









论文简述:
第一作者:Guangming Wang
发表年份:2021
发表期刊:IEEE Transactions on Image Processing(TIP)
探索动机:1、如何使两帧点云进行更加有效的对应。2、如何减少场景流精细化过程中的GPU内存消耗,实现精度和资源消耗的平衡。
工作目标:1、实现两帧点云更有效的对应。2、减小GPU内存消耗的同时达到精度的要求
核心思想:
1、提出一种新的分层注意力网络用于从两个连续的三维点云进行场景流估计。在该网络中,提出了一种新颖的连续两个点云的双注意力流嵌入方法,并将其应用于场景流的分层注意力学习。 |
2、提出具有新颖的more-for-less架构的分层注意力网络,以平衡精度和资源消耗。并且使用更多的3D欧氏信息进行流嵌入,提升网络的性能。 |
实现方法:1、通过使用三维欧氏信息给流嵌入进行加权,使得点更多地关注所匹配的区域和特征。双重注意力流嵌入过程之后使用set conv层进行流编码,使得场景流更加的平滑。2、通过在第一层进行随机采样,实现more-for-less。剩余的点的场景流可以由随机采样点的场景流多次测试估计得到
实验结论:本文提出了一种新颖的场景流分层注意力学习方法。受人类直觉的启发,我们提出的双注意力流嵌入方法关注几个重要的点来软估计场景流。此外,为了平衡精度和资源消耗,提出了一种新型more-for-less网络架构。一系列消融研究证明了我们网络结构设置的有效性。在常见的FlyingThings3D数据集[ 10 ]和KITTI数据集[ 28 ]中的大量实验表明,我们的方法可以达到最先进的性能。所提出的网络也被应用于实际的LiDAR里程计任务。我们的方法不需要假设对应点或迭代,性能优于基于ICP的方法,具有很强的实际应用能力。
论文翻译:
Hierarchical Attention Learning of Scene Flow in 3D Point Clouds
摘要:
场景流表示动态环境中每一点的三维运动。与表示二维图像中像素运动的光流一样,场景流的三维运动表示有利于许多应用,如自动驾驶和服务机器人。本文研究了从两个连续的三维点云进行场景流估计的问题。本文提出了一种新颖的双注意力分层神经网络,用于学习相邻帧中点特征的相关性,逐层由粗到细地细化场景流。提出的网络具有新的more-for-less分层架构。more-for-less意味着场景流估计的输入点数大于输出点数,带来了更多的输入信息,平衡了精度和资源消耗。在这种分层架构中,不同层次的场景流分别被生成和监督。引入了一种新颖的注意力嵌入模块,以基于图像块分割的方式使用双重注意力方法聚合相邻点的特征。在我们的网络设计中仔细考虑了特定的流嵌入和流监督层。实验表明,在FlyingThings3D和KITTI Scene Flow 2015数据集上,本文提出的网络优于3D场景流估计的最新性能。我们还将所提出的网络应用于实际的激光雷达里程计任务,这是自动驾驶中的一个关键问题。实验结果表明,我们提出的网络性能优于基于ICP的方法,具有良好的实际应用能力。
关键词:深度学习、三维点云、场景流、LiDAR里程计。
1、引言:
场景流表示场景中两个连续的点云之间完全或部分移动的三维运动场[ 1 ]。它具体表征了每个3D点的运动距离和方向。对于二维图像来说,它是对光流这样的三维动态场景的一个基本的底层理解。场景流估计可广泛应用于自动驾驶[ 2 ]、[ 3 ]、运动分割、动作识别等多个领域。然而,以往的研究[ 4 ] - [ 11 ]大多侧重于从二维图像中获取视差和光流来表示场景流,并利用视差和光流的准确性来评估场景流估计的性能。但这并不适用于原始三维点输入,如自动驾驶中使用的LiDAR数据。
已有的一些研究[ 12 ]、[ 13 ]不是基于深度学习进行3D点输入而是对场景局部刚性假设的需求。随着深度学习在三维点云上的发展[ 14 ] - [ 16 ],最近的一些研究[ 17 ] - [ 19 ]可以在不知道场景结构或任何运动先验信息的情况下,从两个连续的点云生成三维场景流。这些方法直接将点云的坐标输入神经网络,以端到端的方式学习场景流。Flow Net3D [ 17 ]像Point Net + + [ 15 ]一样构建了多个下采样和上采样层,并使用新的流嵌入层来提取点云之间的相关性。然后通过set conv传播流嵌入特征并通过set upconv 层以获取场景流。然而,流嵌入层仅提取第1帧中某一特定点与第2帧中若干个查询点之间的相关性,本文称之为point-to-patch方式。点到块的方式在嵌入过程中不考虑第一帧中特定点附近的点。HPLFlowNet [ 18 ]提出了基于百面体格表示的块相关性,并使用提出的多层Corr BCL学习连续两帧的相关性。然而,在百面体晶格上插值的信息损失限制了性能。
文献[ 19 ]提出的patch-to-patch的方式在嵌入过程中也利用了更多的信息。patch-to-patch的方式使用第一帧中的一个patch来嵌入特征,而不是像point-to-patch的方式只使用一个点。而PWC - Net [ 20 ] [ 21 ]中由粗到精的分层光流学习思想也被应用于PointPWC - Net [ 19 ]中。然而,patch-to-patch的方式虽然扩大了接收区域,但一个点只有一个方向流向第二帧。这意味着并非所有的信息都具有相同的重要性。实际上,与最大池化操作相比,加权点特征可以使更多的注意力集中在与任务相关的区域,丢失更少的信息。而注意力机制的思想在其他视觉任务[ 22 ]、[ 23 ]和3D点云任务[ 24 ]、[ 25 ]中都表现出了重要的意义。
