






讲解的十分好的transformer的链接
【Transformer】10分钟学会Transformer | Pytorch代码讲解 | 代码可运行 - 知乎
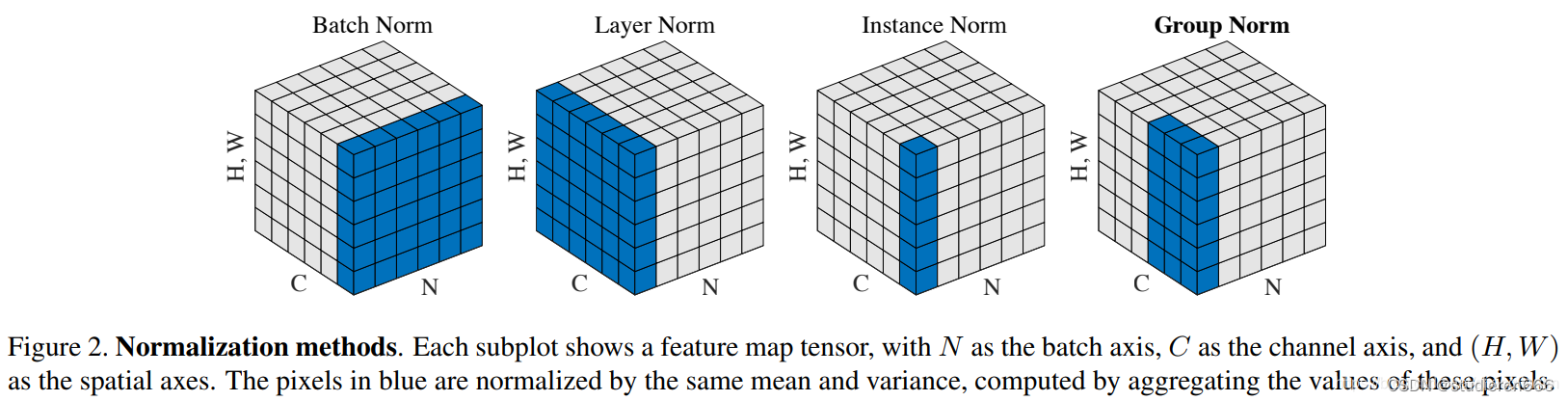
一 归一化 BatchNorm LayerNorm InstanceNorm GroupNorm
1.nn.LayerNorm(d_model)
在channel方向上做归一化,计算C H W的平均值,主要对RNN效果明显.
import torch.nn as nn
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
# normalized_shape: 输入尺寸,我理解为channel的大小
# [∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
# eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
normalized_shape
如果传入整数,比如4,则被看做只有一个整数的list,此时LayerNorm会对输入的最后一维进行归一化,
这个int值需要和输入的最后一维一样大。
假设此时输入的数据维度是[3, 4],则对3个长度为4的向量求均值方差,得到3个均值和3个方差,
分别对这3行进行归一化(每一行的4个数字都是均值为0,方差为1);LayerNorm中的weight和bias也
分别包含4个数字,重复使用3次,对每一行进行仿射变换(仿射变换即乘以weight中对应的数字后,然
后加bias中对应的数字),并会在反向传播时得到学习。
如果输入的是个list或者torch.Size,比如[3, 4]或torch.Size([3, 4]),则会对网络最后的两维进行
归一化,且要求输入数据的最后两维尺寸也是[3, 4]。
假设此时输入的数据维度也是[3, 4],首先对这12个数字求均值和方差,然后归一化这个12个数字;
weight和bias也分别包含12个数字,分别对12个归一化后的数字进行仿射变换(仿射变换即乘以weight
中对应的数字后,然后加bias中对应的数字),并会在反向传播时得到学习。
假设此时输入的数据维度是[N, 3, 4],则对着N个[3,4]做和上述一样的操作,只是此时做仿射变换时,
weight和bias被重复用了N次。
假设此时输入的数据维度是[N, T, 3, 4],也是一样的,维度可以更多。
注意:显然LayerNorm中weight和bias的shape就是传入的normalized_shape。
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
# Activate module
layer_norm(embedding)
# Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
# as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
2.nn.BatchNorm() batchnorm不改变输入输出的shape 即 输入的shape=输出的shape
batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
1d:num_features: 来自期望输入的特征数,C from an expected input of size (N,C,L) or L from input of size (N,L)
2d:num_features: 来自期望输入的特征数,C from an expected input of size (N,C,H,W)
# eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# momentum: 动态均值和动态方差所使用的动量。默认为0.1。
# affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
# track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
3.nn.InstanceNorm()
一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
num_features: 1d 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
2d:num_features-C 来自大小为 (N,C,H,W) 的预期输入
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
4.nn.GroupNorm()
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
