









论文简述:
第一作者:Wenxuan Wu
发表年份:2020
发表期刊:ECCV
探索动机:
1、对于2D图像,由粗到精的方式直接处理数据可以使得算法能够适应大的运动而没有大的搜索空间,但是扩展到3D的点云数据时,计算开销会增大。 |
2、同时以往的代价聚合是以点对点的方式进行聚合,这种方式使得算法对异常点的值敏感,鲁棒性不够 |
3、获取密集标注的3D场景流数据集非常困难 |
工作目标:1、我们引入了新颖的代价体、上采样和变形层来高效地处理三维点云数据。2、探索新的自监督损失来训练我们的模型
核心思想:1、提出了一种新的可学习的基于点的代价体,其中我们将代价体离散化到输入点对,避免了如果我们幼稚地从图像扩展到点云时创建稠密的4D张量。2、提出了新的自监督损失项
实现方法:
提出了一种新的可学习的基于点的代价体,其中我们将代价体离散化到输入点对,避免了如果我们幼稚地从图像扩展到点云时创建稠密的4D张量。 | 1、提出以基于patch-to-patch的方式聚合代价,可以得到更加鲁棒且稳定的代价体 |
2、引入了一个可学习的函数cost ( · ),它可以动态地学习点云结构中的代价或相关性。 | |
3、在两个输入点云上不规则地离散这个代价体,并用基于点的卷积聚合它们的代价。避免了高昂的计算开销 | |
提出了新的自监督损失项:Chamfer距离、平滑约束和Laplacian正则化。这些损失项使网络能够在没有任何监督的情况下达到SOTA | |
实验结论:为了更好地从三维点云直接估计场景流,我们提出了一个新的可学习的代价体层和一些辅助层来构建一个由粗到精的深度网络PointPWC - Net。由于真实世界的地面真实场景流难以获取,我们引入损失函数,在无监督的情况下训练Point PWC - Net。在FlyingThings3D和KITTI数据集上的实验证明了我们的PointPWCNet和自监督损失函数的有效性,获得了优于先前工作的最新结果。
论文翻译:
PointPWC-Net: Cost Volume on Point Clouds for (Self-)Supervised Scene Flow Estimation
摘要:
我们提出了一种新的端到端的深度场景流模型PointPWC - Net,该模型以由粗到精的方式直接处理具有大运动的三维点云场景。在粗层计算的流被上采样和扭曲到一个更细的层,这可以使算法能够适应大的运动而没有令人望而却步的搜索空间。我们引入了新颖的代价体、上采样和变形层来高效地处理三维点云数据。不同于传统的代价体需要在高维网格上穷举计算所有的代价值,我们的基于点的公式将代价体离散到输入的3D点上,并且PointConv操作高效地计算代价体上的卷积。在FlyingThings3D和KITTI上的实验结果大大优于当前的先进水平。我们进一步探索新的自监督损失来训练我们的模型,并取得了与监督损失训练的最先进的结果相当的结果。在没有任何微调的情况下,我们的方法在KITTI Scene Flow 2015数据集上也表现出了很好的泛化能力,优于之前的所有方法。
关键词:代价体、自监督、由粗到细、场景流
1、引言
场景流是连续两帧图像中每个表面点之间的三维位移向量。作为底层理解世界的基本工具,场景流可以用于包括自动驾驶在内的许多3D应用。传统上,场景流直接从RGB数据[ 44、45、72、74]估计。但最近,由于3D传感器(如LiDAR )的应用越来越多,人们有兴趣从3D点云直接估计场景流量。
近年来,随着直接从点云数据中学习有效特征表示的3D深度网络的发展。目前的工作采用2D光流网络的方法用到3D来估计点云的场景流。FlowNet3D [ 36 ]使用PointNet + + [ 54 ]直接对点云进行操作,并提出了一个流嵌入,在一个层中计算以捕获两个点云之间的相关性,然后通过更细的层传播来估计场景流。HPLFlowNet [ 20 ]利用双边卷积层的上采样操作,从多个尺度联合计算相关性。
