






题目:Scale-recurrent Network for Deep Image Deblurring(SRN)
题目:用于深度图像去模糊的尺度递归网络
Xin Tao
香港中文大学
2018CVPR
关键词句
想要由粗到精,逐步恢复不同分辨率图像。所以就需要多尺度
提出LSTM共享参数
摘要
在单图像去模糊中,由粗到精的方法,即在金字塔中逐步恢复不同分辨率的清晰图像,在传统的基于优化的方法和最近的基于神经网络的方法中都是非常成功的。
在这篇论文中,我们研究了这种策略,并提出了一个尺度递归网络(SRN-DeblurNet)来完成这种去模糊任务。与[25]中最近出现的许多基于学习的方法相比,它具有更简单的网络结构、更少的参数和更容易训练。我们在具有复杂运动的大规模去模糊数据集上评估了我们的方法。结果表明,该方法在定量和定性方面均优于现有方法。
1引言
图像去模糊一直是计算机视觉和图像处理中的一个重要课题。对于由相机抖动、物体运动或失焦引起的运动或焦模糊图像,去模糊的目标是用必要的边缘结构和细节来恢复清晰的潜在图像。
单一图像去模糊是高度不适定的。传统方法对模糊模型特征(均匀/非均匀/深度感知)应用各种约束条件,利用不同的自然图像先验[1,3,6,39,14,40,26,27]对解空间进行正则化。这些方法大多涉及启发式参数优化和昂贵的计算。此外,对模糊模型的简化假设常常阻碍了它们在真实世界示例中的性能,因为在真实世界示例中,模糊比建模的复杂得多,并且与摄像机内的图像处理管道纠缠在一起。
基于学习的方法也被提出用于去模糊。早期的方法[29,34,38]用利用外部数据已学习的参数替换传统框架中的一些模块或步骤。最近的研究开始使用端到端的可训练网络来去除图像、[25]和视频的模糊[18,33,37]。在他们中间,Nah etal.[25]使用多尺度卷积神经网络(CNN)取得了最先进的结果。该方法从模糊图像的一个非常粗糙的尺度开始,逐步恢复高分辨率的潜影,直到达到全分辨率。这个框架遵循了传统方法中的多尺度机制,在处理大型模糊内核[6]时,通常使用从粗到细的管道。
在本文中,我们探索了一种更有效的多尺度图像去模糊网络结构。我们提出了新的scale-recurrent网络(SRN),它解决了基于cnn的去模糊系统中的两个重要和普遍的问题。
Scale-recurrent结构 在成熟的多尺度方法中,求解器和各尺度对应的参数通常是相同的。这在直觉上是一个自然的选择,因为在每个量表中,我们的目标都是解决相同的问题。研究还发现,各尺度上参数的变化会引入不稳定性,导致非限制性解空间的附加问题。另一个问题是,输入的图像可能有不同的分辨率和运动尺度。如果允许在每个比例中调整参数,解决方法可能对特定的图像分辨率或运动尺度过度拟合。
基于同样的原因,我们认为这个方案也应该适用于基于cnn的方法。然而,最近的级联网络[4,25]仍然对每个尺度使用独立的参数。**在这项工作中,我们建议跨尺度共享网络权值,以显著降低训练难度,**并引入明显的稳定性好处。
这有两个好处。首先,它显著减少了可训练参数的数量 。即使使用相同的训练数据,重复使用共享权值的工作方式也类似于多次使用数据来学习参数,这实际上相当于规模上的数据扩充。其次,我们提出的结构可以包含递归模块,其中隐藏状态捕获有用的信息,并有利于跨尺度的恢复。
Encoder-decoder ResBlock网络 受最近成功的用于各种计算机视觉任务的编码器-解码器结构的启发[23,33,35,41],我们探索了将其应用于图像去模糊的有效方法。在本文中,我们证明直接应用现有的编解码器结构并不能产生最佳的结果。我们Encoder-decoder ResBlock network则有用,它放大了各种CNN结构的优点,并在训练中产生了可行性。它还产生一个非常大的接受域,这对大的运动去模糊至关重要。
我们的实验表明,利用这种循环结构,结合上述优点,我们的端到端深度图像去模糊框架可以大大提高训练效率(训练时间约为[25]的1/4),实现类似的恢复。我们只使用不到1/3的可训练参数,测试时间也快得多。除了训练效率外,我们的方法也可以产生比现有方法更高质量的结果,无论是在数量上还是在质量上,如图1所示,后面会详细介绍。我们将这个框架命名为scale-recurrent网络(SRN)。