num_groups:需要划分为的groups
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
二 reshape 和 view
简单来说reshape可以包含view的功能,可以无脑用reshape
torch的view()与reshape()方法都可以用来重塑tensor的shape,区别就是使用的条件不一样。
简单来说view()使用于满足连续性条件的tensor,是浅拷贝,不会额外开辟内存.
当使用reshape时,当满足连续性条件时,跟view一样,不满足连续性条件时才会开辟新的内存进行深拷贝.
三 torch.ge()、torch.gt()、torch.le()、torch.lt()
1.torch.ge()
torch.ge(input,other,out=None)
逐元素比较input和other,即是否 \( input >= other \)。
如果两个张量有相同的形状和元素值,则返回True ,否则 False。 第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
>>> torch.ge(torch.Tensor([[1, 2], [3, 4]]), torch.Tensor([[1, 1], [4, 4]]))
1 1
0 1
[torch.ByteTensor of size 2x2]
2.torch.gt()
torch.gt(input, other, out=None) → Tensor
逐元素比较input和other , 即是否\( input > other \) 如果两个张量有相同的形状和元素值,则返回True ,否则 False。 第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
>>> torch.gt(torch.Tensor([[1, 2], [3, 4]]), torch.Tensor([[1, 1], [4, 4]]))
0 1
0 0
[torch.ByteTensor of size 2x2]
3.torch.le()
torch.lt(input, other, out=None) → Tensor
逐元素比较input和other , 即是否input<=other
第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
>>> torch.le(torch.Tensor([[1, 2], [3, 4]]), torch.Tensor([[1, 1], [4, 4]]))
1 0
1 1
[torch.ByteTensor of size 2x2]4.torch.lt()
torch.lt(input, other, out=None) → Tensor
逐元素比较input和other , 即是否 input<other
,第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
>>> torch.lt(torch.Tensor([[1, 2], [3, 4]]), torch.Tensor([[1, 1], [4, 4]]))
0 0
1 0
[torch.ByteTensor of size 2x2]四 nn.Dropout()
Dropout字面意思就是“丢掉”,是为了防止神经网络出现过拟合,让隐藏层的节点在每次迭代时(包括正向和反向传播)有一定几率(keep-prob)失效。以提高模型的泛化能力,减少过拟合。
Dropout属于一种正则化技术。Dropout的probability,实践中最常用的是0.5(或0.1,0.05)
Dropout不能用于测试集,只能用于训练集!!!
推荐使用 nn.Dropout。因为一般只有训练时才使用 Dropout,在验证或测试时不需要使用 Dropout。使用 nn.Dropout时,如果调用 model.eval() ,模型的 Dropout 层都会关闭;但如果使用 nn.functional.dropout,在调用 model.eval() 时,不会关闭 Dropout。
下面是一个官方文档给出的例子:
import torch
import torch.nn as nn
m = nn.Dropout(p=0.2)
input = torch.randn(20, 16)
output = m(input)
print(input[0])
print(output[0])
五 激活函数 Sigmoid relu softmax tanh
AI 内容分享(十八):秒懂AI-深度学习四种常用激活函数:Sigmoid、Tanh、ReLU和Softmax_softmax和relu-CSDN博客
激活函数增加神经网络的非线性,可以无线逼近各种函数,增加神经网络的表征能力

