






摘要
胶囊网络在事实上的基准计算机视觉数据集(例如MNIST,CIFAR和smallNORB)上显示出令人鼓舞的结果。 虽然,它们尚未在以下任务上进行测试:(1)所检测到的实体固有地具有更复杂的内部表示形式;(2)每个类中几乎没有要学习的实例;(3)逐点分类不适合。 因此,本文在受控和非受控设置下针对这些问题进行了面部验证实验。 为此,我们引入了孪生胶囊网络,这是一种可用于成对学习任务的新变体。 使用具有l2归一化胶囊编码姿势特征的对比损失来训练模型。 我们发现孪生胶囊网络在两个成对学习数据集的强基线上均表现出色,在几次拍摄的学习环境中(测试集中的图像对包含看不见的对象)产生了最佳结果。
1. 简介
卷积神经网络(CNN)一直是计算机视觉中各种任务的主要模型。尽管在进行粗略路由操作以实现平移不变时(例如最大池和平均池),特征之间的空间关系会丢失,但CNN可以有效地检测接收域中的局部特征。本质上,合并导致视点不变,因此输入中的小扰动不会影响输出。这导致有关图像中当前实体的内部属性(例如,位置,方向,形状和姿势)及其之间的关系的信息大量丢失。从各种角度来看,通常通过拥有大量带注释的数据来解决此问题,尽管在许多情况下这些数据都是多余的且效率较低。正如hinton1985shape所指出的那样,从人类形状感知的心理学角度来看,合并并不能说明在进行心理旋转以识别惯用性Rock时施加于对象上的坐标系(Rock,1973)。麦基(1979);汉弗莱斯(Humphreys)(1983)。因此,归纳了局部输入集合的局部内核区域的标量输出活动不足以保存人类感知中使用的参考帧,因为会丢弃视点信息。空间变压器网络(STN)Jaderberg等。 (2015年)通过在特征映射上使用动态空间变换来增强模型的几何不变性,已经认识到了这一问题,尽管这种方法通过学习去除旋转和比例差异解决了视点变化,而不是在模型中反映了视点变化。激活。 Hinton等人不是使用池化操作解决翻译不变性。 (2011年)致力于实现翻译等价性。最近提出的Capsule Networks Sabour等人。 (2017); Hinton等。 (2018)已显示出令人鼓舞的结果来应对这些挑战。到目前为止,胶囊网络仅在以下数据集上进行了测试:(1)每个类具有足够数量的实例以供学习,(2)用于标准分类设置中的任务。本文将Capsule Networks扩展到成对学习设置,以学习整个实体编码之间的关系,同时还展示了它们从少量数据中学习的能力,这些数据可以执行零击学习,而在测试过程中会出现来自新类的实例。使用具有l2归一化编码特征的对比损失训练了孪生胶囊网络,并在两项面部验证任务中进行了演示。
2. 胶囊网络
Hinton等。 (2011年)首先介绍了使用整体矢量来表示具有相关激活概率的实体的内部属性(称为包含姿势的实例化参数)的想法,其中每个胶囊表示图像中实体的单个实例。这不同于传统神经网络中的单标量输出,在传统神经网络中,池化被用作过滤器上的粗略路由操作。合并执行子采样,以便神经元对视点变化不变,而胶囊则希望保留信息以实现与感知系统类似的等方差。因此,将池替换为动态路由方案,以将较低层的胶囊(例如,鼻子,嘴巴,耳朵等)的输出作为输入发送到父胶囊(例如,面部),以表示部分整体关系以实现平移等方差并解开坐标通过线性变换的实体框架。这个想法起源于计算机图形学,在计算机图形学中使用内部层次表示法来渲染图像,因此,假设大脑可以解决逆向图形问题,在这种情况下,给定图像皮质将其解构成其潜在的层次属性。 Sabour等人的原始论文。 (2017)描述了一种动态路由方案,该方案将这些内部表示形式表示为矢量,给定一组称为胶囊的指定神经元,这些神经元由姿态矢量![]() 和激活α∈[0,1]组成。该体系结构由两个卷积层组成,用作第一胶囊层的初始输入表示形式,然后将其路由到最终类胶囊层。初始卷积层允许从局部特征表示中获得的知识在接收域的其他部分中重复使用和复制。胶囊输入是使用迭代动态路由方案确定的。进行变换
