,通过归一化流程和对抗性训练增强生成能力,提出随机持续时间预测器处理不同节奏。模型通过MonotonicAlignmentSearch实现文本和音频的对齐,以及包含鉴别器的复杂损失函数设计。
论文介绍了一种结合VAE、GAN和FLOW的端到端TTS模型,通过归一化流程和对抗性训练增强生成能力,提出随机持续时间预测器处理不同节奏。模型通过MonotonicAlignmentSearch实现文本和音频的对齐,以及包含鉴别器的复杂损失函数设计。
论文名称:Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech(ICML 2021)
论文地址:https://proceedings.mlr.press/v139/kim21f/kim21f.pdf
论文源码:https://github.com/jaywalnut310/vits
demo地址:https://jaywalnut310.github.io/vits
下面主要讲一下模型中各个板块的结构及作用、loss的计算。
(模型使用了VAE、GAN、FLOW三种生成模型,可以在上一篇文章三种生成模型(GAN、VAE、FLOW)进行大概了解)
一、主要贡献
- 提出了一种并行端到端 TTS 方法,该方法可生成比当前两阶段模型更自然的音频。
- 采用通过归一化流程和对抗性训练过程增强的变分推理,提高了生成模型的表达能力。
- 提出了一个随机持续时间预测器,用于从输入文本中合成具有不同节奏的语音。
- 所提出的方法表达了自然的一对多关系,其中文本输入可以以不同的音调和节奏以多种方式说出。
二、方法架构
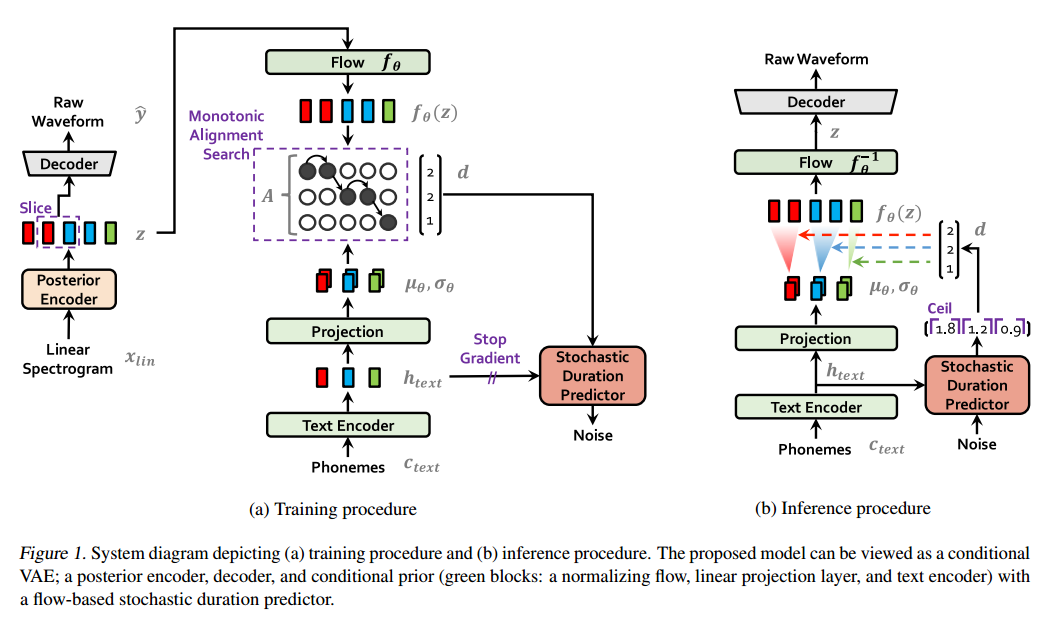
2.1结构分解
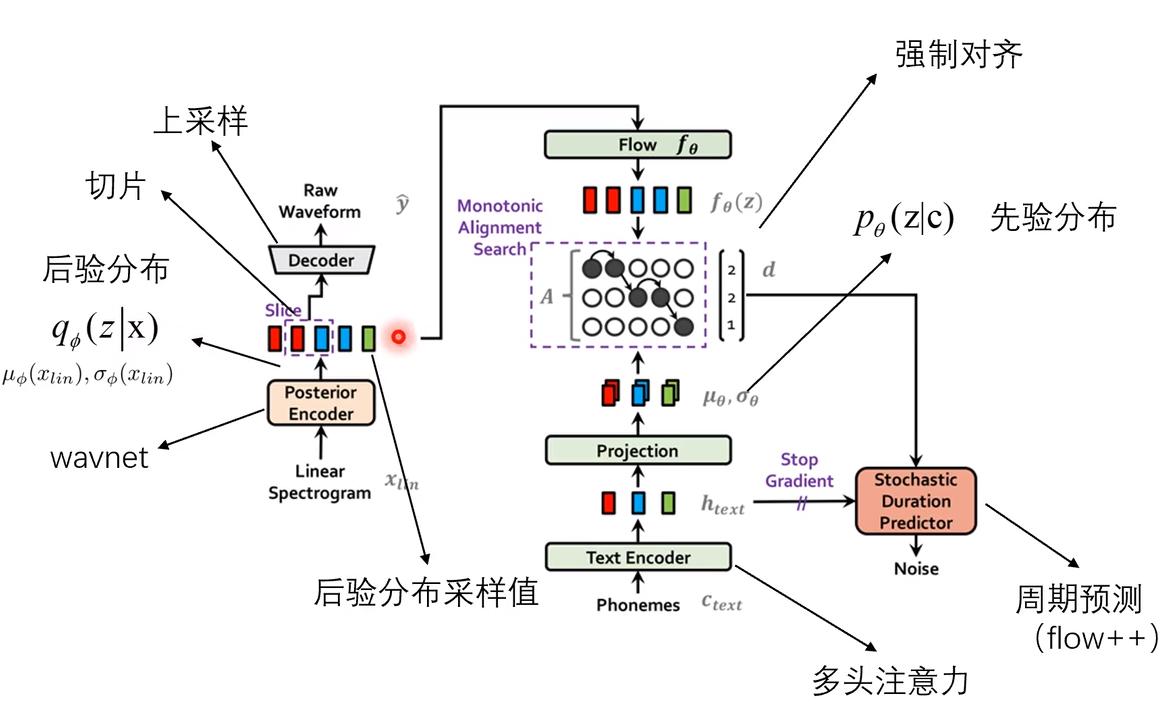
音频信息输入:语音数据的梅尔频谱,语音数据的短时傅里叶变换得到。通过编码器(WaveNet)得到隐变量z的后验分布。
Posterior Encoder:WaveNet模型。
Decoder:即HiFiGAN的生成器。直接生成原始的音频数据,而不是生成梅尔频谱等中间特征,不需要单独训练声码器进行解码。
Flow:相当于从后验分布q转换到先验分布q的一个转换函数f,增加信号的表达能力。
Monotonic Alignment Search:使语音和文本的向量序列的长度对齐相等。
