






 本文介绍深度图像先验,表明随机初始化的神经网络可作为人工先验用于图像复原。将未训练的ConvNets用于去噪、超分辨率和修复等问题,该方法无需从数据学习网络参数,在多种图像重建任务中表现良好,还能用于理解深度神经网络激活信息。
本文介绍深度图像先验,表明随机初始化的神经网络可作为人工先验用于图像复原。将未训练的ConvNets用于去噪、超分辨率和修复等问题,该方法无需从数据学习网络参数,在多种图像重建任务中表现良好,还能用于理解深度神经网络激活信息。
论文翻译:
Deep Image Prior
摘要:
深度卷积网络已经成为图像生成和恢复的热门工具。一般来说,它们优异的性能归因于它们能够从大量的示例图像中学习到逼真的图像先验。在本文中,我们表明,相反,生成器网络的结构足以在任何学习之前捕获大量的低级图像统计。为了做到这一点,我们表明随机初始化的神经网络可以作为一种人工先验,在去噪、超分辨率和修复等标准逆问题中具有优异的结果。此外,相同的先验可以用来反演深层神经表征来诊断它们,并基于闪光-无闪光输入对恢复图像
除了其多样化的应用外,我们的方法还强调了标准生成器网络架构所捕获的感性偏差。它还弥合了两个非常流行的图像复原方法家族之间的差距:使用深度卷积网络的基于学习的方法和基于自相似性等手工图像先验的免学习方法。
1、引言:
深度卷积神经网络(卷积神经网络)目前在逆图像重建问题中处于领先地位,例如去噪[ 5、20]或单幅图像超分辨率[ 19、29、18]。卷积神经网络也已经在更多的"奇异"问题中取得了巨大的成功,例如从它在某些深度网络中的激活或从它的HOG描述符重建图像[ 8 ]。更一般地说,具有类似架构的卷积神经网络现在被用于生成图像,使用的方法包括生成对抗网络[ 11 ]、变分自编码器[ 16 ]和直接逐像素误差最小化[ 9、3]。
用于图像复原和生成的最先进的卷积神经网络几乎都是在大型图像数据集上训练的。因此,人们可能会假设他们出色的性能是由于他们能够从数据中学习到逼真的图像先验。然而,仅靠学习不足以解释深度网络的良好性能。例如,文献[ 33 ]最近的研究表明,在真实数据上训练得到的泛化性较好的图像分类网络,在随机标签的情况下也会出现过拟合。因此,泛化要求网络的结构与数据的结构"共振"。然而,这种相互作用的本质仍然不清楚,尤其是在图像生成的背景下。
在这项工作中,我们表明,与学习对于构建良好的图像先验是必要的这一信念相反,大量的图像统计信息被独立于学习的卷积图像生成器的结构捕获。对于解决各种图像复原问题所需的统计量来说尤其如此,其中需要图像先验来整合退化过程中丢失的信息。
