









目录
1.PyTorch是什么
pytorch是由Facebook的AI团队研发的,以python优先的深度学习框架,在GPU加速基础上实现张量和动态神经网络,它的前身是torch。
pytorch的两种主要使用方式:
(1)使用GPU加速的tensor计算,用来代替numpy
(2)构建基于自动求导的神经网络,为后面构建复杂的神经网络提供强有力的手段
pytorch优点:
(1)以Python优先
(2)命令行式体验,这是基于它独特的动态图机制,所以在degub的时候很方便,能很快定位到bug位置
(3)快速轻巧
2.Tensor
2.1简介
tensor作为pytorch中最基本的构建,可以像numpy一样进行运算,同时支持gpu加速。
它的数据类型如下:

我们常用FloatTensor和LongTensor。
2.2操作
tensor的运算和numpy的运算非常相似,其中最重要的运算就是tensor的定义,和numpy.array的相互转换以及GPU和CPU的相互转换。
2.2.1定义tensor
import torch
x1=torch.Tensor([3,4])
x2=torch.FloatTensor([4,4])
x3=torch.randn(3,4)2.2.2pytorch和numpy的转换
import numpy as np
numpy_tensor=np.random.randn(10,20)
pytorch_tensor=torch.from_numpy(numpy_tensor)
new_numpy_tensor=pytorch_tensor.numpy()(3)CPU和GPU上相互转换
x=torch.randn(3,4)
x_gpu=x.cuda()
x_cpu=x_gpu.cpu()
x_array=x_gpu.cpu().numpy() #不能直接在gpu上调用 .numpy()这里因为pytorch里的tensor比numpy的数学运算要少,所以有时候会转成numpy。
2.2.3tensor 操作
tensor的操作分为两种,一种是数学运算,一种是torch的高级操作,对于数学运算,操作的方式和python程序中数学运算一致。
(1)数学运算
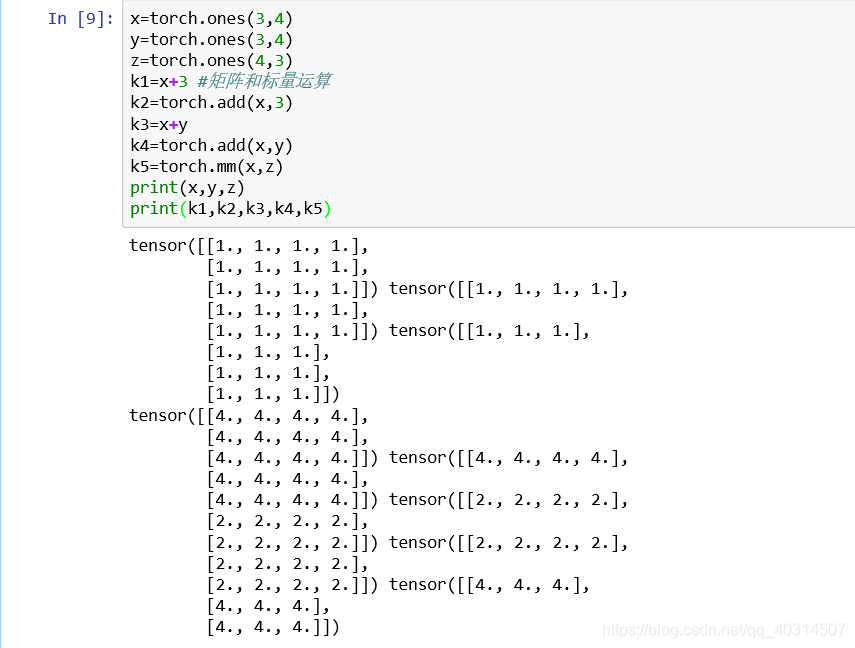
x=torch.ones(3,4)
y=torch.ones(3,4)
z=torch.ones(4,3)
k=k+3 #矩阵和标量运算
k=torch.add(x,3) #矩阵和矩阵运算
k=x+y
k=torch.add(x,y)
k=torch.mm(x,z)结果如下:
(2)高级操作
1.x.size()和x.shape

2.x.view() 矩阵的重新排列,跟numpy.reshape类似

3.unsqueeze表示加维度
squeeze表示减维度
z=torch.unsqueeze(x,dim=1)
m=x.unsqueeze(1)

4.torch.max
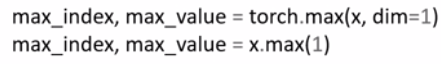
它可以返回最大值的位置和最大值是多少
5.torch.sum()

求和操作。这里是对矩阵的每一列求和。
3.Variable
为了构建神经网络,只用Tensor还不够,这就引出了Variable。本质上Variable的操作和运算和tensor是相同的,唯一的区别是variable有三个属性
- .data表示访问这个variable中的tensor
- .grad表示取得其中的梯度(相当于导师)
- .grad_fn表示如何得到这个variable
from torch.autograd import Variable
x=Variable(torch.ones(2,2),requires_grad=True)
y=Variable(torch.ones(2,2),requires_grad=True) #第二个参数表示是否需要对y求梯度
z=torch.sum(x+y)
print(z.data)
z.backward() #表示对x,y分别求梯度
print(x.grad)结果如图:


4.AutoGrad自动求导
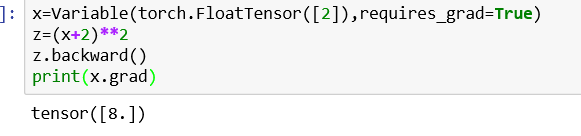
x=Variable(torch.FloatTensor([2]),requires_grad=True)
z=(x+2)**2
z.backward()
print(x.grad)结果如下图:
5.动态图
pytorch和tensorflow,caffe等框架最大的区别就是它们拥有不同的计算图表现形式。tensorflow使用静态图,这意味着我们先定义计算图,然后不断使用它,而在pytorch中,每次都会重新构建一个新的计算图。
6.小练习
6.1 tensor和variable练习
(1)
创建一个float64,大小3*2,随机初始化的tensor,将其转化为numpy的ndarray,并输出类型。
代码如下:
x=torch.randn(3,2)
x=x.type(torch.DoubleTensor)
np_tensor=x.numpy()
print(np_tensor.dtype)(2)
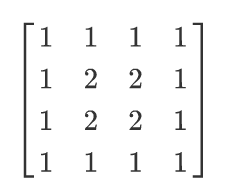
创建一个float32,4*4的全为1的矩阵,将矩阵中间2*2的矩阵全部变为2,如图:
代码如下:
x=torch.ones(4,4)
x[1:3,1:3]=2
print(x)(3)

代码如下:
x_tensor=torch.FloatTensor([2])
x=Variable(x_tensor,requires_grad=True)
print(x_tensor)
y=x**2
y.backward()
grad1=x.grad
print(grad1)
6.2自动求导小练习

代码:
x=Variable(torch.FloatTensor([2,3]),requires_grad=True)
k=Variable(torch.zeros(2))
print(x)
print(k)
k[0]=x[0]**2+3*x[1]
k[1]=x[0]*2+x[1]**2
print(k)
j=torch.zeros(2,2)
k.backward(torch.FloatTensor([1,0]),retain_graph=True)
j[0]=x.grad.data
x.grad.data.zero_() #归零之前求得的梯度
k.backward(torch.FloatTensor([0,1]))
j[1]=x.grad.data
print(j)














 2017
2017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