2相关工作
在这一节中,我们将简要回顾图像去模糊方法和最近用于图像处理的CNN结构。
图像/视频去模糊 在Fergus等人[12]和Shan等人[30]的开创性工作之后,提出了许多恢复质量和适应不同情况的去模糊方法。自然图像先验是为了抑制人为因素和提高图像质量而设计的。其中包括全变差(TV)[3]、稀疏图像先验[22],重尾梯度先验[30],超拉普拉斯先验
[21],[40]之前的l0-norm梯度,等等。这些传统方法大多遵循由粗到细的框架。例外包括频域方法[8,14],仅适用于有限的情况。
图像去模糊也得益于最近深度CNN的发展。Sun等人使用该网络来预测模糊方向和宽度。Schuler等人以由粗到细的方式将多个cnn堆叠起来,以模拟迭代优化。Chakrabarti[2]预测频域反褶积核。这些方法遵循传统框架,由CNN模块替换了几个部分。Su等人使用带有跳连接的编码器-解码器网络来学习视频去模糊。Nah等人训练了一个多尺度的深度网络来逐步恢复清晰的图像。这些端到端方法通过不同的结构利用多尺度信息。
用于图像处理的CNN

与分类任务不同,图像处理网络需要特殊的设计。作为最早的方法之一,SRCNN【9】使用了3个用于超分辨率的平坦卷积层(具有相同的特征图大小)。改进后的U-net【28】(如图2(a)所示),又称编解码器网络【24],大大提高了回归能力,在FlowNet【10]、视频去模糊【33]、视频超分辨率【35]、帧合成【23]等最新工作中得到了广泛应用。多尺度CNN【25]和级联细化网络(CRN)【4](图2(b))简化训练,从非常小的尺度开始逐步细化输出。它们分别在图像去模糊和图像合成方面取得了成功。图2©显示了一个不同的结构[5],它使用了随速率增加而膨胀的卷积层,这近似于增加内核大小。
3网络结构
该网络的总体架构,我们称之为SRN-DeblurNet,如图3所示。它将输入图像中不同尺度下采样的模糊图像序列作为输入 ,生成一组对应的锐化图像。在全分辨率下最清晰的是最终的输出。

3.1Scale-recurrent Network (SRN)
正如第1节所解释的,我们在从粗到细的策略中采用了跨多个尺度的新的递归结构。我们将每个尺度上的锐化潜影的生成作为图像去模糊任务的子问题,将一个模糊的图像和一个初始去模糊结果(前一个尺度上的上采样)作为输入,并将此尺度下的锐化图像估计为
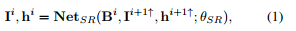
其中i为scale index, i = 1表示最细的scale。Bi和Ii分别是第i个尺度上的模糊图像和估计的潜像。
N
e
t
S
R
Net_{SR}
NetSR是我们提出scale-recurrent网络,带有
θ
S
R
θ_{SR}
θSR训练参数表示。由于网络是递归的,所以隐状态具有跨尺度流动的特点。隐藏状态从先前的粗尺度捕获图像结构和内核信息。(·)是将(i + 1)-th的特征或图像调整到i-th的算子。(h是核,I是清晰图,B是模糊图)
式(1)给出了网络的详细定义。在实践中,网络设计具有极大的灵活性。
1 首先,递归网络可以采用不同的形式,如普通RNN、长短时记忆(long-short term memory, LSTM)[16, 32]和门控递归单元(gate unit, GRU)[7]。 我们选择ConvLSTM[32],因为它在我们的实验中表现得更好。分析将在第4节中给出。
2 其次,算子(·)(上采样算子)的可能选择包括反卷积层、亚像素卷积层[31]和图像大小调整。我们在所有我们的实验中,使用双线性插值的,因为它的充分性和简单性。
3 第三,需要对每个尺度的网络进行合理的设计,以获得最佳的恢复效果。我们的方法具体如下。
3.2Encoder-decoder with ResBlocks
Encoder-decoder Network