Point PWC-Net [ 19 ]使用多层感知器( MLP )从点的相对坐标中学习权重进行流嵌入。然而,相关权重并不是仅由欧氏空间决定的。例如,在流嵌入的过程中,树干上的一个点可能会搜索附近的车或墙上的点以及树顶上的点。然而,与树顶的点相比,附近车内的点虽然更靠近树干,但相关性较小。因此在场景流估计中考虑特征空间也是非常重要的。本文对此进行了重点研究,提出了一种分层注意力学习网络用于场景流估计,每个流嵌入具有两种不同的注意力。此外,以较多的点作为输入来估计较少点的场景流,相比于较少的输入点进行估计,会赋予场景更珍贵的结构信息。同时,较多的输入点进行较少的估计相比于较多的输入点进行较多的点估计,减少了流精化过程中GPU内存的消耗。此外,现有工作较少利用Flow Net3D [ 17 ]以外的场景流在三维点云中的实际应用,相比于迭代最近点( Iterative Closest Point,ICP ) [ 26 ]和运动分割任务,尝试将场景流应用于点云配准任务。本文开发了一个较为困难的任务,即LiDAR里程计任务。我们的主要贡献如下:
•提出了一种新的分层注意力网络用于从两个连续的三维点云进行场景流估计。在该网络中,提出了一种新颖的连续两个点云的双注意力流嵌入方法,并将其应用于场景流的分层注意力学习。
•提出了具有新颖的more-for-less架构的分层注意力网络,以平衡精度和资源消耗。并且使用更多的3D欧氏信息进行流嵌入,提升网络的性能。
•在我们的网络设计中,通过消融研究仔细考虑和论证了特定的流嵌入和流监督层。在FlyingThings3D [ 10 ]的合成数据和KITTI [ 27 ] [ 28 ]的真实LiDAR扫描数据上的实验表明,我们的方法在三维场景流估计方面比现有方法有很大的优势。
•最后,在LiDAR里程计任务上展示了我们的场景流网络的实际应用能力。我们的网络可以在不对网络结构进行任何调整的情况下优于基于ICP的方法。
本文的结构安排如下:第二部分是相关工作。第三节给出了三维点云场景流估计的问题定义。关于我们的分层注意力学习网络的细节在第四部分。第五节介绍了训练细节、评估指标、与现有技术的对比实验、消融研究以及在LiDAR里程计中的应用。
2、相关工作
A.面向3D数据的深度学习
由于CNNs在图像和视频输入上表现出了巨大的成就,许多先前的工作将原始的不规则三维数据转换为规则的数据形式,如体素[ 29 ] - [ 34 ]和多视图[ 35 ] - [ 37 ]。然后可以使用标准的卷积神经网络( CNNs )。然而,这些方法存在数据转换的误差,例如视点选择和渲染图像或体素的分辨率。为了避免离散化误差,基于点云输入的方法自开拓者点网络[ 14 ]以来备受瞩目,该工作首先以端到端的方式直接处理点云。PointNet[ 14 ]使用点态MLP和最大池化作为对称函数学习无序点云的全局特征,用于分割和分类任务。然后,提出了PointNet+ + [ 15 ],通过逐层聚合和学习三维欧氏空间中局部邻域的局部特征来进行分层点特征学习。FlowNet3D [ 17 ]和我们的场景流任务方法都使用了PointNet+ +的分层点特征学习[ 15 ]。
SPLANet [ 38 ]在高维多面体格中联合估计2D和3D语义分割,并采用双边卷积层( BCL ) [ 39 ] [ 40 ]。也有一些基于图[ 41 ]、[ 42 ]和三维网格[ 43 ] - [ 45 ]直接处理三维点云的方法。Rand LA [ 25 ]是最近提出的一种大规模三维点云语义分割方法。它利用局部空间编码显式地提取局部几何模式,并使用注意力池化代替最大池化。我们的双注意力嵌入方法受到了注意力池化的启发[ 25 ],但具有不同的任务特点:语义分割侧重于对每一个点进行分类,而两帧点云的相关性是场景流任务中的关键问题。并且我们提出了一种新的具有两种不同注意力的双重注意力嵌入方法。
B.场景流估计
许多研究工作从RGB立体[ 4 ] - [ 11 ]和RGB - D数据[ 46 ] - [ 48 ]估计场景流。这些工作有的使用带有运动平滑正则项的变分法[ 4 ] - [ 6 ],有的依赖于局部块[ 8 ],[ 9 ]或对象[ 7 ],[ 11 ]的刚性假设。这些方法与我们基于点云输入的方法相关度较低。
随着自动驾驶和服务机器人中常用的激光雷达的出现,从原始点云估计场景流的方法正在发展。Dewan等[ 12 ]假设局部几何恒常性,将LiDAR扫描刚性场景流估计问题建模为因子图表示的能量最小化问题。Ushani等[ 13 ]利用原始LiDAR数据构建滤波后的占用网格,然后通过期望最大化( EM )算法估计局部刚性场景流。Zhang等[ 49 ]估计自我运动来表示背景的刚性运动和物体的单独刚性运动,以合成场景的完整场景流。Zhang等[ 50 ]学习物体分割和单个物体的刚性运动。我们的方法通过端到端的方式从原始点云中学习软对应,并且不依赖于刚性假设。
随着对原始点云进行三维深度学习的发展,一些方法直接从原始点云估计场景流。Wang等[ 51 ]提出了一种可学习的参数化连续卷积,并在多个任务上对卷积进行测试。他们也在场景流估计任务上进行测试,但很少给出实现细节,并且他们的测试数据集属于Uber,不公开。Flow Net3D [ 17 ]结合层次Point Net + + [ 15 ],通过新颖的流嵌入层学习场景流。HPLFlowNet [ 18 ]提出了DownBCL、UpBCL和CorrBCL操作来恢复和学习多面体点阵中的信息并估计大规模点云中的场景流。但是全变分点阵中的重心插值引入了误差[ 18 ]。我们期望利用原始点云的灵活性,不将点插值到格点。PointPWC-Net [ 19 ]利用基于图像块分割方式和PWC - Net [ 20 ] [ 21 ]的分层流求精思想来估计场景流。本文着眼于两帧点云更有效的点对应,提出了一种新颖的双注意力流嵌入方法。我们还将场景流估计网络应用到LiDAR里程计任务中,展示了我们方法的应用能力。
3、问题定义