和激活α∈[0,1]组成。该体系结构由两个卷积层组成,用作第一胶囊层的初始输入表示形式,然后将其路由到最终类胶囊层。初始卷积层允许从局部特征表示中获得的知识在接收域的其他部分中重复使用和复制。胶囊输入是使用迭代动态路由方案确定的。进行变换![]() 以输出胶囊
以输出胶囊![]() 的向量ui。向量ui的长度表示该下层胶囊检测到给定物体且方向对应于该物体的状态(例如,方向,位置或与上层胶囊的关系)的概率。输出向量ui转换为预测向量
的向量ui。向量ui的长度表示该下层胶囊检测到给定物体且方向对应于该物体的状态(例如,方向,位置或与上层胶囊的关系)的概率。输出向量ui转换为预测向量![]() ,其中
,其中![]() 。然后,用耦合系数
。然后,用耦合系数![]() 对
对![]() 加权以获得
加权以获得![]() ,其中每个胶囊
,其中每个胶囊![]() 和
和![]() 的耦合系数通过S型函数通过对数先验概率
的耦合系数通过S型函数通过对数先验概率![]() 得到,然后是softmax,
得到,然后是softmax,![]() 。如果
。如果![]() 高当标量大小乘以
高当标量大小乘以![]() 时,耦合系数
时,耦合系数![]() 增大,而剩余的潜在父胶囊的耦合系数减小。然后,使用巧合过滤执行“按协议路由”以找到附近预测的紧密簇。实体输出矢量长度表示为实体的存在概率,方法是使用等式1中所示的非线性归一化,其中表决vj是总输入sj的输出,然后将其用于计算协议
增大,而剩余的潜在父胶囊的耦合系数减小。然后,使用巧合过滤执行“按协议路由”以找到附近预测的紧密簇。实体输出矢量长度表示为实体的存在概率,方法是使用等式1中所示的非线性归一化,其中表决vj是总输入sj的输出,然后将其用于计算协议![]() ,被添加到日志优先级bij中。
,被添加到日志优先级bij中。
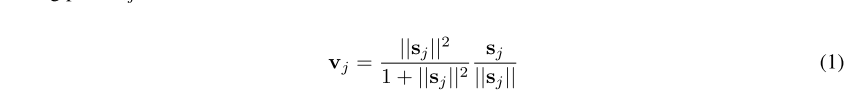
如果从s的子集中找到紧密相连的预测簇,则为胶囊分配高对数似然率。 密集簇的质心作为实体广义姿势输出。 也可以通过传统的离群值检测方法(例如随机样本共识(RANSAC)Fischler和Bolles(1987)和经典的Hough变换巴拉德(1987))来找到符合高度一致的特征空间子集,从而实现此符合过滤步骤。 虽然,使用实例化参数的矢量归一化的动机是迫使网络保留方向。 最后,将图像上的重建损失用于正则化,这约束了胶囊以学习可以更好地编码实体的属性。 在本文中,我们没有通过自动编码输入图像对来使用这种正则化方案,而是使用了dropout的变体。
胶囊网络的扩展。 Hinton等。 (2018)最近描述了矩阵胶囊,该矩阵胶囊使用期望最大化(EM)算法通过协议执行路由,该算法由计算机图形驱动,其中姿势矩阵用于定义对象的旋转和平移以解决视点变化。每个父胶囊被认为是高斯,每个子胶囊的姿势矩阵被认为是高斯的数据样本。给定的层L包含一组胶囊CL,使得![]() ,其中姿势矩阵
,其中姿势矩阵![]() 和激活
和激活![]() 为输出。对
为输出。对![]() 的姿势矩阵进行表决
的姿势矩阵进行表决![]() ,其中
,其中![]() 是来自胶囊
是来自胶囊![]() 的学习视点不变变换矩阵。 EM确定
的学习视点不变变换矩阵。 EM确定![]() 的激活,因为
的激活,因为![]() ,其中
,其中![]() 是由分配概率
是由分配概率![]() 加权的负对数概率密度,-βu是负对数计算每个姿态矩阵的概率密度,以描述
加权的负对数概率密度,-βu是负对数计算每个姿态矩阵的概率密度,以描述![]() 。如果来自较低姿态数据样本的
