






- 2023.3
- meta AI
method
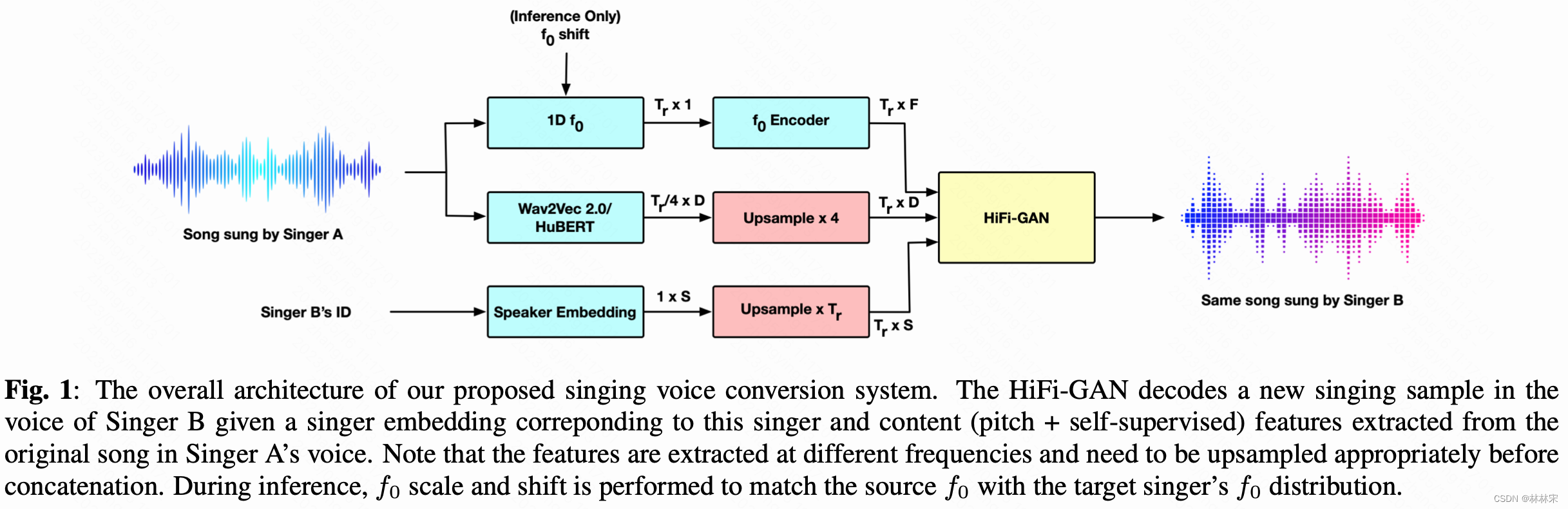
-
本文更偏向于多个维度实验之后的经验分享,实操性还是比较强的
-
hubert提取content embedding,这里使用的hubert-emb不是预训练的特征,而是hubert模型经过ASR数据finetune的特征。但是实验证明,finetune之后的音色解耦明显优于pre-train model,但是还是有残留;
-
f0经过f0-encoder得到更多的谐波表征,infer阶段会进行shift。因为speaker embeddding实际上也建模了说话人的基频分布,直接使用src_f0,结果会差一些。假设 f A f_A fA和 f B f_B fB都是高斯分布。
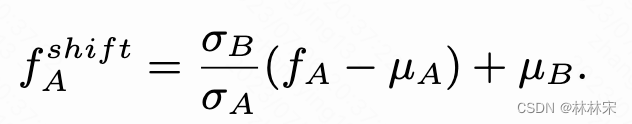
-
speaker-emb经由LUT之后,三种特征拼接在一起送入HiFiGan.