在这一部分,我们阐述了三维点云场景流估计的任务。连续两帧图像中存在两组点云。场景流是一个向量,表示第一帧中的每个点如何流向第二帧中的另一个位置,任务是在没有任何假设的情况下估计第一帧中每个点的场景流。具体来说,我们提出的分层注意力网络从连续的两帧中接收两个采样的点云( PC )作为输入。两组点云分别为t帧P1 = { xi∈R3 | i = 1,..,N1 }和t + 1帧P2 = { yj∈R3 | j = 1,..,N2 },其中xi和yj为点的三维坐标。对于P1中的每个点pi,网络输出场景流S = { s i∈R3 | i = 1,..,N1 }。
需要注意的是,由于感知到的两个点云分别在不同时刻从环境中离散采样,因此两帧中的点不需要具有相同的数量或相互对应。即预测的Δ P2 = { x i∈R3 | x i = xi + s Δ i,i = 1,..,N1 }不期望与P2对应。每个点pi的场景流si是由邻近点的信息加权估计。这种不对应符合LiDAR获取的连续两片点云的特点。在真实LiDAR扫描数据上的实验证明了我们的网络在非对应点云上的性能。
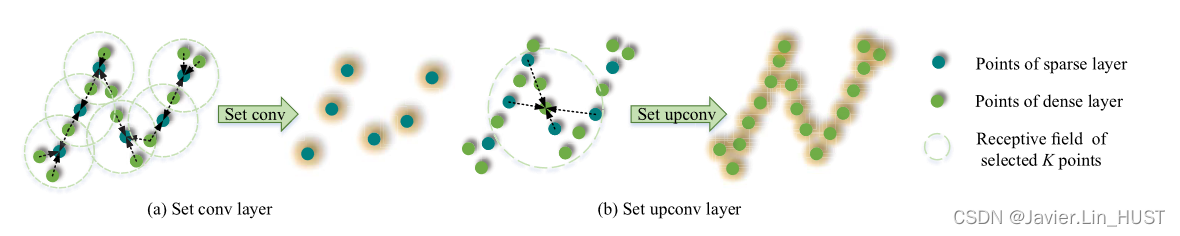
图1 . set conv层和set upconv层。set conv层用于第IV - A节的点特征编码和第IV - B节的流特征编码,set upconv层用于第IV - C.1节的流细化。本文从稠密点中采样稀疏点,因此稀疏点是稠密点的一部分。
4、三维点云场景流的分层注意力学习
在本节中,介绍了提出的场景流层次注意力学习网络。网络架构如图4所示。其中有三个基本层:set conv层、double attention embedded层和set upconv层,如图1和2所示 .新的双注意力点混合嵌入层的细节如图3所示。3层构成3个主要模块:分层点特征编码、注意力点混合、层次化注意力流细化。然后,我们将在下面的小节详细介绍每个模块。最后,阐明了所提网络的整体架构。
A.分层点特征编码
两帧的点云首先分别进行编码。对于每个点云而言,编码过程是分层的,这也为通过跳跃连接实现场景流的分层细化带来了好处。关于点特征编码模块到流细化模块的跳跃连接的更多细节在第IV - C.1节和第IV - C.4节。
对于点云的分层点特征编码,我们采用PointNet + +中的set conv层[ 15 ]。由于点云在三维空间中不规则分布,因此在图1 ( a )中通过考虑每一层中的欧氏距离对点特征进行聚集和编码。对于一个set conv层,输入为n个点{ pi = { xi,fi } | i = 1,..,n },其中每个点pi具有三维坐标xi∈R3和特征fi∈Rc ( i = 1 , ... , n)。该层的输出为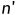 个( < n)点{ pj' = { xj',fj' } | i = 1,.., },其中每个点pj具有三维坐标xj'∈R3和特征fj'∈Rc ( j = 1 , ... , )。具体来说,在第一组卷积层中通过随机抽样,在后一组卷积层中通过最远点采样( Farthest Point Sampling,FPS ),从输入的n点中采样n个点。(之前的工作在第一层使用FPS。我们在第一层中使用随机抽样的原因将在第IV - D节中解释。)直接输出每个采样点pj'的三维坐标xj',但提取特征fj'如下。
个( < n)点{ pj' = { xj',fj' } | i = 1,.., },其中每个点pj具有三维坐标xj'∈R3和特征fj'∈Rc ( j = 1 , ... , )。具体来说,在第一组卷积层中通过随机抽样,在后一组卷积层中通过最远点采样( Farthest Point Sampling,FPS ),从输入的n点中采样n个点。(之前的工作在第一层使用FPS。我们在第一层中使用随机抽样的原因将在第IV - D节中解释。)直接输出每个采样点pj'的三维坐标xj',但提取特征fj'如下。
对于每个pj',从n个输入点中选择K个最近邻( Nearest Neighbors,KNN ) { pkj = { xki,fki } | k = 1,..,K },其中每个近邻pkj具有三维坐标xki和特征fki。然后,利用参数可学习的共享多层感知器( Multi-Layer感知器,MLP )和最大池化,对每个采样pj',从选择的K个点中学习局部特征fj'∈Rc'。特别地,应用于K点的共享MLP实现了特征维度从c + 3 (将xk j-x j'和f j)到c'。然后应用于K点的每个特征维度的最大池化将K点特征聚集到一个局部聚合的点特征。
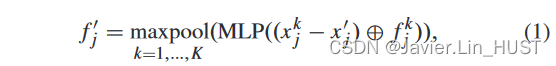
其中⊕表示两个向量的串联。maxpool表示最大池化操作。
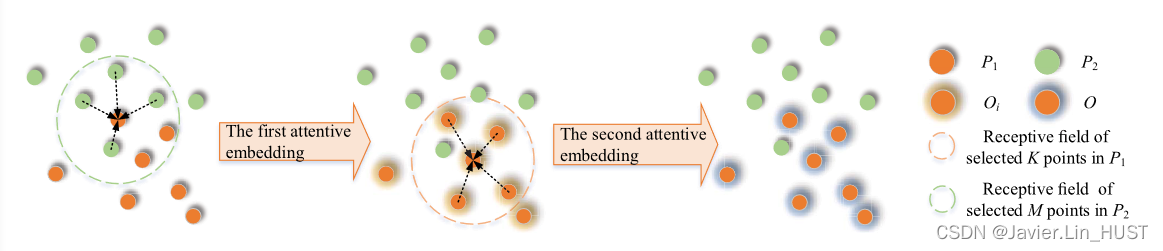
图2 .我们的双注意力流嵌入中的嵌入关系图以基于图像块分割的方式呈现。不同边缘颜色的点是指该点包含由周围选定点聚合而成的流嵌入特征,箭头表示每次嵌入的方向和位置。关于这两个注意事项的详细介绍见图3。
B. Attentive Point Mixture
为了估计非对应点集中的场景流,需要从两组点中进行加权流嵌入,即通过P2中的一些采样近邻点来估计P1中每个流点的目标位置。为了使第1帧中每个点获得更大的感受野,同时利用两组点在三维欧氏空间中的结构信息,我们采用patch-to-patch的方式[ 19 ],从两组点中学习运动编码。此外,我们期望更多地关注匹配的区域和特征,以找到正确的流动方向。因此,针对点混合提出了一种新颖的双注意力嵌入层。
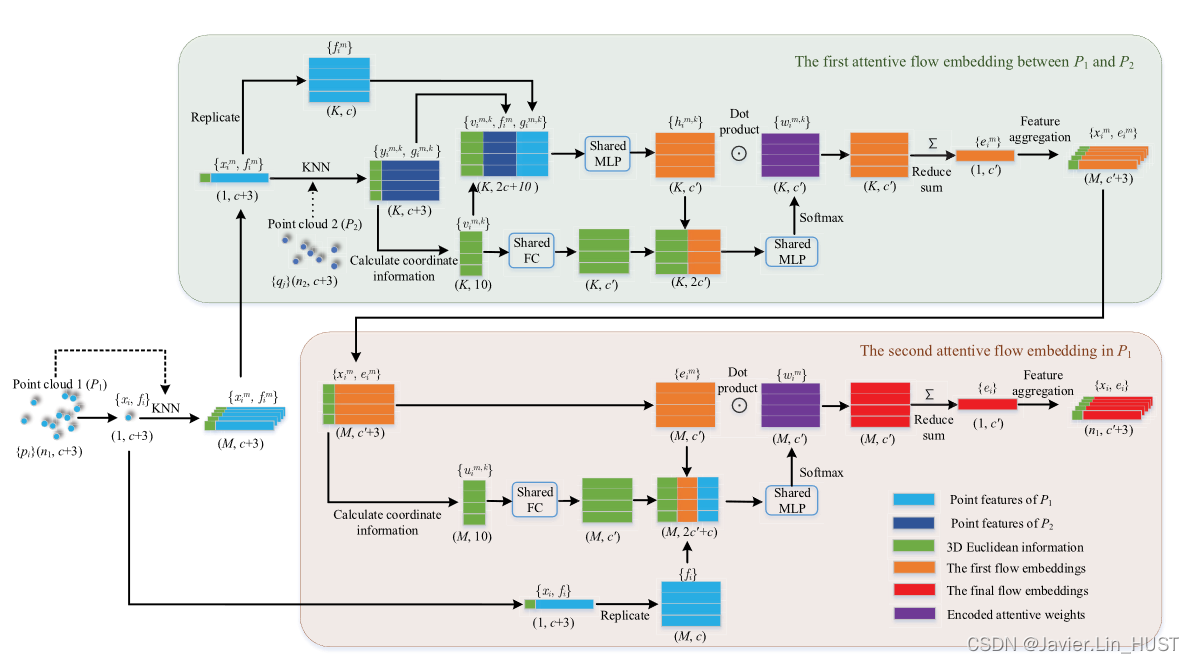
图3 .我们的双注意力流嵌入方法的详细计算示意图。详细过程描述见第四- B节。