为了说明这一点,我们将未训练的ConvNets应用于几个此类问题的求解。我们不遵循在大量示例图像数据集上训练ConvNet的常见范式,而是将生成器网络拟合到单个退化图像上。在该方案中,网络权值作为恢复图像的参数化。给定特定的退化图像和任务依赖的观测模型,随机初始化和拟合权重以最大化其似然。
与此不同的是,我们将重建问题建模为一个条件图像生成问题,并表明求解该问题所需的唯一信息包含在用于重建的单个退化输入图像和网络的手工构造结构中。
我们表明,这个非常简单的方法对于标准的图像处理问题(如去噪、修复和超分辨率)非常有竞争力。这一点特别引人注目,因为网络的任何方面都不是从数据中学习得到的;相反,网络的权重总是随机初始化的,这样唯一的先验信息就在网络本身的结构中。据我们所知,这是第一个不需要从图像中学习网络参数而直接研究深度卷积生成网络捕获的先验的研究。
除了标准的图像复原任务外,我们展示了我们的技术在理解深度神经网络激活中包含的信息方面的应用。为此,我们考虑[ 21 ]中的"自然原像"技术,其目标是通过在自然图像集合上对其进行反转来表征深度网络学习到的不变量。我们表明,一个未经训练的深度卷积生成器可以用来替代[ 21 ] (电视规范)中使用的替代自然先验,并显著改善结果。由于新的正则化器,像TV-Norm一样,不是从数据中学习的,而是完全手工制作的,因此产生的可视化避免了使用强大的学习正则化器产生的潜在偏差[ 8 ]。

图1:利用深度图像先验的超分辨率。我们的方法使用随机初始化的ConvNet对图像进行上采样,使用其结构作为图像先验;与双三次上采样类似,该方法不需要学习,但产生的结果更清晰,边缘更锐利。事实上,我们的结果与使用从大数据集中学习到的卷积神经网络的最先进的超分辨率方法非常接近。深度图像先验对我们所能测试的所有反问题都很有效。
2、方法
深度网络通过学习生成器/解码器网络x = fθ ( z )将一个随机码向量z映射到图像x,从而应用于图像生成。该方法可用于从随机分布中采样现实图像[ 11 ]。在这里,我们关注的是这样一种情况,即分布以损坏的观测x0为条件,以解决反问题,如去噪[ 5 ]和超分辨率[ 7 ]。
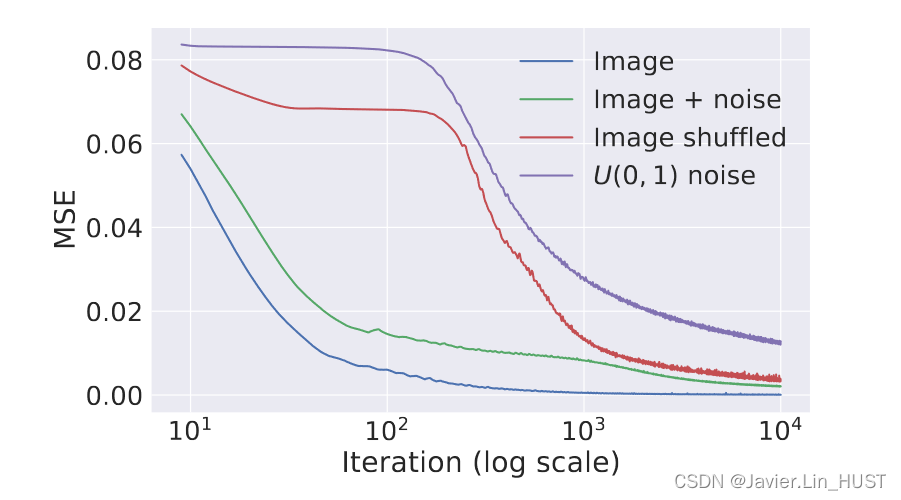
图2:使用的重建任务的学习曲线:自然图像,相同的加i . i . d .噪声,相同的随机扰乱,和白噪声。自然图像的收敛速度更快,而噪声被拒绝。
我们的目的是在了解某一特定发电机网络结构的任何参数之前,研究其选择所隐含的先验信息。我们将神经网络解释为图像x∈R3 × H × W的参数化x = fθ ( z )。其中z∈RC′× H′× W′是编码张量/向量,θ是网络参数。网络本身交替进行卷积、上采样和非线性激活等滤波操作。特别地,我们的大部分实验都是使用带有跳跃连接的U - Net型"沙漏"结构进行的,其中z和x具有相同的空间大小。我们的默认架构有两百万个参数θ (所有使用过的建筑详细信息见补充材料)。