-
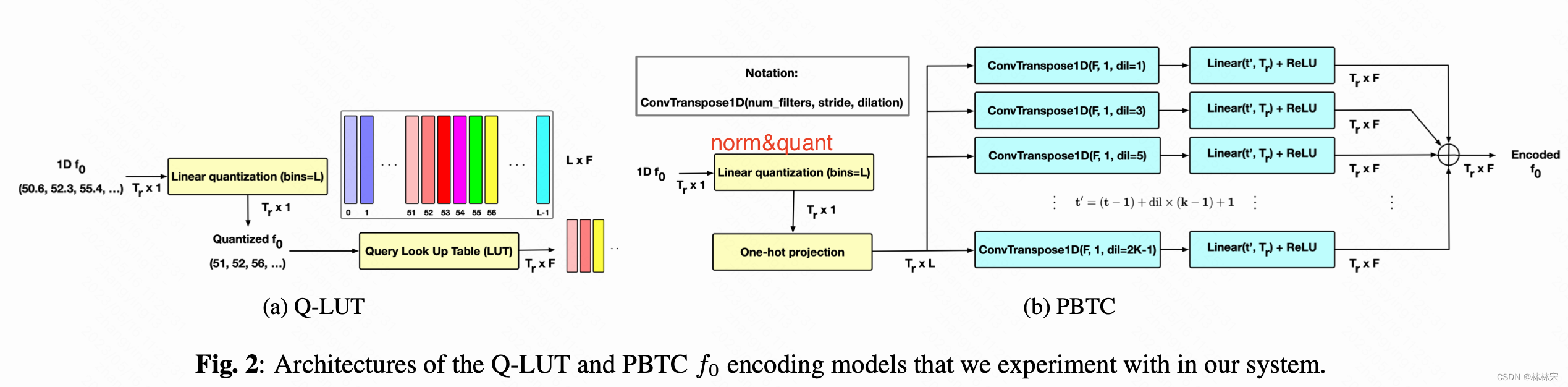
基频处理的方式如下图
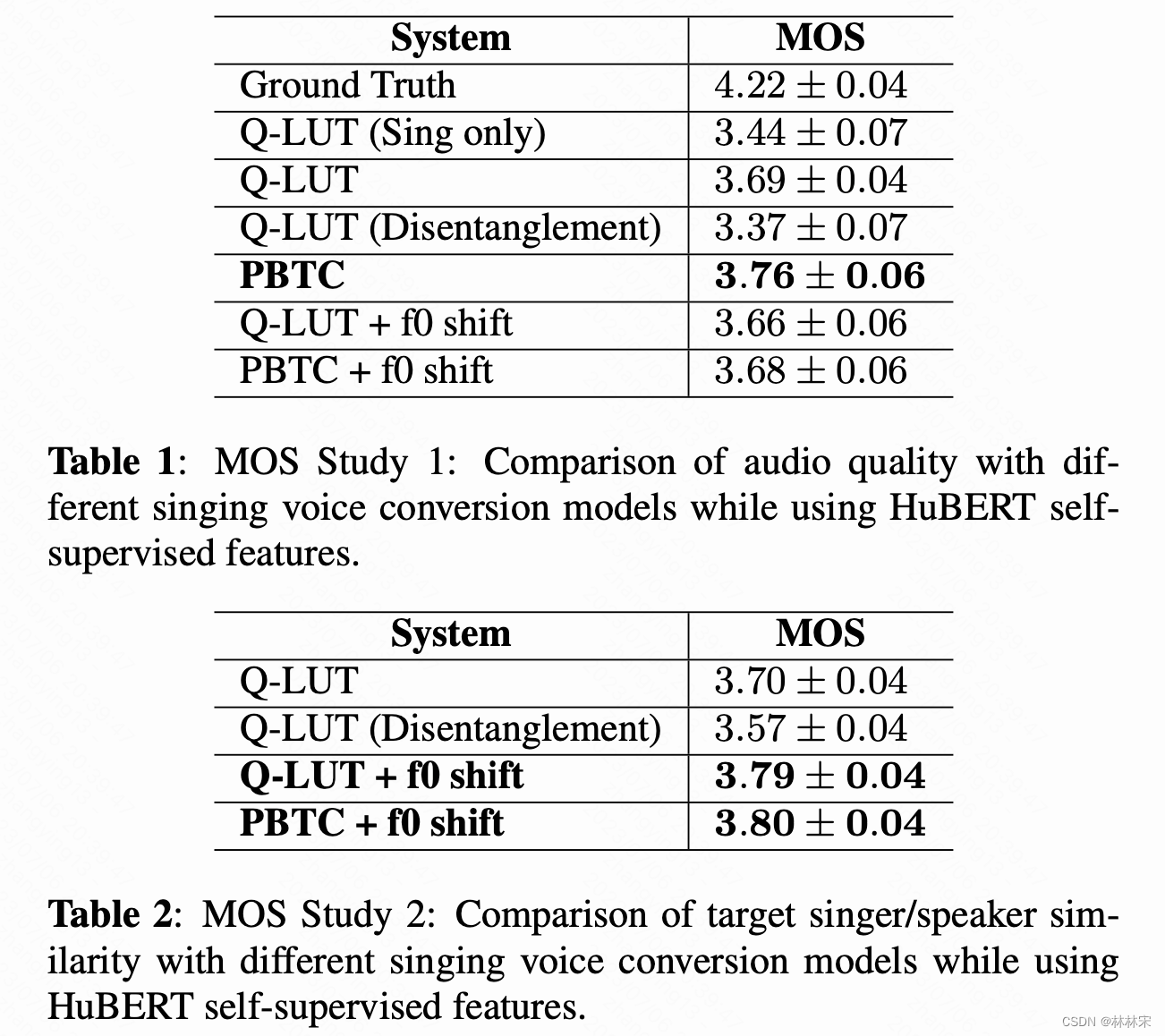
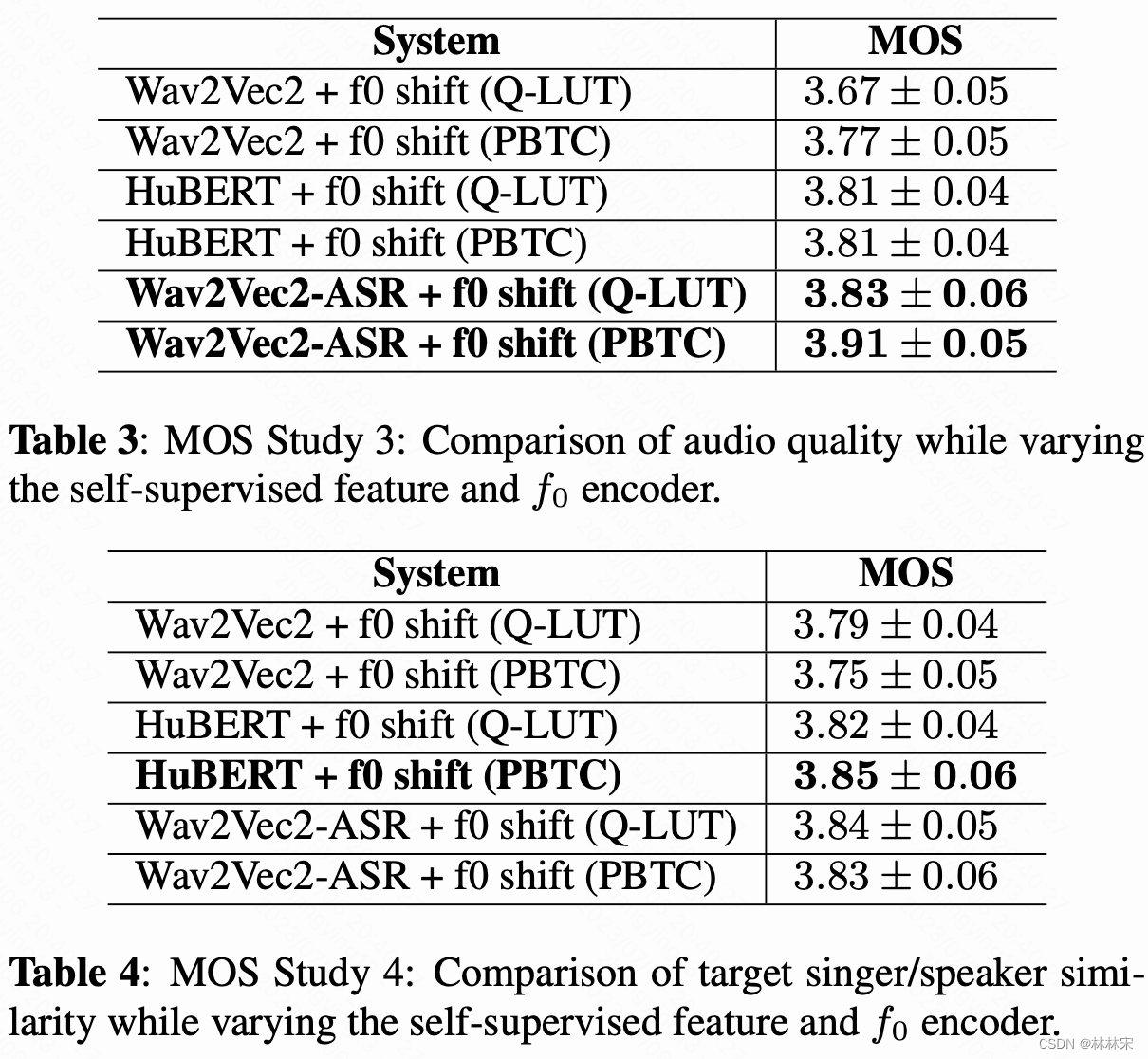
实验结果
- speech+sing的数据比sing-single的数据合成质量更好;本文用24k数据200h 高保真说话,10+h歌唱数据(NUS48E+CSD+AmericanSong)
- 自监督的模型,基于asr数据finetune之后,会过滤掉一些说话人的特征,合成的语音质量&目标人相似度都有提升;相比于wav2vec+finetune,hubert不做finetune可以达到相似的性能,说明hubert中的说话人特征比wav2vec少。
- PBTC的基频编码方式更好一些
- inference阶段,source speech中提取f0,shift到目标说话人的范围;















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