注意力嵌入层的输入为两组点云:P1 = { pi = { xi,fi } | i = 1,..,n1 }和P2 = { q j = { y j,g j } | j = 1,..,n2 }。其中,xi,yj∈R3表示三维坐标,fi,gj∈Rc表示点pi,qj的特征。该层输出O = { oi = { xi,ei } | i = 1,..,n1 },其中ei∈Rc是学习的流嵌入,对P1中的点pi进行点运动编码。
图2简要展示了嵌入过程,每个点pi在P1中选择M个最近邻点Pi = { pmi = { xmi,fmi } | m = 1,..,M },每个点pi在P2中选择K个最近邻点Qmi = { qm,Ki = { ym,Ki,gm,Ki } | k = 1,..,K }。对于第一次注意力嵌入,首先利用P2中的K个点Qmi对点运动进行编码。将编码后的信息嵌入到pm i中,并将点特征fm i更新为第一个流嵌入em i ( m = 1 , ... , M)。然后,对于第二个注意力嵌入,将得到的M个流嵌入Oi = { om i = { x m i,em i } | m = 1,..,M }聚合为pi ( i = 1 , ... , n1),并将点特征fi更新为最终的流嵌入ei。最终输出为O = { oi = { xi,ei } | i = 1,..,n1 }。关于两个注意力嵌入的细节如图3所示。
对于第1个注意嵌入:pm i = x { m i,fm i },{ q m,k i = y { m,k i,gm,k i } } K k = 1→r m i = x { m i,em i } ( i = 1 , ... , n1 ; m = 1 , ... , M),首先计算三维欧氏空间信息:
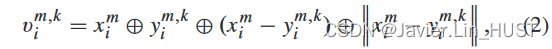
其中||·||表示两个三维坐标之间的欧氏距离。第一个流嵌入使用了来自两帧点云的特征和三维欧氏空间信息。第一个注意加权前的流嵌入计算公式为:
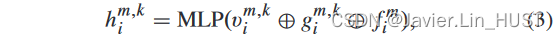
式中:himk∈RC。此外,空间结构信息不仅有助于确定点的相似性,而且有助于确定被查询点的软聚合权重,因此在注意力权重学习中也使用了三维欧氏信息vm,k i∈R10。第一个注意权重为:
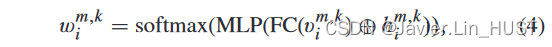
其中,全连接层( FC )用于点位置编码,softmax激活函数用于归一化注意力。位于xm i处的第一个注意力流嵌入为:
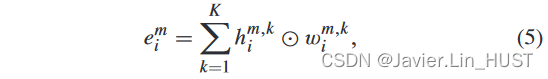
其中,表示点积。即位于M个位置{ xmi | m = 1,..,M }的流嵌入为Oi = { omi = { xmi,emi } | m = 1,..,M }。
其次,对于第二个注意力嵌入:pi = { xi,fi },{ rmi = { xmi,emi } } Mm = 1→oi = { xi,ei } ( i = 1 , ... , n1),首先计算三维欧氏空间信息:
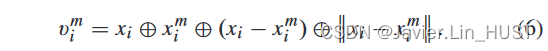
对于第2个嵌入,关键是决定如何利用中心点和三维局部几何结构特征对第1个流嵌入进行加权聚合。因此,对emi的第二个关注权重为:
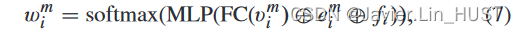
位于xi的最终注意力流嵌入为:
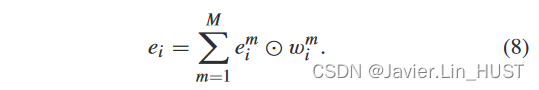
多个3D欧氏信息的使用受到了3D语义分割[ 25 ]的启发。基于场景流在每一对patch点之间的了解,我们的双注意力嵌入方法将MLP应用于注意力之前的初步串联特征,而在文献[ 25 ]中,进入MLP的是加权信息。此外,由于注意力加权前的特征已被编码为匹配信息,丢失了原有的空间信息,因此我们重用空间信息实现软加权。对比实验和消融研究验证了我们第五部分设计的有效性。
类似于[ 17 ],在我们的双重注意力流嵌入过程之后使用set conv层进行流编码。为了强调其效果,我们将其命名为流特征编码层。进一步的流编码将流特征混合在更大的感受野中,使得无法区分的物体获得更多的周围信息,也使得场景流更加平滑。第V - D.4节的消融研究展示了进一步流编码的增益。
C.层次化的注意力流细化
层次化的注意力流细化模块被设计用来逐层传播和细化场景流,其中关键组件是流细化层。如图4 ( b )所示,每个流精化层有4个关键组件:set upconv层、位置更新层、注意力流重嵌入层和流修正层。现分述如下:
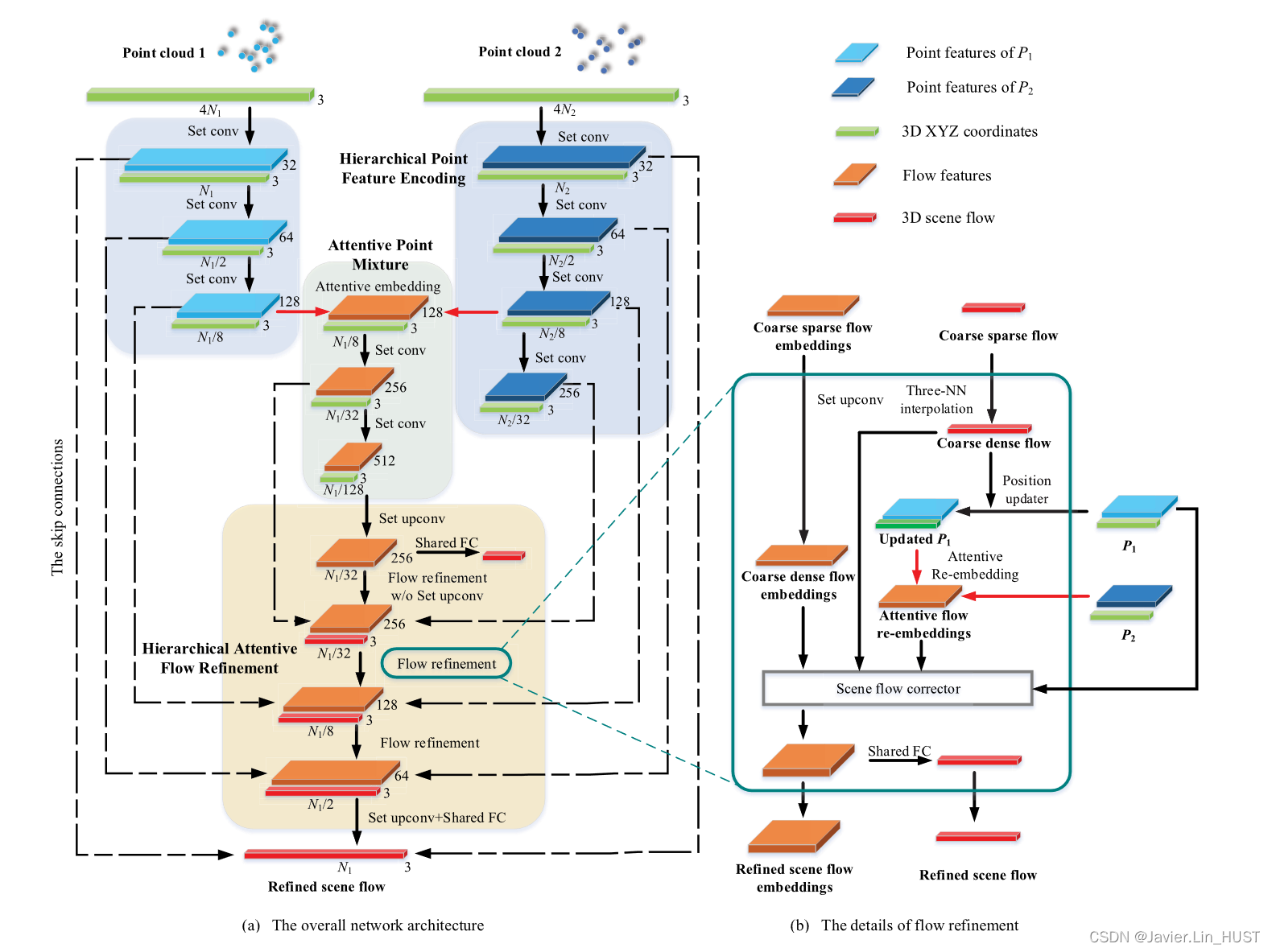
图4 .我们提出的用于场景流估计的网络的架构。给定两帧点云,网络由粗到精地学习预测场景流。并在第四节对关键模块进行了介绍。
1)Set Upconv层:作为我们的第一步流细化,Set Upconv层[ 17 ]用于从稀疏流嵌入中获得粗略且稠密的流嵌入。如图1 ( b )所示,set upconv层的输入为稀疏的n个点,其流嵌入为{ pi = { xi,fi } | i = 1,..,n },稠密的n’个( n’ > n)点坐标为{ xj’ | j = 1,2,.. n’ }。输出为稠密的n’个点,流嵌入{ p j ’= { x j’,f j ’} | j = 1,..,n’ }。该层通过可学习的KNN特征聚合方式将流特征从稀疏点位置传播到稠密点位置。与set conv层类似,但聚合点坐标不从输入点采样。被聚合的点坐标直接来自分层点特征编码模块的原始密集点坐标。图4 ( a )中的跳跃连接显示了哪些层是连接的。与文献[ 17 ]一样,跳跃连接不仅表示聚合位置,还意味着将集合conv层的输出特征进行串联。
