









前言
老版本编写UDF时,需要继承 org.apache.hadoop.hive.ql.exec.UDF类,然后直接实现evaluate()方法即可。
由于公司hive版本比较高(3.x),这次编写UDF就采用了新的版本,继承类org.apache.hadoop.hive.ql.udf.generic.GenericUDF,实现三个方法
1. 新建项目
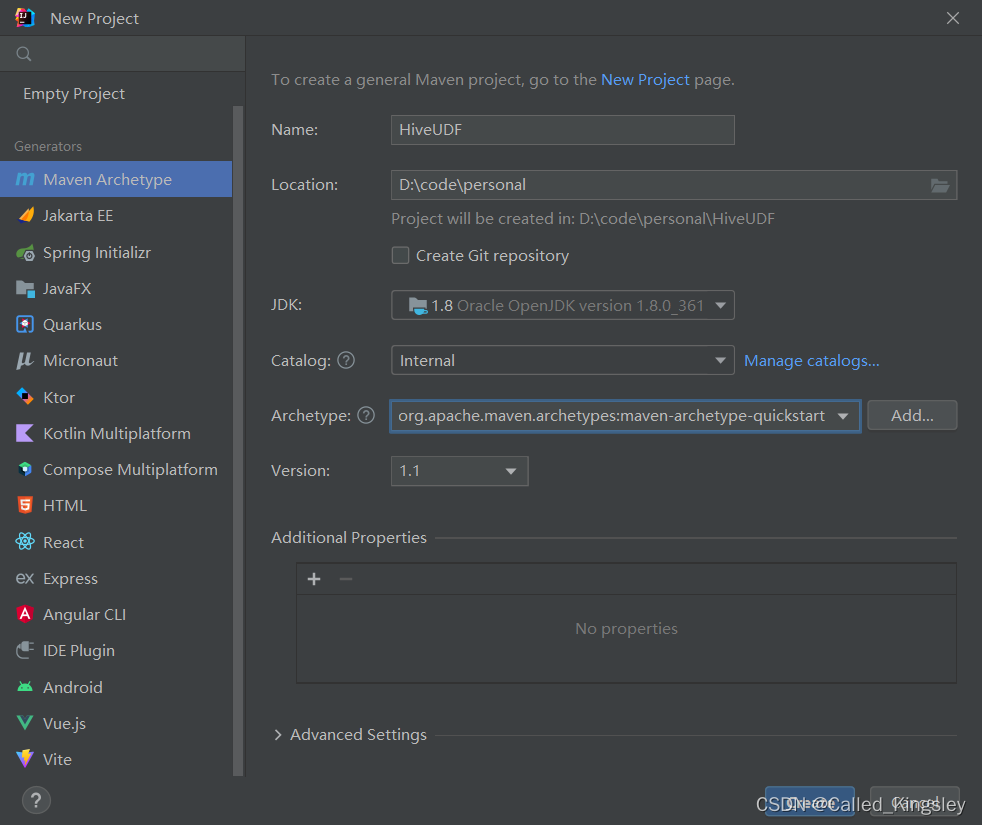
打开IDEA,新建一个项目,基本配置如下,Archetype选择图中所示
2.配置maven依赖
导入编写UDF需要用到的依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
</exclusion>
</exclusions>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
3.编写代码
目录结构可自行定义,这块不影响实际功能,代码整体框架如下
我这里代码传入三列数据,返回一列数据,入参可以判断一下是否传入数据正确,以及数据类型是否匹配
主要实现三个方法,具体内容在代码块中有说明
- initialize
- evaluate
- getDisplayString
public class ComputeUnitPrice extends GenericUDF {
WritableHiveDecimalObjectInspector decimalObjectInspector;
//初始化方法,做一些检查
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断输入参数的个数
if(arguments.length !=3){
throw new UDFArgumentLengthException("This UDF Only takes 3 arguments: String, String, Decimal");
}
ObjectInspector param1 = arguments[0];
ObjectInspector param2 = arguments[1];
ObjectInspector param3 = arguments[2];
// 判断输入参数的类型
if(!(param1 instanceof StringObjectInspector)){
throw new UDFArgumentException("Param1 Type is error,Must be : String");
}
if(!(param2 instanceof StringObjectInspector)){
throw new UDFArgumentException("Param2 Type is error,Must be : String");
}
// if(!(param3 instanceof JavaConstantHiveDecimalObjectInspector)){
// throw new UDFArgumentException("Param3 Type is error,Must be : JavaHiveDecimal");
// }
this.decimalObjectInspector = (WritableHiveDecimalObjectInspector ) param3;
//函数返回值为 Decimal,需要返回 Decimal类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaHiveDecimalObjectInspector;
}
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
//计算逻辑编写
}
//udf的说明
@Override
public String getDisplayString(String[] children) {
return "ComputeUnitPrice";
}
//main方法测试一下数据结果
public static void main(String[] args) throws HiveException {
ComputeUnitPrice computeUnitPrice = new ComputeUnitPrice();
DeferredObject[] param = {new DeferredJavaObject("箱"), new DeferredJavaObject("800g*8袋/箱"), new DeferredJavaObject(100.20)};
JavaDoubleObjectInspector javaDoubleObjectInspector = PrimitiveObjectInspectorFactory.javaDoubleObjectInspector;
ObjectInspector stringOi = PrimitiveObjectInspectorFactory.javaStringObjectInspector;
ObjectInspector doubleOi = PrimitiveObjectInspectorFactory.javaDoubleObjectInspector;
computeUnitPrice.initialize(new ObjectInspector[]{stringOi, stringOi,doubleOi});
double res = javaDoubleObjectInspector.get(computeUnitPrice.evaluate(param));
System.out.println("res " + res);
}
4.打jar包
将项目打成jar包
mvn clean package
执行完成,target目录下寻找自己的jar包
5.上传服务器
本地上传到机器,再由机器上传到hdfs或者s3等
6.代码中引用
add jars xxxxx/compute_sku_unit_price.jar;
create temporary function compute_sku_unit_price as 'xx.xxx.xxx.xxx.ComputeUnitPrice';
${your_sql};















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