深度光流估计网络中的一个重要部分是代价体[ 31、65、81],它是一个三维张量,包含连续帧相邻像素对之间的匹配信息。在本文中,我们提出了一种新的可学习的基于点的代价体,其中我们将代价体离散化到输入点对,避免了如果我们幼稚地从图像扩展到点云时创建稠密的4D张量。然后在这个不规则离散的代价体上应用高效的Point Conv层[ 80 ]。我们实验表明,它优于先前的关联点云对应的方法,以及在二维光流中使用的代价体。我们还提出了高效的上采样和翘曲层来实现由粗到精的流量估计框架。
与光流一样,获取精确的点云场景流标签是困难且昂贵的。因此,除了有监督的场景流估计,我们还探索了不需要人工标注的自监督场景流。我们提出了新的自监督损失项:Chamfer距离[ 14 ]、平滑约束和Laplacian正则化。这些损失项使我们能够在没有任何监督的情况下实现最先进的性能。
我们在FlyingThings3D [ 44 ]和KITTI Scene Flow 2015 [ 46、47]数据集上进行了大量的实验,其中包括有监督损失和本文提出的自监督损失。实验表明,本文提出的PointPWC - Net比之前的所有方法都有很大的提升。自监督版本在FlyingThings3D上与之前的一些监督方法具有可比性,如SPLATFlowNet [ 63 ]。在没有监督的KITTI上,我们的自监督版本取得了比在FlyingThings3D上训练的监督版本更好的性能,远远超过了最先进的版本。我们还对Point PWC - Net的每个关键成分进行了消融,以了解它们的贡献。
我们工作的主要贡献是:
1、我们提出了一种新的可学习的代价体层,它在不创建稠密的4D张量的情况下对代价体进行卷积。
2、通过新的可学习的代价体层,我们提出了一个新的模型,称为PointPWC - Net,它以粗到精的方式从两个连续的点云估计场景流。
3、我们引入了自监督损失,可以在没有任何真值标签的情况下训练PointPWC - Net。据我们所知,我们是最早在三维点云深度场景流估计中提出这样一个想法的人之一。
4、我们在FlyingThing3D和KITTI Scene Flow 2015上取得了最先进的性能,远远超过了之前的最先进水平。
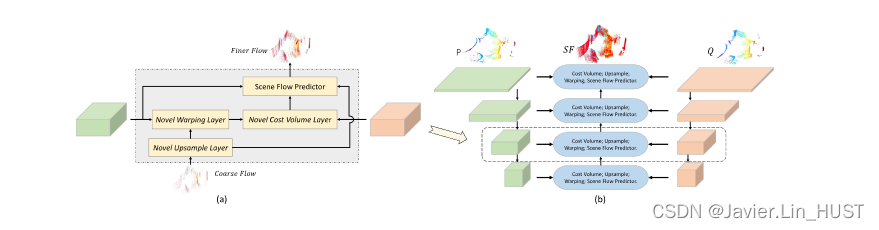
图1 . ( a )说明了金字塔特征如何被新的代价体、扭曲和上采样层在一个层次上使用。( b )为Point PWCNet的总体结构。在每个层次上,PointPWC - Net首先使用上采样的场景流从第一个点云中扭曲特征。然后,利用扭曲后的第1个点云和第2个点云的特征计算代价体。最后,场景流预测器使用来自第一点云、成本卷和上采样流的特征在当前级别预测更精细的流。(最好在色彩上观看)(彩色图形在线)
2、相关工作
点云上的深度学习。在过去几年中,三维点云的深度学习方法得到了更多的关注。一些最新的工作[ 19、25、34、53、54、57、63、68、73]直接将原始点云作为输入。[ 53、54、57]使用共享的多层感知器( MLP )和最大池化层来获取点云的特征。其他工作[ 22、30、61、78 ~ 80]提出从3D点坐标学习连续卷积滤波器权重作为非线性函数,用MLP近似。[ 22、80 ]使用密度估计来补偿非均匀采样,并且[ 80 ]通过改变求和技巧显著提高了内存效率,使这些网络能够扩展并实现与2D卷积相当的能力。
光流估计。光流估计是计算机视觉的一个核心问题,有着广泛的应用。传统的顶端执行方法通常采用能量最小化方法[ 24 ]和一种由粗到精、基于翘曲的方法[ 4、7、8]。自FlowNet [ 13 ]以来,最近有许多工作使用深度网络来学习光流。文献[ 28 ]将多个FlowNet堆叠成一个更大的FlowNet。[ 56 ]提出了一种紧凑的空间金字塔网络。[ 65 ]将广泛使用的传统金字塔、翘曲和成本卷技术集成到CNNs中用于光流,并以较高的效率超过了以前的所有方法。我们使用了与他们相似的基本结构,但提出了适合点云的新的成本卷、翘曲和上采样层。