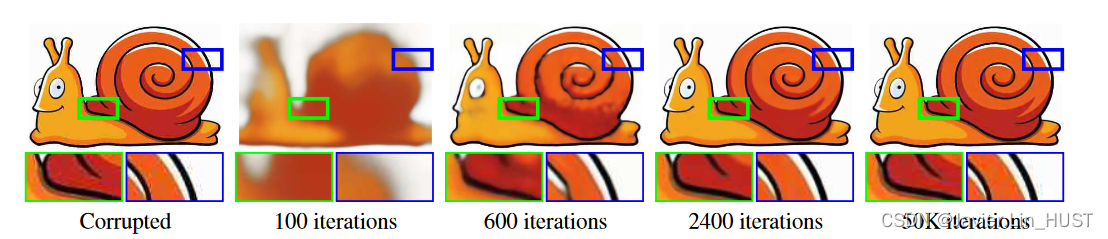
图3:JPEG压缩图像的盲复原。(推荐电子缩放)我们的方法可以恢复具有复杂退化(这种情况下的JPEG压缩)的图像。随着优化过程的进行,深度图像先验允许在去除光晕和块状(迭代2400次后)的同时恢复大部分信号,最终过拟合到输入的(在50K迭代时)。
为了展示这种参数化的力量,我们考虑了诸如去噪、超分辨率和修复等逆任务。这些问题可以表示为该类型的能量最小化问题
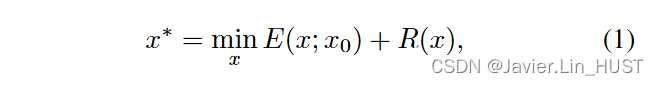
式中:E( x ; x0)为任务依赖数据项,x0为含噪/低分辨率/遮挡图像,R ( x )为正则项。

图4:图像盲去噪。深度图像先验成功地恢复了人造和自然模式。作为参考,展示了一种最先进的非学习去噪方法[ 6 ]的结果。
数据项E( x ; x0)的选择由应用程序决定,将在后面讨论。正则项的选择是比较困难的,它通常在自然图像上捕获一个通用的先验,是许多研究的主题。作为一个简单的例子,R ( x )可以是图像的总变分( TV ),这鼓励解包含均匀区域。在这项工作中,我们将正则化器R ( x )替换为神经网络捕获的隐式先验,如下所示:
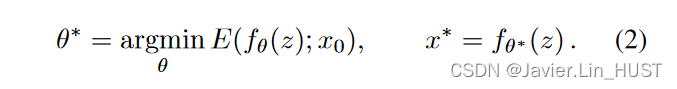
最小化器θ *是使用优化器获得的,例如从参数的随机初始化开始的梯度下降。给定一个(局部)极小点θ *,恢复过程的结果为x * * = f * * ( z )。注意,虽然对代码z进行优化也是可能的,但在我们的实验中,我们并不这样做。因此,除非另有说明,否则z是一个固定的3D张量,具有32个特征图,其空间大小与填充均匀噪声的x相同。我们发现,在每次迭代中额外随机扰动z,在一些实验中可以得到更好的结果( c.f.补充材料)。
对于式( 1 ),式( 2 )定义的先验R ( x )是一个指示函数,对于某一架构的深度ConvNet可以从z产生的所有图像,R ( x ) = 0,对于其他所有信号,R ( x ) = +∞。由于网络的任何方面都不是从数据中预训练的,所以这样的深度图像先验是有效的手工制作的,就像TV规范一样。我们表明这种手工设计的先验对于各种图像复原任务非常有效。
具有高噪声阻抗的参数化。人们可能会疑惑,为什么一个高容量的网络f θ可以作为先验。事实上,人们可能期望能够找到恢复任何可能的图像x的参数θ,包括随机噪声,这样网络就不应该对生成的图像施加任何限制。我们现在表明,虽然几乎任何图像都可以拟合,但网络结构的选择对如何通过梯度下降等方法搜索解空间有很大的影响。特别地,我们证明了该网络能够抵抗"坏"解,并且更快速地下降到自然看起来的图像。这样做的结果是,最小化式( 2 )要么导致一个好看的局部最优,要么至少使优化轨迹通过一个附近。