编码器-解码器网络[24,28]是指先将输入数据逐步转换成空间尺寸更小、通道更多的特征图(在编码器中),然后再将其转换回输入形状(在解码器中)的对称CNN结构。 对应maps之间的跳跃连接(Skip-connections)被广泛用于组合不同levels的信息。它们也有利于梯度传播和加速收敛。通常,编码器包含多个阶跃带步长的卷积层,解码器模块使用一系列反卷积层[23、33、35]或调整大小来实现。在每一level之后插入额外的卷积层以进一步增加深度。
编码-解码器结构已被证明在许多视觉任务中是有效的[23,33,35,41]。但是,考虑到以下几点,直接使用编解码器网络并不是我们任务的最佳选择。
首先,对于去模糊的任务,接受域需要很大来处理严重的运动,导致编码器/解码器模块的层次更多。但是,这种策略在实践中并不推荐,因为它使用大量的中间特征通道快速地增加了参数的数量。
此外,中间特征map的空间尺寸太小,无法保留空间信息进行重建。其次,在编码器/解码器模块的每一层添加更多的卷积层会使网络收敛速度变慢(在每一层添加平坦卷积)。最后,我们提出的结构需要包含隐藏状态的递归模组。
Encoder/decoder ResBlock
我们做了一些修改,以适应编码器-解码器网络到我们的框架。首先,我们通过引入residual学习块【15]来改进编码器/解码器模块。根据【25]的结果和我们的实验,我们选择在ResNet【15]中使用ResBlocks而不是原始的ResNet【15](不进行批量归一化)。如图3所示,我们提出的编码器重块(EBlocks)包含一个卷积层和多个resblock。卷积层的步长为2。它将前一层的内核数量增加一倍,并将特征映射采样到一半大小。下面的每个块包含2个卷积层。此外,所有的卷积层具有相同数量的内核。解码器ResBlock (DBlocks)与EBlock是对称的。它包含几个重块,然后是一个反卷积层。反卷积层用于将map的空间尺寸增加一倍,并将通道减半。
第二,我们的scale-recurrent结构需要网络内部的递归单元。类似于[35]的策略,我们在瓶颈(bottleneck layer)层中插入卷积层,以隐藏状态连接连续的尺度。???最后,我们对每个卷积层使用大小为5×5的大卷积核。
修正后的网络表示为
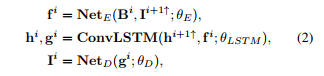

θLSTM ConvLSTM参数的设置。隐藏状态hi可能包含关于中间结果和模糊模式的有用信息,这些信息将被传递到下一个尺度,从而有利于解决精细尺度问题。
模型参数的详细信息在这里指定。我们的SRN包含3个scales。第(i + 1)-th刻度是第i个刻度的一半大小。对于编码器/解码器resblock,有1个InBlock, 2个eblock,1个Convolutional LSTM block, 2个DBlocks和1个OutBlock,如图3所示。InBlock生成一个32通道的特性映射。OutBlock以之前的feature map作为输入,生成输出图像。每个EBlock/DBlock中所有卷积层的内核数是相同的。对于eblock,内核的数量分别为64和128。对于DBlocks,它们是128和64。EBlocks和反卷积层中卷积层的步长为2,其余均为1。所有层都使用整流线性单元(ReLU)作为激活函数,所有内核大小都设置为5。
3.3 损失
我们对于每一个scale,使用欧几里德损失,之间的网络输出和地面真相(使用双线性插值,下采样到相同的大小):
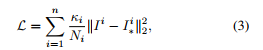
其中,Ii和Ii*分别是我们在第i个尺度下的网络输出和地面真值。{κi}是每个scale的权重。我们根据经验设置κi = 1.0。Ni是Ii中要归一化的元素数量。我们还尝试了完全variation和对抗损失。但是我们注意到L2-norm足够好,可以产生清晰的结果。
4 实验
我们的实验是在带有ntel XeonE5 CPU和NVIDIA Titan X GPU的PC机上进行的 。我们在TensorFlow平台[11]上实现了我们的框架。我们的评估是全面的,以验证不同的网络结构,以及各种网络参数。为公平起见,除非另有说明,所有实验都在具有相同训练配置的相同数据集上进行。