1.sigmoid函数是常用的非线性函数,他可以将值映射到不需要归一化的0-1之间,将预测值转化为概率分布,通常用来回归或者二分类,但是,当输入值非常大时,梯度可能会变得非常小,导致梯度消失的问题.
优化方案:使用Relu等其他激活函数,或者其变种leaky relu
利用深度学习框架提供的优化技巧,梯度裁剪\学习率调整等
2.Tanh函数

tanh可以将输入转到-1到1之间,是一个比sigmoid更陡峭的函数,可以加快收敛的速度,在输入值接近正负1时,梯度接近于0,会导致梯度消失的问题.
优化方案:使用relu或者leaky relu
使用残差连接
3.relu函数
relu函数是一种简单的非线性函数,relu函数被广泛应用在深度学习模型中,尤其是卷积神经网络中,主要优点是计算简单,能够有效解决梯度消失的问题,
优点:有效缓解梯度消失的问题,在激活值为正时,不会使其梯度变小,避免了梯度消失的问题
加速训练,由于其计算简单,可以显著加速模型的训练过程.
缺点:死亡神经元的问题,当输入值小于等于0时,relu的输出为0,导致该神经元失效.
不对称性,relu的输出范围是0,+无穷 ,而输入值为负数时,输出值为0,导致relu的输出不对称,限制了生成的多样性
优化方案:1.使用leaky relu,当输入小于等于0时,会输出一个比较小的斜率而非0,避免了死亡神经元的问题
2.使用 parametric relu,prelu的斜率不是固定的,可以根据数据进行学习优化
4.softmax
softmax主要是用于多分类问题中,可以将预测值转换为概率分布,它的主要特点是 每个输出值在0-1之间且和为1
缺点,会出现梯度消失或者梯度爆炸
优化措施:使用relu或者leaky relu prelu
使用深度学习框架的优化技巧,比如批归一化或者权重衰减
六 attention中的两种mask
1.padding mask
在网络的训练过程中同一个batch会包含有多个文本序列,而不同的序列长度并不一致。
因此在数据集的生成过程中,就需要将同一个batch中的序列Padding到相同的长度。
第一种mask是为了解决输入的句子长短不一的情况做的填充,将其attention置于0
用在Q matmul Kt以后,softmax之前
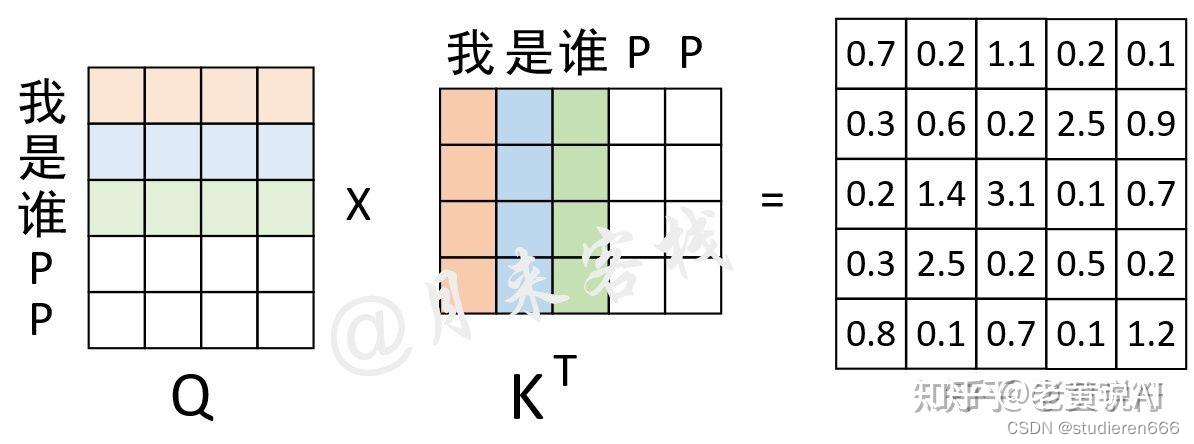
对于"我 是 谁 P P"这个序列来说,前3个字符是正常字符,后2个字符是Padding后的结果,是没有意义的。因此,其Mask向量便为[True, True, True, False, False]。
实现的方法,仅仅是训练数据的长度是已知的,因此padding的位置是已知的,所以就好实现了。
通过这个Mask向量可知,需要将权重矩阵的最后两列替换成负无穷。
和attention mask一样,padding mask的地方也是Q乘以K的转秩之后,softmax之前。

2.第二种是时序的mask
在真实预测时解码器需要将上一个时刻的输出作为下一个时刻解码的输入,然后一个时刻一个时刻的进行解码操作。
显然,如果训练时也采用同样的方法那将是十分费时的。
因此,在训练过程中,解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。
这样做的好处:一是通过多样本并行计算能够加快网络的训练速度;
二是在训练过程中直接喂入解码器正确的结果而不是上一时刻的预测值(因为训练时上一时刻的预测值可能是错误的)能够更好的训练网络。
例如在用平行预料"我 是 谁"<==>"who am i"对网络进行训练时,编码器的输入便是"我 是 谁",而解码器的输入则是"<s> who am i",对应的正确标签则是"who am i <e>"。
假设现在解码器的输入"<s> who am i"在分别乘上一个矩阵进行线性变换后得到了Q、K、V,且Q与K作用后得到了注意力权重矩阵(此时还未进行softmax操作)

此时已经计算得到了注意力权重矩阵。由第1行的权重向量可知,在解码第1个时刻时应该将
(严格来说应该是经过softmax后的值)的注意力放到"<s>"上,
的注意力放到"who"上等等。
不过此时有一个问题就是,模型在实际的预测过程中只是将当前时刻之前(包括当前时刻)的所有时刻作为输入来预测下一个时刻,也就是说模型在预测时是看不到当前时刻之后的信息。因此,Transformer中的Decoder通过加入注意力掩码机制来解决了这一问题。
通俗解释:
在训练阶段,模型是知道所有的输出是什么的。在预测阶段,模型是不知道下一个字的输出是什么,需要预测,并且需要将上一个字的预测结果,拿来输入模型,所以在真正的预测阶段,是没有mask的。只有在训练的时候,需要mask。
mask的方法是,其实Q、k矩阵都是完整计算出来的,为了完成后面信息不应该知道这个条件,所以做了attention mask。 mask的方法就是把Q乘以K转秩的结果,加上一个上三角矩阵全为负无穷,再经过softmax,就可以完成任务了。