为了定量地研究这种影响,我们考虑最基本的重建问题:给定一幅目标图像x0,我们希望找到再现该图像的参数θ *的值。这可以设置为( 2 )的优化,使用一个数据项将生成的图像与x0进行比较:
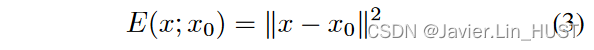
将其代入式( 2 )中引出最优化问题
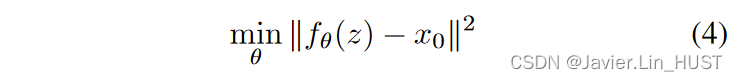
图2为图像x0的4种不同选择下能量E( x ; x0)随梯度下降迭代次数的变化情况:1 )一幅自然图像;2 )同一幅图像加上加性噪声;3 )随机置换像素后的同一幅图像;4 )白噪声。从图中可以看出,对于case1 )和case2 ),优化速度更快,而对于case3 )和case4 ),参数化表现出明显的"惯性"。
因此,尽管在极限情况下参数化可以拟合非结构化噪声,但它却非常不情愿。也就是说,参数化提供了对噪声的高阻抗和对信号的低阻抗。因此对于大多数应用,我们将优化过程( 2 )中的迭代次数限制在一定的迭代次数内。然后得到的先验对应于投影到一个简化的图像集合上,该图像集合可以由卷积神经网络从z生成,参数θ与随机初始化θ 0的距离不太远。

图5:4x图像超分辨率。与双三次上采样类似,我们的方法从来没有访问过除单个低分辨率图像以外的任何数据,但它产生了更干净的结果,边缘清晰,接近于使用从大型数据集训练的网络的最新超分辨率方法( LapSRN 、SRResNet )。

图6:区域修复。在很多情况下,深度图像先验足以成功修复大区域。尽管没有使用学习,结果可能与[ 15 ]相当。超参数的选择是很重要的( (如( d ))显示出对学习率的敏感性),但对于我们尝试的大多数图像,一个好的设置效果很好。
3、应用
我们现在通过实验展示所提出的先验对于不同的图像重建问题是如何工作的。由于篇幅限制,我们给出了一些例子和数字,并在补充材料和项目网页中包含了更多的例子和数字[ 30 ]。
去噪和通用重建。由于我们的参数化对图像噪声具有高阻抗性,因此可以自然地用于从图像中滤除噪声。去噪的目的是从含噪的观测值x0中恢复出干净的图像x。有时退化模型已知:x0 = x + ǫ,其中ǫ服从特定分布。然而,在盲去噪中更多时候噪声模型是未知的。
这里我们工作在盲假设下,但该方法可以很容易地修改以纳入有关噪声模型的信息。我们使用与相同的精确公式( 3 )和( 4 )以及,给定一个噪声图像x0,在替换公式(4)的最小值θ *后,恢复一个干净的图像x * = fθ * ( z ) .