数据准备
为了创建一个大的训练数据集,早期基于学习的方法[2,29,34]通过将锐化图像与真实的或生成的均匀/非均匀模糊内核进行卷积来合成模糊图像。由于简化的图像形成模型,合成的数据仍然不同于相机捕获的数据。最近,研究人员[25,33]提出,通过对高速相机(如GoPro Hero 4 Black)拍摄的视频进行连续短曝光帧平均,生成模糊图像,以近似长曝光的模糊帧。这些生成的帧更真实,因为它们可以模拟复杂的相机抖动和物体运动,这在真实的照片中很常见。
为了在网络结构方面进行公平的比较,我们使用了[25]的GOPRO数据集来训练我们的网络,它包含了3214个模糊/清晰的图像对 。按照与[25]相同的策略,我们使用2,103对进行训练,其余1,111对进行评估。
模型训练
模型训练中,我们使用亚当解算器Adam solver[19],参数设置是β1 = 0.9,β2 = 0.999和ǫ= 10 ^ -8。使用power0.3,学习速率在2000个epoch时从初始值0.0001指数衰减到1e6。根据我们的实验,2000个epoch就足够收敛,大约需要72小时。在每次迭代中,我们抽取一批16张模糊图像,随机裁剪256×256像素的patch作为训练输入。真值清晰patch相应产生。使用Xavier方法[13]初始化所有可训练变量。上述参数对于所有实验都是固定的。
对于涉及到递归模组的实验,我们只对ConvLSTM模组(被全局模3裁剪)的权重采用梯度剪辑(gradient clip)来稳定训练。由于我们的网络是全卷积的,只要GPU内存允许,任意大小的图像都可以作为输入输入。对于大小为720×1280的测试图像,我们的方法的运行时间约为1.87秒。
4.1多尺度策略
为了评估所提出的比例递归网络,我们设计了几个基准模型。为了评估网络结构,为了合理的效率,我们对所有卷积层使用核大小3。single-scale模型SS使用我们提出的相同的结构,除了在原始分辨率下只取一幅单尺度图像作为输入。将递归模块替换为一个卷积层,以保证相同数量的卷积层。
基准模型SC指的是[4,25]中的尺度级联(scale-cascaded)结构,它使用了独立网络的3个stage。每个single-stage与SS模型相同,因此该模型的可训练参数是我们方法的3倍。模型w/oR在瓶颈层(即模型SS)中不包含显式递归模块,这是模型SC的一个共享权版本。模型RNN采用普通的RNN结构,而不是ConvLSTM。
不同方法对测试数据集的结果如表1所示,从中我们得到了一些有用的观察结果。首先 ,多尺度策略对于图像去模糊任务是非常有效的。模型SS使用与我们提出的SRN结构相同的结构和相同数量的参数,但是在PSNR方面表现得更差(28.40dB vs.29.98dB)。如图4所示,其中(b)中的单尺度模型SS可以从严重模糊的图像中恢复结构。但这些汉字还不够清晰,无法识别。
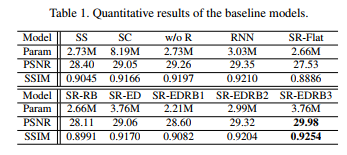
当我们使用如图4©所示的两种尺度时,结果得到了改善,因为多尺度信息得到了有效的合并。在图4(d)中,具有3个尺度的模型越完整,得到的结果越好;但进步已经很小了。

其次 ,每个尺度的独立参数是不必要的,甚至可能是有害的,事实证明,模型SC的性能比模型w/oR、RNN和SR-EDRB3(具有相同的编码器-解码器resblock结构,带有3个resblock)差。我们认为原因是,虽然更多的参数导致更大的模型,它也需要更长的训练时间和更大的训练数据集。在我们使用固定数据集和训练周期的约束设置中,模型SC可能没有得到最佳训练。
最后 ,我们还测试了不同的递归模块。结果表明,使用RNN比不使用RNN有更好的效果,而使用SREDRB3模型的最优结果为ConvLSTM。
4.2 编解码resblock network