场景流估计。三维场景流最早由文献[ 72 ]提出。许多工作[ 26、45、75]使用RGB数据估计场景流。文献[ 26 ]介绍了一种从立体序列估计场景流的变分方法。文献[ 45 ]提出了一种对象级场景流估计方法,并引入了一个3D场景流数据集。文献[ 75 ]提出了一种用于三维场景流估计的分段刚性场景模型。
最近,有一些工作[ 12、70、71]使用经典技术直接从点云中估计场景流。文献[ 12 ]介绍了一种方法,将场景流估计问题建模为能量最小化问题,并假设局部几何恒常性和正则化,用于运动平滑。文献[ 71 ]提出了构建占用网格、过滤背景、求解能量最小化问题和使用过滤框架进行细化的实时四步法。[ 70 ]进一步改进了[ 71 ]中的方法,使用编码网络从占用网格中学习特征。
在最近的一些工作[ 20、36、78]中,研究人员尝试使用深度学习以端到端的方式从点云中估计场景流。文献[ 78 ]使用PCNN对LiDAR数据进行操作来估计LiDAR运动。文献[ 36 ]介绍了基于Point Net + +的Flow Net3D [ 54 ]。FlowNet3D使用流嵌入层来编码点云的运动。然而,为了捕获大的运动,它需要编码一个大的邻域。文献[ 20 ]提出使用双边卷积层( BCL )的HPLFlowNet来估计场景流,该方法将点云投影到一个多面体网格上。文献[ 3 ]通过一个联合预测3D边界框和场景中物体或背景的刚性运动的网络来估计场景流。与文献[ 3 ]不同的是,我们不需要刚性运动假设和分割水平监督来估计场景流。
自监督场景流。最近的一些工作[ 27、32、35、82、87]在没有监督的情况下联合估计多个任务,即深度、光流、自运动和相机位姿。它们以二维图像作为输入,在用于场景流估计时具有模糊性。在本文中,我们研究了基于PointPWCNet的三维点云场景流自监督学习。同时,Mittal等人[ 49 ]将最近邻( Nearest Neighbor,NN )损失和循环一致性损失引入到自监督点云场景流估计中。但是,它们没有考虑三维点云的局部结构特性。在我们的工作中,我们提出使用平滑度和Laplacian坐标来保持场景流的局部结构
传统的点云配准。在深度学习[ 21,66]之前,点云配准已经得到了广泛的研究。大部分工作[ 10、18、23、43、48、60、69、85]只在场景中大部分运动为全局刚体时工作。许多方法基于迭代最近点( ICP ) [ 5 ]及其变体[ 52 ]。一些工作[ 1、6、29、50]处理非刚性点云配准。相干点漂移( Coherent Point Drift,CPD ) [ 50 ]为刚性和非刚性点集的配准引入了一种概率方法。然而,计算开销使得其难以在真实世界数据上实时应用。许多算法被提出来扩展CPD方法[ 2,11,15-17,33,37-42,51,55,59,67,76,83,84,86]。有些算法需要额外的信息进行点集配准。工作[ 11 , 59]考虑了颜色信息和空间位置信息。文献[ 1 ]要求网格进行非刚性配准。在[ 55 ]中,给出了贝叶斯框架下点集配准的回归和聚类。上述所有工作都需要在推理时刻进行优化,这比我们的方法在推理过程中几分之一秒的时间运行要高得多。
3、方法
要实现高精度的光流计算,代价体是最重要的组成部分之一。在二维图像中,代价体可以通过在网格上的正方形邻域内聚合成本来计算。然而,由于三维点云是无序的,且采样密度不均匀,跨两个点云的计算成本体积是困难的。在本节中,我们引入一个新颖的可学习的代价体层,利用它和其他辅助层一起构建深度网络并用来得到高质量的场景流。