我们的方法不需要为它需要还原的图像退化过程建立模型。这使得它可以以"即插即用"的方式应用于图像复原任务,其中退化过程是复杂和/或未知的,并且在监督训练中获得真实数据是困难的。我们通过图4和补充材料中的几个定性例子来证明这种能力,其中我们的方法使用导致公式( 4 )的二次能量( 3 )来恢复被复杂和未知压缩伪影退化的图像。图3 (上排)也展示了该方法在自然图像(这种情况下的卡通)之外的适用性。
我们在标准数据集1上评估了我们的去噪方法,该数据集由9幅噪声强度为σ = 25的彩色图像组成。经过1800步优化,PSNR达到29.22。如果对最后一次迭代得到的复原图像(使用指数滑动窗口)进行额外的平均,分数提高到30.43。如果平均两次优化运行,我们的方法进一步提高了31.00 PSNR。作为参考,不需要预训练的两个流行方法CMB3D [ 6 ]和Non - local means [ 4 ]的得分分别为31.42和30.26。

图7:与最近两种修复方法的比较。在文本修复实例上与谢泼德网络[ 27 ]进行顶端比较。底层-与卷积稀疏编码[ 25 ]在修复50 %的缺失像素上进行比较。在这两种情况下,我们的方法在各自论文中使用的图像上表现更好。

表1:本文方法与文献[ 25 ]算法的比较。见图7底排进行可视化对比。
超分辨率 超分辨率的目标是取一幅低分辨率( LR )图像x0∈R3 × H × W和上采样因子t,生成对应的高分辨率( HR )版本x∈R3 × tH × tW。为求解该反问题,令式( 2 )中的数据项为:
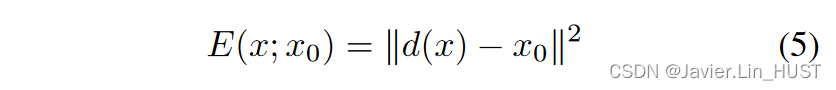
其中d ( · ):R3 × tH × tW→R3 × H × W是一个下采样算子,它将图像大小调整一个因子t。因此,问题是找到降采样后与LR图像x0相同的HR图像x。超分辨率是一个不适定问题,因为有无穷多的高分辨率图像x可以归结为同一个低分辨率图像x0(即算子d远离满射)。为了在式( 5 )的无穷多个极小值中选择最合理的极小值,需要进行正则化。

图8:使用不同深度和架构的修复。从图中可以看出,使用更深的随机网络可以获得更好的修复结果。然而,在U - Net的ResNet中添加跳跃连接是非常有害的。
遵循eq . ( 2 ),我们通过考虑重新参数化x = fθ ( z )和优化得到的能量w . r . t . θ来正则化问题.优化仍然使用梯度下降,利用神经网络和最常见的下采样算子,如Lanczos算法,都是可微的。
我们使用Set5 [ 2 ]和Set14 [ 32 ]数据集评估了我们方法的超分辨率能力。我们使用4的缩放因子与其他工作进行比较,并在补充材料中展示了缩放因子为8的结果。我们将每幅图像的优化步数固定为2000步。

图9:Alexnet反演。给定左边的图像,我们展示了使用3种不同的正则化器对AlexNet (在ImageNet ISLVRC上进行分类训练)的不同层进行反演得到的自然原图像:Deep Image先验、[ 21 ]的TV范数先验以及在拒识集上训练反演表示的网络[ 8 ]。使用深度图像先验得到的重建结果在很多方面至少和[ 8 ]一样自然,但是它们不受学习过程的影响。
与双三次上采样和先进的基于学习的方法SRResNet [ 19 ],LapSRN [ 29 ]的定性比较见图5。我们的方法可以与双三次方法进行比较,因为这两种方法都没有使用除给定的低分辨率图像之外的其他数据。在视觉上,我们接近使用MSE损失的基于学习的方法的质量。基于GAN的[ 11 ]方法SRGAN [ 19 ]和EnhanceNet [ 28 ] (在比较中没有显示出来)智能地幻想图像的精细细节,这是我们的方法无法使用绝对没有关于HR图像世界的信息的。