得到的粗密流嵌入是每个流细化过程中需要进一步细化的初步嵌入。
2)Position Updating层:为了后期进行流重嵌入和流修正,首先通过粗稠密流{ si | i = 1,..,n }更新P1中的稠密点位置。粗稠密流由输入的粗稀疏流的三个最近邻( Three-NN )插值得到。
原始点为P1 = { pi = { xi,fi } | i = 1,..,n }。然后,将粗稠密流添加到点的原始坐标中。则更新后的点云为P1' = { pi' = { xi',fi } | i = 1,..,n },其中xi' = xi + si。
3)Attentive Flow Re-Embedding层:基于位置更新层后第一帧中更新的点云和第二帧中的点云,采用与第IV - B节中关注流嵌入层相同的方法生成流重嵌入。我们将其称为"重嵌入",以突出优化初始流嵌入在流细化模块中的作用。该层的输出流重嵌入记为R = { ri | ri∈Rc } ni = 1。流重嵌入是关于更新后的P1和P2,因此流重嵌入表示粗流之后的"剩余流"。将剩余部分流和粗流输入到后续的流量校正层进行流优化。
4)Flow Correcting 层:流修正层是对流嵌入进行修正。该层的操作是一个具有四个输入的共享MLP:粗稠密流嵌入E = { ei | ei∈Rc } ni = 1 (第IV - C节设置的Conv层输出),上采样粗稠密流S = { si | si∈R3 } ni = 1 (在第IV - C.2节的位置更新层获得。),流重嵌入R = { ri | ri∈Rc } ni = 1 (第IV - C节注意力流再嵌入层的输出。3),第一帧的点特征F = { fi | fi∈Rc } ni = 1 (从层次点特征编码模块中跳跃连接)。具有可学习权重的MLP可以优化粗稠密流嵌入。输出为细化后的流嵌入E = { e i | e i∈Rc } n i = 1。公式表示为:
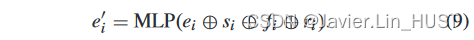
然后通过精化流嵌入ei上的共享FC获得精化场景流si,具体如下:
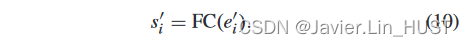
5)流细化层的架构:流动细化层的概况如图4 ( b )所示。输入为粗流嵌入、粗稀疏流和两帧(从层次点特征编码模块中链接跳过)的点云;输出为精炼场景流嵌入和精炼场景流。
首先,将粗稀疏流嵌入输入到设置好的卷积层,得到粗稠密流嵌入。粗稠密流由输入的粗稀疏流插值得到。然后,通过位置更新器更新P1。更新后的P1和P2用于注意力流重嵌入,得到流重嵌入。接着,将粗稠密流嵌入、粗稠密流、流重嵌入和P1的特征输入场景流校正器并输出精化后的场景流嵌入。最后,在精化后的场景流嵌入上通过一个FC得到精化后的场景流。
6 )层次化注意力流细化模块架构:对于第一个流精化,初始的粗稠密流由应用于第一个粗稠密流嵌入的共享FC生成,该FC由Attentive Point Mixture的输出建立。然后,有三个流细化层。最后,为了节省GPU内存,使用设置的upconv层和共享的FC层来估计最终的精化场景流。
D. More - For - less分层注意力网络架构
整个网络架构如图4 ( a )所示。网络的输入为连续两帧的点云P1和P2,提出的网络架构由3个模块组成:分层点特征编码、注意力点混合和分层注意力流细化。层次点特征编码模块对P1有三个集合conv层,对P2有四个集合conv层。相同金字塔层级的点特征编码模块共享可学习权重。点混合模块有1个注意力嵌入层和2个集合卷积层。层次化注意力流细化模块有3个流细化层和1个最终流估计层(即建立conv +共享FC)。粗流由设置好的流嵌入上的共享FC初始化。然后,对粗流逐层细化。所有Mlp都具有Batchnorm和Relu激活。
为了平衡精度和资源消耗,我们的网络具有不同的输入输出点数,如图4 ( a )所示。若在分层点特征编码模块的第一层采用随机抽样,则所有输入点的场景流可以通过多次测试进行估计。关于网络结构细节的对比实验见第V - D节。
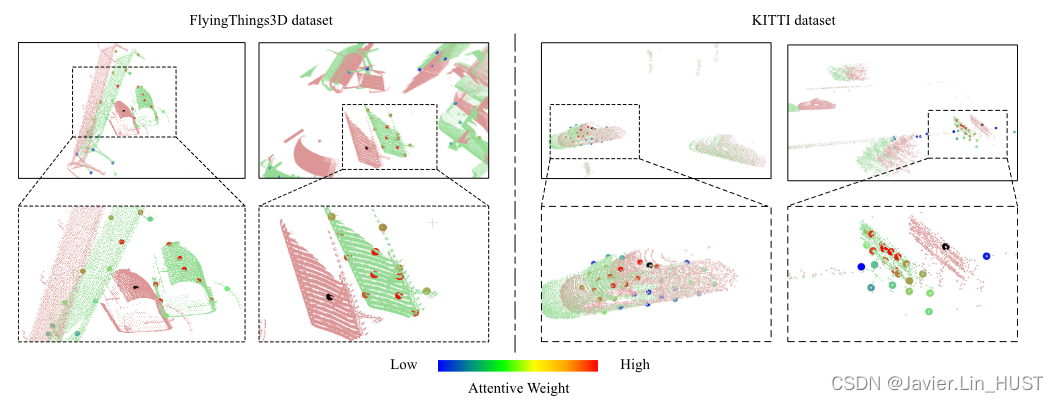
图5 .注意力图的可视化。我们展示了由我们训练的模型生成的查询点上的四个注意力图的例子。红色小点为P1,绿色小点为P2。每个P1中的大黑点即为嵌入中心点。P2中具有其他颜色的大点为查询点,其颜色表示关注权重的大小。嵌入中心点实际对应的若干个查询点具有最高的注意力权重,符合人类从若干个对应点软估计场景流的直觉。
E.注意力可视化的讨论
我们使用注意力权重来软估计场景流。不同于以往使用最大池化选择最大激活[ 17 ]或者仅仅使用相对位置编码[ 19 ]进行加权的方法,我们使用基于相关性特征和3D欧式特征的注意力对近邻信息进行两次加权。由图5可知,距离较近的点不一定是关注度较高的点,来自相似结构的点具有较高的关注度权重。此外,中心黑点实际对应的被查询点具有最高的注意力权重,符合人类直觉。
表1在Flyi Ngthings3D [ 10 ]和Kitti场景流数据集[ 28 ]上进行了量化评估。所有方法均在Flyi Ngthings3D数据s E t上训练[ 10 ]。顶部部分展示了Flyi Ngthings三维数据[ 10 ]上的eva L Uat I O N结果,底部部分展示了Kitti [ 28 ]上的eva L Uat I O N结果(去掉地面)。Flownet3D [ 17 ]的结果来自文献[ 18 ]的实现。文献[ 18 ]中Flownet3D的实现基于与Hplflownet [ 18 ]相同的数据预处理和设置,优于文献[ 17 ]中的结果。较低的值对于由Epe3D、Outliers3D和Epe2D组成的误差度量更好。对于由Acc3D严格、Acc3D松弛和Acc2D组成的准确性度量,值越高越好