Text Encoder:实际是多头注意力transform结构,将输入的文本转换为音素序列,然后转换为向量序列。
Projection:即一个映射层,基于向量序列得到的先验分布的参数
,
。
Stochastic Duration Predictor: 也是使用Flow模型进行周期预测。
Discrminator:最后还有一组鉴别器,来鉴别生成的Raw Waveform与真实的原始音频波形。
2.2稍详细介绍
2.2.1变分推断(Variational Inference)
由于音频序列和文本序列长度不一样,导致两者无法计算KL散度,所以需要对其进行强制对齐。
通过计算KL散度来最大化条件下界(ELBO) :
c即为文本条件(具体推理过程可以参考文章三种生成模型(GAN、VAE、FLOW))
2.2.2强制对齐
Monotonic Alignment Search,与TDW算法类似。
详细过程参考文章DTW(动态时间调整)算法原理-CSDN博客,区别在于:
- 不同于之前找最小距离,最大化输入文本和目标语音之间的对齐度 A。即不同于找左下三点的最小值,现在找左下三点的最大值。
- 一个文本可以对应多个音频,但是一个音频不能对应多个文本。即找左下三点的最大值又变成左边两点。
-
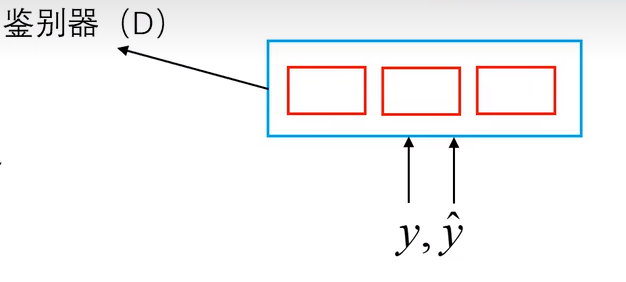
2.2.3判别器D
- 还添加了一个判别器D来识别生成器G产生的输出和真实波形y(生成器G指整个模型)
- 注意:输入的是长音频分割的每一小段,然后使用一组D而不是一个D,让每一个D的输出都接近1,而且还要对鉴别器D每一层中间的输出都要相似。
三、损失函数loss
- 音频重构损失的计算需要将梅尔频谱和波形都变成滤波器组Fbank来进行计算。
- 强制对齐后计算KL散度作为另一个loss。
- 希望真实的数据进去等于1,生成的数据等于0。每一个鉴别器D的输出都接近1,而且鉴别器D每一层中间的输出都要相似。
- 计算
,通过单调对齐搜索算法(MAS), 获得文本编码后预测的均值方差和隐变量 z 通过Flow后得到的正态分布的最优对齐矩阵,使其似然值最小。
总损失函数:
注意:输入的音频每次都不一样有长有短,因此对输入的音频都会进行切片处理(并不会对所有音频进行encoder,而是对其中一小段)所以音频重构损失与生成器鉴别器的损失都是对切片计算。

















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