图10:基于闪光和无闪光图像对的重建。深度图像先验允许在照明非常接近无闪烁图像的情况下获得低噪声重建。与联合双边滤波[ 26 ] ( c.f.蓝色镶嵌)相比,它更成功地避免了闪光对的照明模式的"泄漏"。
我们使用生成图像的中心作物计算PSNR。我们的方法在Set5和Set14数据集上分别取得了29.90和27.00的PSNR。双三次上采样的得分较低,为28.43和26.05,而SRResNet的PSNR为32.10和28.53。虽然我们的方法仍然优于基于学习的方法,但它远远优于双三次上采样。在视觉上,它似乎弥合了双立方和最先进的训练卷积神经网络( c.f.图1、图5及附图)之间的大部分差距。
修复。在图像修复中,给定一幅二值掩模m∈{ 0,1 } H × W对应的像素缺失图像x0;目标是对缺失数据进行重构。相应的数据项为
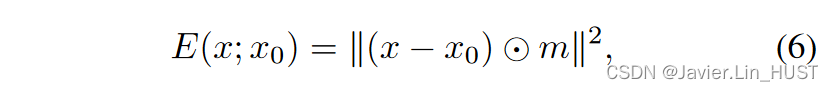
式中⊙为哈达玛积。数据先验的必要性是显而易见的,因为这种能量与缺失像素的值无关,因此,如果目标直接在像素值x上优化,则初始化后不会改变。与前面一样,通过优化数据项w . r . t .重新参数化( 2 )引入先验。
在第一个例子中,(图7 ,上排)修复用于去除图像上叠加的文本。我们的方法与[ 27 ]中专门为修复设计的方法进行了比较。我们的方法在几乎没有伪影的情况下得到了几乎完美的结果,而对于[ 27 ],文本掩码在某些区域仍然可见。
接下来,图7 (底部)考虑了根据二进制伯努利分布随机采样的掩膜进行修复。首先,采样一个掩模,随机丢弃50 %的像素。我们将我们的方法与文献[ 25 ]中基于卷积稀疏编码的方法进行了比较。为了得到[ 25 ]的结果,我们首先将损坏的图像x0分解成与[ 12 ]类似的低频和高频部分,并在高频部分运行他们的方法。为了公平的比较,我们使用他们的方法的版本,其中字典是使用输入图像(在[ 25 ]中显示出更好的性能)建立的。我们的方法在标准数据集[ 14 ]上的定量比较在表1中给出,显示了所提出的方法相比于卷积稀疏编码的强大定量优势。在图7 (下)中,我们给出了与[ 25 ]有代表性的定性视觉比较.
我们还将我们的方法应用到大孔洞的修复中。由于我们的方法是不可训练的,因此对于"高语义"的大洞修复(例如,人脸修复),我们的方法不能正常工作。然而,令人惊讶的是,它对其他情况的效果很好。我们在图6中与[ 15 ]中的基于学习的方法进行了比较。深度图像先验利用图像的上下文信息,利用已知部分的纹理对未知区域进行插值。这种行为突出了深度图像先验与传统自相似先验之间的关系。
在图8中,我们比较了几种结构对应的深度先验。我们在这里的发现(以及其他类似的比较)似乎表明,拥有更深层次的架构是有益的,而对于识别任务(如语义分割等)如此有效的跳跃连接是非常有害的。
自然原像。自然原像方法[ 21 ]是一种诊断工具,用于研究在自然图像上操作的有损函数(如深度网络)的不变性。令Φ为训练好的神经网络的前几层,即图像分类。原像是产生相同表示Φ ( x0 )的图像集合Φ - 1 ( Φ ( x0 ) ) = { x∈X:Φ ( x ) = Φ ( x0 ) }。观察这个集合,可以发现网络丢失了哪些信息,获得了哪些不变性。
寻找原像点可以表示为最小化数据项E( x ; x0) =‖Φ ( x ) - Φ ( x0 )‖2。然而,直接优化这个函数可能会发现"伪影",即网络Φ的行为原则上是不确定的,因此可以任意驱动它的非自然图像。文献[ 21 ]将原图像限制为一组自然图像X,称为自然原图像,可以得到更有意义的可视化。