看一看代码里如何具体实现的:
七 mask_fill_
主要用在transformer的attention机制中,在时序任务中,主要是用来mask掉当前时刻后面时刻的序列信息,此时的mask主要实现时序上的mask
>>>a=torch.tensor([1,0,2,3])
>>>a.masked_fill(mask = torch.ByteTensor([1,1,0,0]), value=torch.tensor(-1e9))
>>>a
>>>tensor([-1.0000e+09, -1.0000e+09, 2.0000e+00, 3.0000e+00])其中 mask必须是一个 ByteTensor ,shape必须和 a一样,且元素只能是 0或者1 ,是将 mask中为1的 元素所在的索引,在a中相同的的索引处替换为 value ,mask value必须同为tensor 。
八 unsqueeze squeeze expand repeat
pytorch中unsqueeze()、squeeze()、expand()、repeat()、view()、和cat()函数的总结_unsqueeze(2)-CSDN博客
1.unsqueeze 扩展维度,但该维度size为1
unsqueeze()的作用是用来增加给定tensor的维度的,unsqueeze(dim)就是在维度序号为dim的地方给tensor增加一维。例如:维度为torch.Size([768])的tensor要怎样才能变为torch.Size([1, 768, 1])呢?就可以用到unsqueeze(),直接上代码:
a=torch.randn(768)
print(a.shape) # torch.Size([768])
a=a.unsqueeze(0)
print(a.shape) #torch.Size([1, 768])
a = a.unsqueeze(2)
print(a.shape) #torch.Size([1, 768, 1])2. squeeze
squeeze()的作用就是压缩维度,直接把维度为1的维给去掉。形式上表现为,去掉一层[]括号。
同时,输出的张量与原张量共享内存,如果改变其中的一个,另一个也会改变。
a=torch.randn(2,1,768)
print(a)
print(a.shape) #torch.Size([2, 1, 768])
a=a.squeeze()
print(a)
print(a.shape) #torch.Size([2, 768])注意的是:squeeze()只能压缩维度为1的维;其他大小的维不起作用。
3.expand
这个函数的作用就是对指定的维度进行数值大小的改变。只能改变维大小为1的维,否则就会报错。不改变的维可以传入-1或者原来的数值。
a=torch.randn(1,1,3,768)
print(a)
print(a.shape) #torch.Size([1, 1, 3, 768])
b=a.expand(2,-1,-1,-1)
print(b)
print(b.shape) #torch.Size([2, 1, 3, 768])
c=a.expand(2,1,3,768)
print(c.shape) #torch.Size([2, 1, 3, 768])4.repeat
沿着指定的维度,对原来的tensor进行数据复制。这个函数和expand()还是有点区别的。expand()只能对维度为1的维进行扩大,而repeat()对所有的维度可以随意操作。
a=torch.randn(2,1,768)
print(a)
print(a.shape) #torch.Size([2, 1, 768])
b=a.repeat(1,2,1)
print(b)
print(b.shape) #torch.Size([2, 2, 768])
c=a.repeat(3,3,3)
print(c)
print(c.shape) #torch.Size([6, 3, 2304])总结:unsqueeze是扩维的,且size为1. squeeze则是只能对维度为1的进行缩维
expand只能改变维度为1的大小
repeat则可以改变任意维度大小,且expand和repeat括号里的size都是倍数.
九 fc linear ffn mlp的区别
神经网络Linear、FC、FFN、MLP、Dense Layer等区别是什么? - 知乎
fc=linear 称为全连接网络或者线性层或者密集层,没有激活函数
import torch
import torch.nn as nn
# 定义线性层
linear_layer = nn.Linear(in_features=10, out_features=5)
# 创建输入
input_data = torch.randn(1, 10) # 假设输入维度为10
# 应用线性变换
output = linear_layer(input_data)
print(output)。ffn 称为前馈神经网络,不止可以包含全链接网络,前向反馈的网络都可以
mlp 是由多个全连接网络和激活函数组成的
import torch
import torch.nn as nn
# 创建多层感知机模型
model = nn.Sequential(
nn.Linear(in_features=10, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=32),
nn.ReLU(),
nn.Linear(in_features=32, out_features=1),
nn.Sigmoid()
)
# 创建输入
input_data = torch.randn(1, 10) # 假设输入维度为10
# 前向传播
output = model(input_data)
print(output)















 2630
2630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