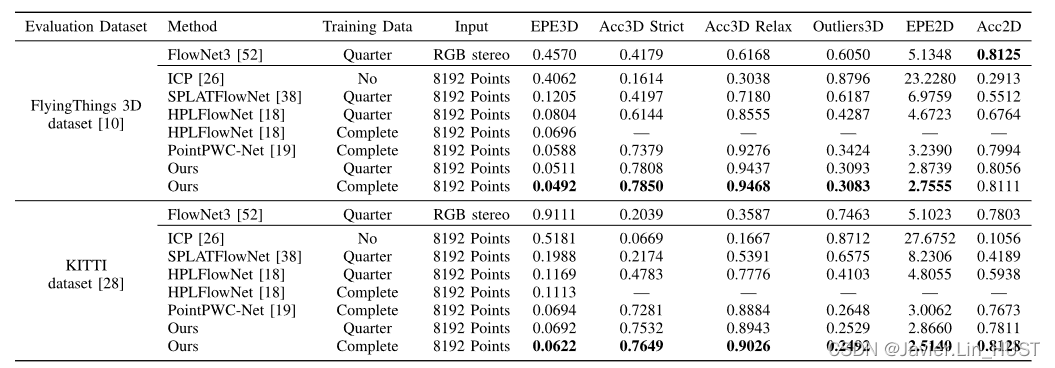
5、实验
我们使用一种有监督的方法对三维点云中的场景流进行学习。本部分首先介绍了训练损失和训练细节。然后,由于场景流的地面真实度难以获取,与以往研究[ 17 ] ~ [ 19 ]一样使用大规模合成的FlyingThings3D数据集[ 10 ]进行训练和评估。然后,将训练好的模型在KITTI场景流数据集[ 28 ]的真实LiDAR扫描数据上进行测试,以证明其泛化能力。在两个数据集中,我们的方法与最先进的方法进行了比较。最后,进行了多个消融研究来分析所提出网络的关键组成部分。
表2与Flownet3D [ 17 ]相比,Flyi Ngthings3D [ 10 ]和Kitti场景流数据集[ 28 ]上的定量eva L Uat I O N结果。由于Flownet3D [ 17 ]有2048个输入点,为了与Flownet3D [ 17 ]进行公平比较,我们用2048个输入点实现并测试了我们的模型。Flownet3D [ 17 ]的结果来自文献[ 18 ]的实现。文献[ 18 ]中Flownet3D的实现基于与Hplflownet [ 18 ]相同的数据预处理和设置,优于文献[ 17 ]中的结果。

A. 所提网络的训练细节以及评价指标
1)训练损失:所提出的网络以多尺度监督的方式进行训练,如先前在光流估计[ 20 ],[ 21 ]和PointPWC - Net [ 19 ]方面的工作。尺度l的真实场景流记为Sl = { sl i∈R3 | i = 1,..,Nl 1 },每个尺度l的预测场景流记为ρ Sl = { ρl i∈R3 | i = 1,..,Nl 1 }。我们的网络中监督了四种尺度的场景流。训练损失为:
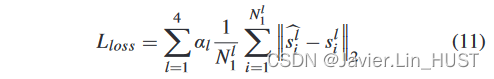
式中:||·||2为L2范数,α l为l尺度损失函数的权重。将最后一次细化的场景流表示为l1尺度,α1 = 0.2,α2 = 0.4,α3 = 0.8,α4 = 1.6。如图4所示,我们的网络输入4N1 = 8192点,输出4个尺度的场景流估计:N1 1 = N1 = 2048点,N2 1 = 1/ 2 N1 = 1024点,N3 1 = 1 /8 N1 = 256点,N4 1 = 1/ 32 N1 = 64点。
2 )实施细节:在训练过程中,输入点分别从两帧图像的点云中随机采样。如果对每一帧单独进行随机抽样,则第一帧中的点在第二帧中可能没有对应点。在评估两个数据集时也使用了采样方式。遵循前人的工作[ 17 ] ~ [ 19 ],网络以仅包含坐标信息的点云作为输入。所有实验均在Tensor Flow 1.9.0 Titan RTX GPU上完成。采用Adam优化器进行训练,β1 = 0.9,β2 = 0.999。学习率为指数衰减,初始学习率为0.001。衰减步长为40000,衰减率为0.7。训练批次大小为8。
3 )评价指标:为了公平比较,我们采用与以前工作[ 17 ] - [ 19 ]相同的评价指标来评估我们的模型。对于所有场景流估计的评估,我们只评估我们网络输出的最后一个精化的场景流。S = { si∈R3 | i = 1,..,N1 }表示地面真实场景流,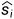 = { ∈R3 | i = 1,..,N1 }表示预测场景流。评价指标如下所示:
= { ∈R3 | i = 1,..,N1 }表示预测场景流。评价指标如下所示:
3D端点误差( 3D End Point Error,EPE3D ) ( m ):1 N1 N1∑i = 1 s i - si。
严格形式的场景流估计精度( Acc3D Strict):满足s i - si < 0.05 m或 i - si si < 5 %的 i百分比,表示EPE3D < 0.05 m或相对误差< 5 %的3D点的百分比。
场景流估计精度的松弛形式( Acc3D Relax ):s ρ i使得s ρ i - si < 0.1 m或ρ ρ i - si < 10 %的百分比,表示EPE3D < 0.1 m或相对误差< 10 %的三维点的百分比。
3D异常值百分比( Outliers3D ):指s ρ i - si > 0.3 m或ρ ρ i - si > 10 %的s ρ i百分比,代表EPE3D > 0.3 m或相对误差> 10 %的3D点百分比。
2D端点误差( EPE2D ) ( px ):1 N1 N1∑i = 1∥ di-di∥∥,其中预测的2D光流 di和真实的2D光流di是通过将初始的3D点云和场景流得到的3D点云投影到2D图像中得到的。EPE2D测量以像素为单位的平均二维光流估计误差。
光流估计精度( Acc2D ):满足∥di-di∥< 3 px或di-di < 5 %的点占总点数的百分比,即EPE2D < 3 px或相对误差< 5 %的点占总点数的百分比。

图6 .场景流量估计精度的可视化。左图为FlyingThings3D数据集上的结果,右图为KITTI数据集上的结果。蓝色点为P1。绿色点和红色点即为预测的流点P 2,即P1 + S。并且绿色点预测相对正确,红色点预测相对错误(采用Acc3D Relax进行测量)。
B. 在Flyingthings3D上的训练与评估
由于真实场景流难以获取,我们采用常用的FlyingThings3D数据集[ 10 ] (一个大规模的合成数据集)进行训练。我们在本节也使用它进行测试。