在实践中,在自然原像中寻找点可以通过规则化数据项来完成,类似于上面看到的其他逆问题。文献[ 21 ]的作者更倾向于使用TV范数,这是一种弱自然图像先验,但相对无偏。相反,像[ 8 ]这样的论文从实例中学习反演神经网络,从而得到更好的外观重建,然而这可能偏向于学习数据驱动的反演先验。在这里,我们提出使用深度图像先验( 2 )代替。由于这是像TV准则一样手工制作的,所以它并不偏向于特定的训练集。另一方面,它导致的反演至少与[ 8 ]的反演一样具有可解释性。
为了评估,我们的方法与[ 22 ]和[ 8 ]的方法进行了比较。图9所示为考虑AlexNet [ 17 ]的逐步深入子集得到的反演表示Φ的结果:conv1,conv2,..,conv5,fc6,fc7,fc8。利用结构化先验对式( 2 )进行优化,得到原图像。
如图9所示,与简单的TV准则相比,我们的方法显著提高了图像清晰度。对于fc6和fc7这样的更深层,这种差异尤为显著,因为在这些层中,TV规范仍然会产生嘈杂的图像,而结构化正则化器产生的图像通常仍然是可解释的。我们的方法也产生了比[ 8 ]的先验知识更多的信息反演,它们有明显的回归到均值的趋势。
闪光-无闪光重建。在这项工作中,我们专注于单幅图像的恢复,所提出的方法可以扩展到多幅图像的恢复任务,例如视频恢复任务。因此,我们总结了一组应用实例,并用一个定性的例子说明了如何应用该方法来进行基于成对图像的恢复。特别地,我们考虑闪光-无闪光图像的双线性配对恢复[ 26 ],其中的目标是获得与无闪光图像光照相似的场景图像,同时使用闪光图像作为引导来降低噪声水平。
一般而言,将该方法扩展到多幅图像可能会涉及对输入编码z的一些协调优化,而在我们的方法中,对于单幅图像任务,通常保持固定和随机。在flashno - flash恢复的情况下,我们发现当使用flash图像作为输入(代替随机向量z)时,使用去噪公式( 4 )得到了很好的恢复。由此得到的方法可以看作是引导图像滤波的非线性推广[ 13 ]。复原结果如图10所示。
4、相关工作
我们的方法显然与基于可学习的卷积神经网络和上述参考的图像恢复和合成方法有关。同时,这也与一组备选的修复方法有关,这些方法避免了对抵制集的训练。该组包括基于腐败图像[ 4、6、10]内部相似块组联合建模的方法,这些方法在腐败过程复杂且(例如,空间变化的模糊)高度可变的情况下尤为有用。此外,在这组方法中,基于拟合字典的方法对损坏的图像块[ 23、32 ]以及基于卷积稀疏编码的方法[ 31 ],也可以拟合类似于浅层卷积神经网络的统计模型到重建图像[ 25 ]。工作[ 20 ]研究了将ConvNet与基于自相似性的去噪相结合的模型,因此也桥接了两组方法,但仍然需要在保持集上进行训练。
总体而言,本文研究的深度卷积神经网络所施加的先验似乎与基于自相似性和基于字典的先验高度相关。事实上,由于卷积滤波器的权重在图像的整个空间范围内共享,这确保了生成式ConvNet可能产生的单个图像块的自相似性。卷积神经网络和卷积稀疏编码之间的联系更加深入,在[ 24 ]中研究了识别网络,最近在[ 25 ]中提出了单层卷积稀疏编码用于重建任务。然而,我们的方法与[ 25 ] (图7和表1)的比较表明,使用现代基于深度学习的应用程序中流行的深度ConvNet架构
5、讨论
我们研究了最近的图像生成器神经网络的成功,将结构的选择所施加的先验的贡献与通过学习从外部图像传输的信息的贡献区分开来。作为一个副产品,我们已经表明,将随机初始化的ConvNet安装到损坏的图像中,可以作为修复问题的"瑞士刀"。虽然(每幅图像需要几分钟的GPU计算时间)实际上很慢,但这种方法不需要对退化过程建模或预训练。
我们的结果与将深度学习在图像复原中的成功解释为学习能力而不是手工先验的共同叙述相悖;相反,随机网络是更好的手工制作的先例,学习建立在这个基础上。这也验证了开发新的深度学习架构的重要性。


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