图2 . ( a )分组。对于一个点pc,我们将其在每个点云中的K - NN邻域组成NP ( pc )和NQ ( pc )来进行代价体聚合。我们首先聚合来自点云Q中面片NQ ( pc )的代价,然后聚合来自点云P中面片NP ( pc )的代价。( b )成本体量层。将NQ ( pc )中邻近点的特征与方向向量( qi-pc)串联,利用Point Conv学习pc与Q之间的点到块代价。然后将NP ( pc )中的点到补丁成本用Point Conv进一步聚合,构建基于图像块分割成本体
3.1 代价体层
作为光流估计的关键组成部分之一,无论是传统的[ 58,64]算法,还是基于现代深度学习的[ 9、65、81]算法,大多数先进的算法都是使用代价体积来估计光流。然而,在点云上计算开销仍然是一个开放的问题。有几项工作[ 20、36]计算了点云之间的某种流嵌入或相关性。文献[ 36 ]提出了一个流嵌入层来聚合特征相似性和空间关系来编码点运动。然而,由于流嵌入层中的最大池化操作,会丢失点与点之间的运动信息。文献[ 20 ]引入了Corr BCL层来计算两片点云之间的相关性,该层要求将两片点云转换到同一个多边体点阵上。
了解决这些问题,我们直接在两个点云的特征上提出了一个新的可学习的代价体层。设fi∈Rc是点pi∈P的特征,gj∈Rc是点qj∈Q的特征,则pi和qj之间的匹配代价可以定义为:

其中,concat表示串联。在我们的网络中,特征fi和gj要么是点云的原始坐标,要么是前几层的卷积输出。直觉是,作为一个通用的逼近器,MLP应该能够学习到两点之间潜在的非线性关系。由于点云的灵活性,除了点特征fi和gj外,我们还在计算中加入了方向向量( qj-pi)。
一旦我们有了匹配代价,它们就可以聚合为一个代价体,用于预测两个点云之间的移动。在2D图像中,聚合代价只需应用一些卷积层,如PWC - Net [ 65 ]。然而,由于点云的无序性,所以传统的卷积不能直接作用于点云上。[ 36 ]使用max-pooing聚合第二个点云中的特征。Zhang等[ 20 ]使用Corr BCL在正方形格子上聚合特征。然而,他们的方法仅以点对点的方式聚合代价,对异常值敏感。为了得到更加鲁棒且稳定的代价体,在这个工作中,我们提出以基于图像块分割的方式聚合代价,类似于二维图像[ 31,65]上的代价体。对于P中的一个点pc,我们首先在pc周围找到一个邻域NP ( pc ) .对于每个点pi∈NP ( pc ),我们在Q中找到一个关于pi的邻域NQ ( pi ) . pc的代价体积定义为:

其中WP ( pi , pc)和WQ( qj , pi)是卷积权重,对于方向向量则是用来聚合P、Q块中的代价。它分别被MLP用学习的方式得到的方向向量( qi-pc)∈R3和( qj-pi)∈R3的连续函数,如[ 80 ]和PCNN [ 78 ]。代价体层的输出是一个形状为( n1 , D)的张量,其中n1为P中的点数,D为代价体的维度,编码了每个点的所有运动信息。代价体中使用的基于图像块分割思想如图2所示。
这种用于三维点云场景流的代价体与用于立体和光流的传统二维代价体有两个主要区别。第一种是我们引入了一个可学习的函数cost ( · ),它可以动态地学习点云结构中的代价或相关性。5.3节中的消融研究表明,在场景流估计中,这种新颖的可学习设计比传统的代价体积[ 65 ]取得了更好的效果。第二种是在两个输入点云上不规则地离散这个代价体,并用基于点的卷积聚合它们的代价。以前,为了计算W × H 的2D图像上d × d区域的光流代价体,需要填充d2 × W × H张量中的所有值,这在2D计算中已经很慢,但在3D空间计算代价巨大。对于(体素) 3D卷积,需要在3D空间中搜索一个d3区域来获得代价体。我们的代价体在输入点上离散化,避免这种代价高昂的操作,同时本质上创造了相同的能力来对代价体进行卷积。在提出的代价体层中,我们只需要找到大小为K的两个邻域NP ( pc )和NQ ( pi ),这个代价体层不依赖于点云的点数,而且代价体层的开销更低。在我们的实验中,我们固定| NP ( pc ) | = | NQ ( pi ) | = 16。如果需要更大的邻域,我们可以对邻域进行采样,使其恢复到相同的速度。这种下采样操作只适用于稀疏点云卷积,不可能用于常规的体素卷积。我们预期这个新的代价体层在场景流估计之外具有广泛的用途。表2显示它优于[ 36 ]的MLP + Maxpool策略。
3.2 PointPWC-Net
给定提出的可学习代价卷层,我们构建了一个用于场景流估计的深度网络。在二维光流估计中,由粗到精的结构是实现稠密估计最有效的方法之一。在本节中,我们介绍了一些新颖的点云辅助层,这些辅助层构建了一个由粗到精的场景流估计网络,并提出了可学习的代价体层。该网络被称为" Point PWC-Net " [ 65 ]。
如图1所示,Point PWC - Net以由粗到精的方式预测密集场景流。PointPWC - Net的输入为连续的两片点云,P = { pi∈R3 } n1i = 1,有n1个点,Q = { qj∈R3 } n2j = 1,有n2个点。我们首先为每个点云构建一个特征金字塔。之后,我们在每一层都使用来自两个点云的特征来构建代价体。然后,我们使用来自P的特征,代价体和上采样流来估计更精细的场景流。我们将预测的场景流作为粗流,将其上采样到更细的流,并将点从P映射到Q。注意,上采样和翘曲层都是有效的,没有可学习的参数。
点云特征金字塔。为了高精度地估计场景流,需要从输入点云中提取强特征。我们生成一个L级的特征表示金字塔,顶层为输入点云,即l0 = P / Q。对于每一个层级l,我们使用最远点采样[ 54 ]将上一个层级l - 1的点降采样4倍,并使用PointConv [ 80 ]对层级l - 1的特征进行卷积。因此,我们可以为每个输入点云生成一个L级的特征金字塔。之后,我们通过对l + 1层的特征进行上采样来扩大金字塔l层的感受野,并将其与l层的特征进行级联。
上采样层。上采样层可以将估计的场景流从较粗的层传播到较细的层。我们使用基于距离的插值对粗流进行上采样。令Pl为第l层的点云,SFl为第l层的估计场景流,pl - 1为第l - 1层的点云。对于较细层次点云P l - 1中的每个点pl - 1i,可以在其较粗层次点云P l中找到其K个最近邻点N ( pl-1i )。使用反距离加权插值计算了精细SFl - 1层的插值场景流:

其中w( pl-1i , plj) = 1 / d( pl-1i , plj),pl-1i∈Pl-1,plj∈N ( pl-1i ) . d( pl-1i , plj)是距离度量.我们在这项工作中使用欧氏距离。
Warping层。Warping会"套用"计算出的流量,使得之后只需要估计剩余流量,因此在构建成本体时搜索半径可以更小。在我们的网络中,我们首先从先前的较粗级别上采样场景流,然后在计算代价体之前对其进行变形。将上采样后的场景流表示为SF = { sfi∈R3 } n1i = 1,扭曲点云表示为Pw = { pw,i∈R3 } n1i = 1。翘曲层只是上采样和计算场景流Pw = { pw,i = pi + sfi | pi∈P,sfi∈SF } n1i = 1之间的元素相加。在[ 20、36]中使用类似的扭曲操作进行可视化,将估计的流量与真实值进行比较,但不用于由粗到精的估计。文献[ 20 ]使用了一种偏移策略来减小搜索半径,该策略是针对遍布面晶格的。
场景流估计器。为了获得每个层的流估计,用多层的PointConv和MLP构建了一个卷积场景流预测器。流预测器的输入是代价体、第一个点云的特征、来自上一层的上采样流和来自上一层场景流预测器的第二个最后一层的上采样特征,我们称之为预测器特征。输出为第i个点云P的场景流SF = { sfi∈R3 } n1i = 1。前几个Point Conv层用于局部合并特征,后面的MLP用于估计每个点上的场景流。我们在不同级别上保持流预测器结构相同,但不共享参数。
4、训练的损失函数
在本节中,我们引入两个损失函数来训练PointPWC - Net进行场景流估计。一种是标准的多尺度监督训练损失,已经在二维图像的深度光流估计[ 65 ]中进行了探索。我们使用这种有监督的损失来训练模型,以便与之前FlowNet3D [ 36 ]和HPLFlowNet [ 20 ]的场景流估计工作进行公平的比较。由于获取密集标注的3D场景流数据集非常困难,我们还提出了一种新颖的自监督损失来训练我们的PointPWC - Net。
4.1 监督损失
我们采用Flow Net [ 13 ]和PWC - Net [ 65 ]中的多尺度损失函数作为监督学习损失,以证明网络结构的有效性和设计选择。设SFl GT为第l层的真值流。使用多尺度训练损失( Θ ) =∑L l = l0αl∑p∈P∥∥SF lΘ ( p ) -SFl GT ( p )∥∥2,其中‖·‖2计算L2范数,α l为每个金字塔层级l的权重,Θ为PointPWC - Net中所有可学习参数的集合,包括不同金字塔层级的特征提取器、代价体层和场景流预测器。注意,流的损失并不像文献[ 65 ]那样平方以保证稳健性。
4.2 自监督损失
获取三维点云的真实场景流是困难的,从点云中进行场景流学习的公开可用数据集并不多。在本节中,我们提出了一种无监督的自监督学习目标函数来学习三维点云中的场景流。我们的损失函数包含三个部分:Chamfer距离、Smoothness约束和Laplacian正则化[ 62、77]。据我们所知,我们是第一个研究从三维点云进行场景流估计的自监督深度学习的人,目前的研究现状[ 49 ]。
Chamfer损失。Chamfer损失的目标是通过估计场景流,将第一帧的点云尽可能的与第二帧接近。令SFl Θ为第l层预测的场景流。令Plw为第l层第l个点云Pl按SFl Θ变形后的点云,Ql为第l层第2个点云。设plw和ql是Plw和Ql中的点. Chamfer损失lC可以写为:

平滑性约束。为了加强局部空间平滑性,我们增加了一个平滑约束lS,它假设在pli的一个局部区域N ( pli )中预测的场景流SFl Θ ( plj )应该与pli处的场景流相似:

其中| N ( pli ) |是局部区域N ( pli )中点的个数.
Laplacian正则化。拉普拉斯坐标向量近似曲面的局部形状特征[ 62 ]。计算拉普拉斯坐标向量δ l ( pli )为:

对于场景流,变形后的点云Plw在相同位置处应与第二个点云Ql具有相同的拉普拉斯坐标向量。因此,我们首先计算第二个点云Ql中的每个点的拉普拉斯坐标δ l ( pli )。然后,对Ql的Laplacian坐标进行插值,得到每个点plw上的Laplacian坐标。采用类似于式( 6 )的反距离插值方法。对Laplacian坐标δ l进行插值.设δ l ( plw )为点plw在水平l处的拉普拉斯坐标,δl ( ql inter )为Ql在与plw相同位置的Laplacian坐标。
Laplacian正则化lL定义为:

总体损失是所有金字塔层级的所有损失的加权和:

其中,α l为金字塔层级l的因子,β1,β2,β 3分别为每个损失的尺度因子。在自监督损失的情况下,我们的模型能够从三维点云对中学习场景流,而不需要任何地面真值监督。
5、实验
在本节中,我们分别在有监督损失和自监督损失的FlyingThings3D数据集上训练和评估PointPWC - Net [ 44 ]。然后,我们通过在真实的KITTI场景流数据集[ 46、47]上应用该模型来评估我们模型的泛化能力。然后,利用提出的自监督损失,我们在KITTI数据集上进一步微调我们的预训练模型,以研究我们在没有监督的情况下可以获得的最佳性能。此外,我们还将模型的运行时间与之前的工作进行了比较。最后,我们进行消融研究,分析模型各部分和损失函数的贡献。
实施细节。我们从输入点云构建了一个4级特征金字塔。权重α设置为α 0 = 0.02,α1 = 0.04,α2 = 0.08,α3 = 0.16,权重衰减0.0001。设定自监督学习中的尺度因子β分别为β 1 = 1.0,β2 = 1.0,β3 = 0.3。我们从学习率为0.001开始训练我们的模型,每80个历元减少一半。所有的超参数使用FlyingThings3D的验证集进行设置,每个输入点云有8192个点。
评价指标。为了公平比较,我们采用了文献[ 20 ]中使用的评价指标。令SF Θ表示预测场景流,SFGT表示真实场景流。评价指标的计算方法如下:

5.1 监督学习
首先我们进行有监督损失的实验。据我们所知,目前还没有公开的大规模真实世界数据集,这些数据集具有来自点云( KITTI场景流基准的输入为2D)的场景流地面真实度,因此我们在合成的Flyingthings3D数据集上训练了Point PWC-Net [ 20 ]。然后,在KITTI Scene Flow 2015数据集上直接对预训练好的模型进行评估,无需任何微调。
在Flyingthings3D上进行训练和评估。FlyingThings3D训练数据集包含19640对点云,评估数据集包含3824对点云。我们的模型在每个点云中取n = 8192个点。我们首先用训练集( 4 , 910对)的1 / 4对模型进行训练,然后在整个训练集上进行微调,加快训练速度。
表1。评价在Flyingthings3D和Kitti数据集上的实验结果。Self表示自监督,Ful l表示强监督。所有方法都(至少)在FlyingThings3D上进行训练。在KITTI上,Self和Full分别指的是在FlyingThings3D上训练的、在KITTI上直接评估的模型,而Self + Self指的是先在FlyingThings3D上进行自我监督训练,再在KITTI上进行自我监督微调。Full + Self表示模型在FlyingThings3D上进行全监督训练,然后在KITTI上进行自监督微调。ICP [ 5 ]、FGR [ 85 ]、CPD [ 50 ]是不需要训练的传统方法。我们的模型在所有指标上都大大优于所有基线

表1展示了在Flyingthings3D数据集上的定量评估结果。我们的方法在所有指标上都比所有方法有很大的优势。与SPLATFlow Net、原始BCL和HPLFlow Net相比,本文方法避免了从输入中构建百面体格的预处理步骤。此外,我们的方法在EPE3D上比HPLFlowNet提高了26.9 %。并且,我们是唯一一个EPE2D低于4px的方法,比HPLFlowNet提高了30.7 %。示例结果见图3 ( e )。

图3 . Flyingthings3D数据集上的结果。在( a )中,在马真塔和Green中分别呈现了两个点云PC1和PC2。在( b-f )中,PC1根据(计算的)场景流被扭曲为PC2。( b )表示基本事实;( c ) Fgr (刚性) [ 85 ]的结果;( D )是Cpd ( Non-Rigid ) [ 50 ]的结果;( e ) PointPWC-Net ( Ful l )结果;( f )由Pointpwc - net ( self )得到的结果.红色椭圆表示具有显著非刚性运动的位置。放大图像以获得更好的视野。(最好在色彩上观看)(彩色图形在线)
对KITTI w/o Fine-Tune进行评价。为了研究Point PWC - Net的泛化能力,我们直接使用FlyingThings3D训练的模型,并在KITTI Scene Flow 2015 [ 46、47]上进行评估,没有进行任何微调。KITTI Scene Flow 2015由200个训练场景和200个测试场景组成。为了评估我们的PointPWC - Net,我们使用地面真值标签和跟踪与帧相关的原始点云,遵循[ 20、36]。由于在测试集上没有提供点云和地面真值,因此我们使用可用的点云对训练集中的所有142个场景进行评估。为了与之前的方法进行公平的比较,我们在[ 20 ]中删除了高度小于0.3 m的地面点。
从表1中可以看出,我们的PointPWC - Net优于所有最先进的方法,这证明了我们模型的泛化能力。对于EPE3D,我们的模型是唯一一个低于10cm的模型,比HPLFlowNet提高了40.6 %。对于Acc3DS,我们的方法比FlowNet3D和HPLFlowNet分别高出35.4 %和25.0 %。示例结果见图4 ( e )。
5.2 自监督学习
从真实世界的三维点云中获取或标注稠密的场景流是非常昂贵的,因此评估我们的自监督方法的性能很有意思。我们使用与监督学习相同的步骤训练我们的模型,即先用四分之一的训练数据集训练模型,然后用整个训练集微调。表1给出了PointPWC - Net自监督学习的定量结果。我们将我们的方法与ICP (刚性) [ 5 ],FGR (刚性) [ 85 ]和CPD (非刚性) [ 50 ]进行了比较。由于传统的点配准方法没有经过地面真值训练,我们可以将其视为自/无监督方法。
在FlyingThings3D上进行训练和测试。可以看出,本文的Point PWC-Net在所有的指标上都优于传统方法。示例结果见图3 ( f )。
在KITTI w/o Fine-Tuning上进行评估。即使只在没有真值标签的FlyingThings3D上训练,我们的方法在KITTI上也能获得0.2549 monEPE3D,比CPD (非刚性)提高了38.5 %,比FGR (刚性)提高了47.3 %,比ICP (刚性)提高了50.8 %。
在KITTI上进行微调。通过提出的自监督损失,我们可以在KITTI上对FlyingThings3D训练好的模型进行微调,而不需要使用任何真实数据。在表1中,行PointPWC - Net ( w / ft ) Full + Self和PointPWCNet ( w / ft ) Self + Self显示结果。Ful l + Self表示模型在FlyingThings3D上有监督训练,然后在KITTI上无监督微调。Self + Self表示模型首先在FlyingThings3D上训练,然后在KITTI上使用自监督损失进行微调。通过KITTI微调,我们的Point PWC - Net可以实现EPE3D < 5 cm。特别地,我们的PointPWC - Net ( w / ft ) Self + Self在没有任何真值信息的情况下进行了充分的训练,在KITTI上取得了与利用FlyingThings3D真值相似的性能。算例结果见图4 ( f )。