1) Experiment Details:原始的FlyingThings3D数据集[ 10 ]由RGB图像、视差图、真实光流和遮挡图组成。从ShapeNet [ 53 ]中采样的场景中存在多个随机移动的物体。遵循前人工作[ 18 ]、[ 19 ]相同的预处理步骤,利用二维数据和深度信息重建三维点云和地面真实场景流。此外,我们还剔除了深度大于35m的点,只使用了点的三维坐标。预处理后的训练数据集包括19 640对点云,评价数据集包括3 824对。首先在四分之一的训练数据集( 4910对)上训练网络,然后加载完整的训练数据集对训练好的模型进行微调。该网络在每个测试( 3824对)的整个评估数据集上进行评估。其他训练详见V - A部分。
2)和SOTA进行比较:表I展示了在FlyingThings3D数据集上的定量评估结果[ 10 ],评估指标由V - A部分介绍。我们的方法也与使用立体输入的FlowNet3 [ 52 ]进行了比较。对于FlowNet3 [ 52 ]的结果,如反向视差估计[ 18 ],去除了极端错误的预测。FlowNet3 [ 52 ]由于专门针对二维光流和视差估计进行了优化,因此在2D指标上具有良好的性能,但在3D指标上表现较差。2D中的优化使得3D度量对误差敏感。多重嵌入对于精化的好处已经在PointPWC - Net中得到了验证[ 19 ]。我们进一步验证了我们的双注意力嵌入方法在第V - D节消融研究中的贡献。SPLATFlowNet是Gu等人基于SPLATNet [ 38 ]的场景流估计实现。[ 18 ]。它没有细化层并且我们的优于它。尽管HPLFlowNet [ 18 ]利用了不同尺度信号的块相关性和多重融合性,但与HPLFlowNet [ 18 ]相比,本文方法仍具有优越性。第一个原因可能是HPLFlowNet [ 18 ]将信号从连续域插值到离散域,丢失了三维欧氏信息。原始输入只有3D位置信息,因此3D欧氏信息是关键组成部分。第二个原因是我们有益的双重注意力嵌入方法。此外,Flow Net3D [ 17 ]和HPLFlow Net [ 18 ]虽然都有细化阶段,但并没有在不同尺度上使用显式的多流监督。Point PWC-Net [ 19 ]尝试了不同尺度下的多流监督细化,并对结果进行了改进。由于流嵌入是场景流估计任务中表征点云相关性的关键组件,我们的方法采用了新颖的双注意力流嵌入方法和新颖的多反而少网络设计。结果表明,我们的算法明显优于PointPWC - Net [ 19 ]。由于相关工作FlowNet3D [ 17 ]使用2048个点作为输入,因此我们也使用2048个输入点实现了我们的模型,并在表II中与FlowNet3D [ 17 ]进行了比较。与Flow Net3D [ 17 ]相比,本文方法的性能有较大提升。我们认为贡献最大的是双重注意力嵌入方法和分层细化中的多重嵌入。总体而言,我们的方法在3D点云输入方面优于所有最近的工作,并且在所有3D指标上都比2D方法高出很多。
我们不仅将我们的方法与最先进的方法进行了比较,而且在第V - D节的烧蚀研究中展示了每个建议成分的贡献。定性结果如图所示。6和7 .由于大平面、重复模式、大运动等特点,所选场景对FlowNet3D [ 17 ]具有挑战性。然而,尽管存在各种挑战,但对于我们的方法,大多数是准确估计的。
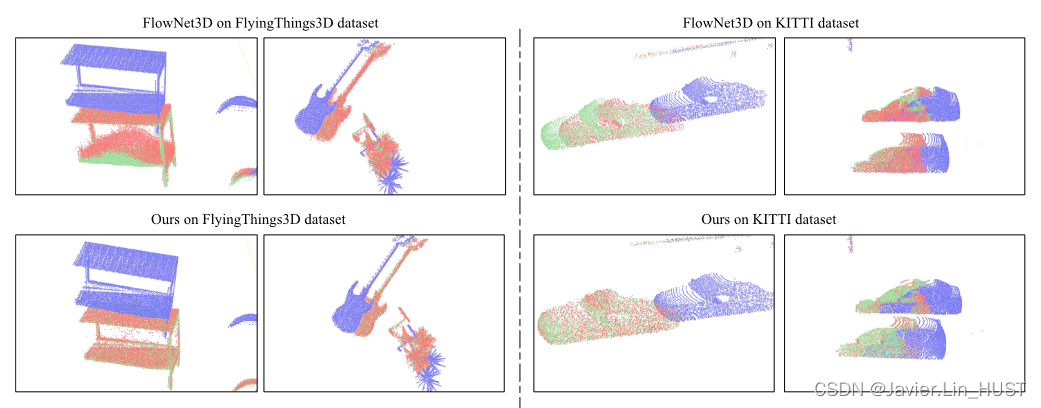
图7 .场景流量估计的细节可视化。左图为FlyingThings3D数据集上的结果,右图为KITTI数据集上的结果。蓝色点为P1。其中绿色点为P2,红色点为预测的流点P2。
C.对Kitti真实激光雷达扫描的评价
在本小节中,为了分析所提出的模型对未知真实数据的泛化能力,在没有任何微调的情况下,直接在KITTI [ 28 ]的真实Lidar扫描中评估在FlyingThings3D [ 10 ]上训练的模型。
1 )实验细节:KITTI Scene Flow 2015 [ 28 ]是基于RGB立体视觉的场景流评估的常用数据集。由200个训练场景和200个测试场景组成。为了对基于点的方法进行评价,并与当前最先进的方法进行公平比较,我们对数据进行预处理,步骤与之前的工作相同[ 17 ] - [ 19 ]。具体来说,从视差和光流地面真值中恢复三维点云和场景流地面真值。深度超过35m的点像FlyingThings3D [ 10 ]一样被去除。地面被移除的高度小于0.3 m,因为它的运动在自治中是不有用的,移除地面是一个常见的步骤[ 12 ],[ 13 ],[ 17 ] - [ 19 ]。由于测试集的视差不可得,因此使用可获得原始3D数据的142个训练场景进行评估。
2)和SOTA进行比较:定量评价结果见表1和表2。总体而言,尽管FlowNet3 [ 52 ]在FlyingThings3D数据集[ 10 ]上具有良好的2D度量性能,但我们的方法在2D度量上优于包括FlowNet3 [ 52 ]在内的所有最先进的方法。我们的方法在KITTI [ 28 ]上的2D指标上优于FlowNet3 [ 52 ],可能是由于我们的3D方法具有更好的泛化能力。我们的方法只需要3D点坐标作为输入,仅从3D欧氏信息中学习几何变换,而基于RGB立体视觉的FlowNet3 [ 52 ]使用的是颜色信息,合成数据与真实数据差距较大。部分可视化结果如图所示。6和7展示了我们的方法在KITTI上的良好泛化效果。
表3 对More - For - less网络架构的消融研究。Bach尺寸是GPU所能承受的最大尺寸

表4双重注意嵌入方法的消融实验

D. 消融实验
在本小节中,对我们方法的组成部分进行了一系列的消融研究。并且这些研究分析了网络中各个成分的贡献。对于所有消融研究,我们使用训练集的四分之一( 4910对)用于减少训练时间,并在FlyingThings3D上对整个评估集进行测试。
表5在更多的三维坐标信息的消融实验

表6点混合模块嵌入水平的消融研究

表7在更多的层面上进行监督的消融研究