我们还设计了一系列的基准模型来评估具有resblock结构的编译码器的有效性。为了进行公平的比较,这里的所有模型都使用了我们的scale-recurrent(SR)框架。模型SR-Flat用平坦的卷积层代替了编码器-解码器结构,卷积层的数量与提出的网络相同,即43层。模型SR-RB用ResBlock替换所有EBlocks和DBlocks。不包括stride或pooling。这使得feature map具有相同的大小。模型SR-ED采用原有的编码器-解码器结构,所有resblock替换为2个卷积层。我们还比较了EBlock/DBlock中不同数量的resblock。模型SR-EDRB1、SR-EDRB2、SR-EDRB3分别指使用1、2、3个resblock的模型。
定量结果如表1所示。平坦卷积模型在PSNR和SSIM方面表现最差。在我们的实验中,要达到与其他结果相同的质量水平,需要的时间要长得多。模型RB要好得多,因为ResBlock结构是为更好的训练而设计的。我们提出的模型SR-EDRB1-3取得了最好的结果。定量结果也随着重块数量的增加而改善。在我们的模型中,我们选择了3个resblock,因为超过3个resblock的改进是有限的,并且在效率和性能之间取得了很好的平衡。
4.3比较
我们比较了我们的方法与以往的好的图像去模糊的方法,在评估数据集和实际图像方面的不同。由于我们的模型处理的是一般的相机抖动和物体运动(即动态去模糊[17]) ,因此与传统的均匀去模糊方法进行比较是不公平的。选取Whyte等人的方法[36]作为非均匀模糊的代表传统方法。注意,在测试数据集中的大多数例子中,模糊图像仅仅是由相机抖动造成的。因此,[36]中的非均匀假设成立。
Kim等人的[17]方法应该能够处理动态模糊。但是没有提供代码或可执行文件。相反,我们将其与Nah等人最近的工作进行了比较,结果显示出了非常好的结果。Sun等人使用CNN估计模糊核,并使用传统的反褶积方法来恢复锐化图像。我们使用来自作者的带有默认参数的官方实现。GOPRO测试集和Kohler数据集[¨20]的定量结果如表2所示。目视比较见图5和图6。更多的结果包含在我们的补充资料中。



benchmark dataset 基准数据集
图5的第一行包含来自GOPPRO测试数据集的图像,这些数据集由于较大的相机和对象运动而产生复杂的模糊。虽然传统的[36]方法对相机平移和旋转建立了一般的非均匀模糊模型,但在相机运动为主的图5(a)、©和(d)中仍然不适用。这是因为在真实的模糊图像中,前向/后向运动以及场景深度起着重要的作用。此外,违反假定的模型会导致恼人的振铃现象,这使得恢复后的图像甚至比输入还要糟糕。
Sun等人使用CNN来预测内核方向。但是在这个数据集上,复杂的模糊模式与它们的合成训练集有很大的不同。因此,这种方法在大多数情况下都不能预测可靠的内核,结果也只是稍微有点锐化。目前最先进的方法[25]可以产生良好的质量的结果,与残留的一些模糊的结构和文物。由于我们设计的框架,我们的方法有效地产生了更清晰的结构和清晰的细节优越的结果。根据我们的实验,即使是在极端情况下,运动对于之前的解决方案来说太大,我们的方法仍然可以在重要的部分产生合理的结果,并且不会在其他区域产生太多的视觉伪影,如图6的最后一种情况所示。定量结果与我们的观察结果一致,我们的框架在很大程度上优于其他框架。
真实模糊图像
GoPro的测试图像是由高速相机合成的,这可能与实际的模糊输入仍然不同。我们将结果显示在图6所示的real capture模糊图像上。我们的训练模型对这些图像进行了很好的概括,如图6(d)所示。与Sun等人、Nah等人的结果相比,我们的结果是高质量的。
5结论
在本文中,我们解释了在图像去模糊中使用“由粗到精”方案的适当网络结构。我么还提出了scale-recurrent网络,和encoder-decoder resblocks结构,每种尺度下。这种新的网络结构比之前的多尺度去模糊网络参数更少,更容易训练。我们方法的结果是最好的,不管是质量还是数量。我们相信这种scale-recurrent网络能够应用到其他图像处理任务红,我们将会继续探索。















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