图4 . Kitti场景流2015数据集上的结果。在( a )中,在马真塔和Green中分别呈现了两个点云PC1和PC2。在( b-f )中,基于(计算)场景流,PC1被扭曲为PC2。( b )表示基本事实;( c ) Fgr (刚性) [ 85 ]的结果;( D )是Cpd ( Non-Rigid ) [ 50 ]的结果;( e )在FlyingThings3D上监督训练的Point PW C-Net ( w / o ft + Full )结果,直接在KITTI上评估,不做任何微调;( f )使用提出的自监督损失在FlyingThings3D上训练并在KITTI上微调的Point PWCNet ( w / ft + Self + Self)的结果。红色椭圆表示具有显著非刚性运动的位置。放大图像以获得更好的视野。(最好在色彩上观看) (彩色图形在线)
5.3 消融实验
我们进一步对模型设计选择和自监督损失函数进行消融研究。在模型设计上,我们评估了成本卷层和去除翘曲层的不同选择。在损失函数上,我们研究了去除自监督学习损失中的平滑约束和Laplacian正则化。消融研究中的所有模型均使用FlyingThings3D进行训练,并在FlyingThings3D评估数据集上进行测试。

表2 .模型设计。一个可学习的成本体积比PWC - Net中使用的内部产品成本体积要好得多[ 65 ]。使用我们的代价体代替FlowNet3D的流嵌入层使用的MLP + Maxpool,性能提升了20.6 %。与无翘曲相比,翘曲层使性能提高了40.2 %。

表3 .损失函数。Chamfer损失不足以估计好的场景流。在平滑度约束下,场景流结果提升了38.2 %。拉普拉斯正则化也略有改善

表4 .运行时间。Flyingthings3D上的平均运行时间( ms )。FlowNet3D和HPLFlowNet的运行时报告在单个Titan V上[ 20 ]。PointPWC - Net的运行时报告在单个1080Ti上
表2和表3为消融研究结果。在表2中我们可以看到我们的代价卷的设计在PWC - Net [ 65 ]和FlowNet3D [ 36 ]中获得了明显优于基于内积的代价卷的结果,并且翘曲层对性能至关重要。在表3中,我们看到平滑约束和Laplacian正则化都提高了自监督学习的性能。在表4中,我们报告了我们的Point PWC - Net的运行时间,它与其他基于深度学习的方法相当,并且比传统方法快得多。
6、结论
为了更好地从三维点云直接估计场景流,我们提出了一个新的可学习的代价体层和一些辅助层来构建一个由粗到精的深度网络PointPWC - Net。由于真实世界的地面真实场景流难以获取,我们引入损失函数,在无监督的情况下训练Point PWC - Net。在FlyingThings3D和KITTI数据集上的实验证明了我们的PointPWCNet和自监督损失函数的有效性,获得了优于先前工作的最新结果。















 1025
1025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