1)More-for-Less网络结构:More-for-Less架构意味着输入点是预测点的4倍。特别地,我们设定输入点数量为8192,预测点数量为2048。比较组包括2048个输入用于2048个预测( less-for-less )和8192个输入用于8192个预测( more-for-more )。More-for-Less架构中的预测点可以包含比少人架构中更多的信息。同时,more-for-more架构有更多的精化点,比我们的More-for-Less架构消耗更多的GPU内存。它们都在不同批量大小的单个Titan RTX GPU上进行训练,评估结果如表III所示。值得注意的是,More-for-Less具有与less - for - less相同的批处理大小,因为set conv层占用的内存少,而嵌入过程占用的内存多。与more-for-more和less-for-less相比,我们的方法利用了更多的信息,减少了资源消耗,在一个GPU上实现了最好的预测。此外,我们还实现了如表III所示的三个版本的Point PWC - Net。结果表明,与2048个输入点相比,使用8192个输入点的确可以提高PointPWC - Net的性能。这意味着PointPWC - Net也受益于更多的输入信息。
2)双重注意嵌入:我们提出了分层架构中的双重注意力嵌入方法。为了证明提出的注意力方法的有效性,我们对有注意力和无注意力的网络进行训练和评估。同时,我们直接使用语义分割中的LocSE和注意力池化[ 25 ]来代替我们的第一个注意力嵌入过程作为一个朴素的基于注意力的版本进行比较,这里我们将注意力池化的MLP移动到注意力之前,以便更接近我们的方法,否则结果会更差。表4展示了我们的注意力方法对性能的提升。
3)更多的三维坐标信息:我们在嵌入时使用如图3所示的10维坐标信息,类似于语义分割[ 25 ],而不是只使用查询点的相对坐标[ 17 ],[ 19 ]。从表5中可以看出,10维的坐标信息具有更好的性能。
4 )点混合模块中合适的嵌入层:Flownet3D [ 17 ]将两片点云嵌入一个中间点密度层次。他们发现加入一些set conv层后可以使得点混合更好。然而,PointPWC-Net [ 19 ]对点混合的合适嵌入水平讨论较少。如何在多层监督中嵌入哪一层的点特征编码成为一个问题。我们对此进行了研究。不同于文献[ 19 ]中初始流嵌入是在最小点密度层上进行的,我们的是在中间点密度水平上进行的。这样可以在后续的set conv层中再次混合初始流嵌入以获得空间平滑性,取得了更好的效果。表VI中的消融研究证明了这一点。
5)是否监督层级越多越好:是否应该对密度最小点级的场景流进行估计和监督是一个问题。我们的网络没有从最小密度层面估计3D场景流。我们认为最稀疏点水平上的监督信号由于空间结构不明显而产生较大误差。如表七所示,并非监督的层级越多越好。
E.在激光雷达里程计上的应用
现有的LiDAR里程计方法大多基于ICP的变体[ 26 ]。由于LiDAR稀疏扫描的相邻帧对应点较少,ICP采用最近点作为对应,多次迭代应用奇异值分解( Singular Value Decomposition,SVD )优化6 - DoF位姿估计。这不仅耗时,而且容易出错。通过我们的场景流网络可以从相邻帧中估计出P1中每个点的正确对应点。然后,可以直接使用SVD一次求解6 - DoF位姿变换矩阵的闭式形式,无需假设对应关系。基于这些讨论,我们将我们的场景流网络应用到LiDAR里程计中,并与基于ICP的方法进行比较。
表8 Kitti测程法数据集激光里程计任务的定量实验结果[ 54 ]。本文定义了100 - 800米所有可测子序列的平均平移均方根误差( % )和旋转均方根误差( ° / 100米)。" * "表示用于训练的序列

1 )我们的方法和实验细节:我们利用SVD一次得到P1和 P2的6 - DoF位姿变换,其中 P2 = { xi∈R3 | xi = xi + s i,i = 1,..,N1 }。场景流s ρ i由我们的网络从P1和P2估计得到。
里程计实验在KITTI里程计数据集[ 54 ]上进行,该数据集由22条序列组成。00 ~ 10序列具有真实性。我们使用00 - 06序列训练网络,07 - 10序列进行测试。在训练过程中,我们通过对点云添加随机旋转和平移来扩充数据,地面真值自身运动随之变化。地面真值场景流si由下式得到:
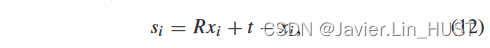
其中R和t分别为相邻帧之间的真值旋转矩阵和平移向量。并且我们使用得到的场景流si来监督我们的网络。
2 )与基于Icp的方法和对话的比较:我们将我们的方法与基于ICP的LiDAR里程计进行了比较。表八的结果表明,我们的方法优于基于ICP的方法。对于我们的方法,关键是估计精确的场景流,以获得P1在第2帧的精确点位置Δ P2。即我们改变了问题形式,在LiDAR里程计任务上得到了比基于ICP的方法更好的结果。与最近基于光流视角的视觉里程计研究一样[ 55 ],基于场景流视角的LiDAR里程计可能值得深入研究。
6、结论
本文提出了一种新颖的场景流分层注意力学习方法。受人类直觉的启发,我们提出的双注意力流嵌入方法关注几个重要的点来软估计场景流。此外,为了平衡精度和资源消耗,提出了一种新型more-for-less网络架构。一系列消融研究证明了我们网络结构设置的有效性。在常见的FlyingThings3D数据集[ 10 ]和KITTI数据集[ 28 ]中的大量实验表明,我们的方法可以达到最先进的性能。所提出的网络也被应用于实际的LiDAR里程计任务。我们的方法不需要假设对应点或迭代,性能优于基于ICP的方法,具有很强的实际应用能力。















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









