






 本文介绍了一种课程设计目标,即创建一个易于使用的数据库系统,用于存储和管理蛋白质序列,支持文件上传、解析、批量处理、按需浏览和检索,提供图形界面或命令行接口,便于研究人员高效地获取和分析数据。
本文介绍了一种课程设计目标,即创建一个易于使用的数据库系统,用于存储和管理蛋白质序列,支持文件上传、解析、批量处理、按需浏览和检索,提供图形界面或命令行接口,便于研究人员高效地获取和分析数据。
如何收集,构建一个存储蛋白质序列的数据库,方便研究人员上传,更新,下载以及浏览相关数据,是更进一步研究深度学习的关键
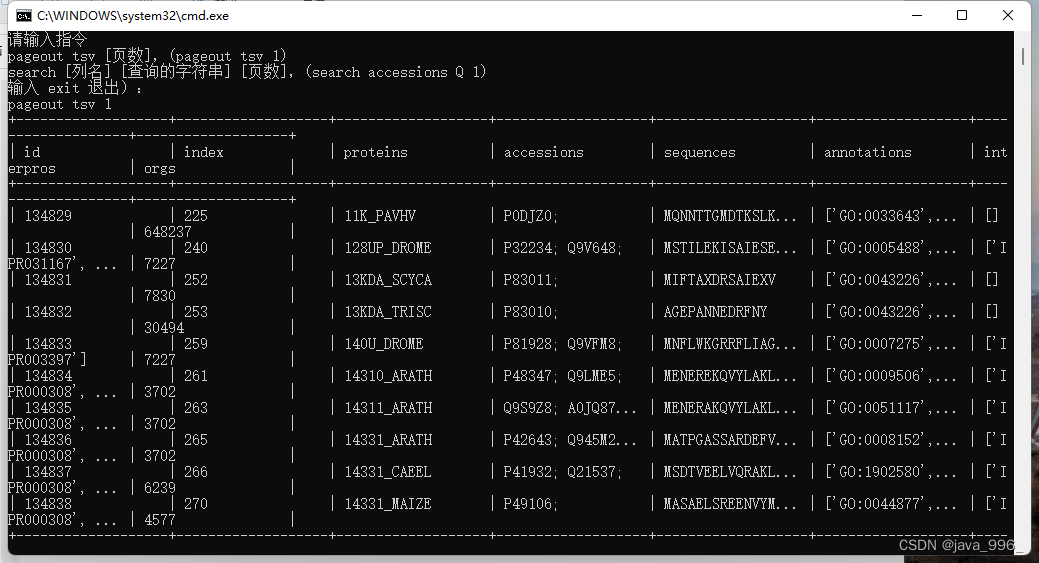
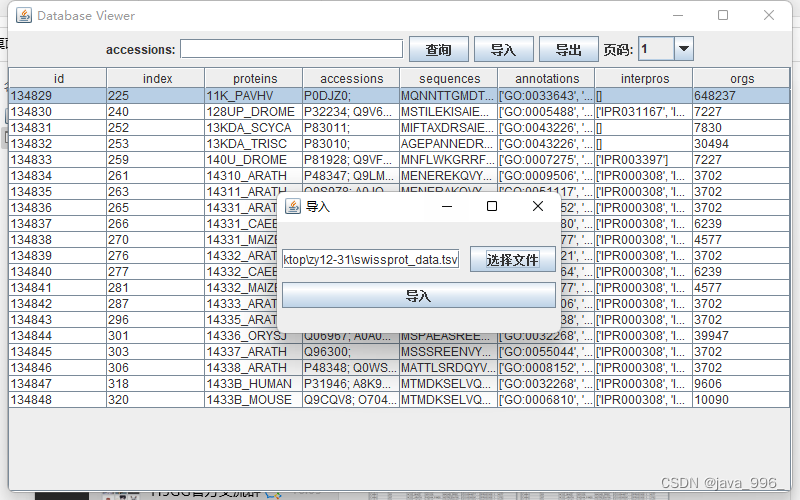
课程设计目标 将用户提供的文件或输入解析后存进数据库 将用户提供的信息(如:文件,用户输入)解析后存进数据库 批量处理数个包含复数以上文件解析后存进数据库 按页浏览数据库收录的序列信息 每一页以表格的形式输出 以文件的形式保存多页数据(文件格式可自定义) 按关键字检索数据库收录的序列 检索结果可以按页进行浏览 检索结果可以保存为文件(文件格式可自定义) 注:检索结果在特定情况下可以是非精准匹配 建立一个便于操作的用户界面(图形界面或命令行终端界面,甚至通过浏览器构建用户操作界面都行)
淘宝:宝贝的工作室
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