。如果来自较低姿态数据样本的![]() 以及
以及![]() 和λ是逆温度,则随着分配概率变高,S形曲线的斜率变得更陡峭(表示实体的存在,而不是等式1)中所示的非线性矢量归一化。该网络使用1个标准卷积层,一个初级胶囊层,2个中间胶囊卷积层,然后是最终类胶囊层。在SmallNORB数据集上,矩阵胶囊网络的性能明显优于CNN。
和λ是逆温度,则随着分配概率变高,S形曲线的斜率变得更陡峭(表示实体的存在,而不是等式1)中所示的非线性矢量归一化。该网络使用1个标准卷积层,一个初级胶囊层,2个中间胶囊卷积层,然后是最终类胶囊层。在SmallNORB数据集上,矩阵胶囊网络的性能明显优于CNN。
LaLonde和Bagci(2018)引入了SegCaps,该SegCaps使用本地连接的动态路由方案来减少参数数量,同时使用去卷积胶囊来补偿全局信息的丢失,从而显示出从低剂量CT扫描中分割病理肺部的最佳性能。与基准架构相比,该模型的参数分别减少了39%和95%,而两者均胜过两者。 Bahadori(2018)引入了在医学诊断中证明的光谱胶囊网络。该方法显示出与用于姿态矢量的EM算法相比具有更快的收敛性。空间重合滤波器将提取的特征对齐到一维线性子空间上。该体系结构由1d卷积和3个带有扩张的残差层组成。残余块R用作第一主胶囊的姿势和激活的非线性变换,而不是用于解释CV旋转的线性变换,因为尚未完全了解医疗成像中产生的变形。获得的加权票数为![]() ,其中Sj是级联投票的矩阵,然后使用SVD对其进行分解,其中第一个奇异值维s1用于捕获投票之间的大部分方差,因此,激活aj激活计算为
,其中Sj是级联投票的矩阵,然后使用SVD对其进行分解,其中第一个奇异值维s1用于捕获投票之间的大部分方差,因此,激活aj激活计算为![]() ,其中
,其中![]() 是为V中所有正确奇异矢量解释的所有方差之比,在训练过程中b被优化并且η减小。通过最大化对数似然来训练模型,该对数似然比矩阵胶囊使用的散布损失显示出更好的性能,并减轻了胶囊休眠的问题。
是为V中所有正确奇异矢量解释的所有方差之比,在训练过程中b被优化并且η减小。通过最大化对数似然来训练模型,该对数似然比矩阵胶囊使用的散布损失显示出更好的性能,并减轻了胶囊休眠的问题。
Wang和Liu(2018)正式将胶囊路由策略形式化,以优化耦合系数分布与其过去状态之间的聚类损失和KL正则项。 建议的目标函数为![]() ,其中
,其中![]() 和
和![]() 是
是![]() 的Frobenious范数。 与Sabour等人的原始路由方案相比,该路由方案显示出显着的优势。 (2017)随着路由迭代次数的增加。 显然,研究界对此产生了浓厚的兴趣。 本文旨在为如何将胶囊网络用于比较图像,对齐图像中的实体并描述一种用于测量最终层胶囊之间的相似度的方法做出贡献,从而使类别间的差异最大化而类别内的差异最小化。 首先,我们简要介绍使用Siamese Networks进行人脸验证的最新技术。
的Frobenious范数。 与Sabour等人的原始路由方案相比,该路由方案显示出显着的优势。 (2017)随着路由迭代次数的增加。 显然,研究界对此产生了浓厚的兴趣。 本文旨在为如何将胶囊网络用于比较图像,对齐图像中的实体并描述一种用于测量最终层胶囊之间的相似度的方法做出贡献,从而使类别间的差异最大化而类别内的差异最小化。 首先,我们简要介绍使用Siamese Networks进行人脸验证的最新技术。
3. 孪生人脸验证网络
孪生网络(SNs)是学习位于低维流形上的实例对的编码表示之间的关系的神经网络,其中选择的距离函数dω用于查找输出空间中的相似性。下面我们简要描述用于人脸验证和人脸识别的先进卷积序列。
Sun等。 (2014年)提出了一种联合识别验证方法,用于学习具有对比损失的人脸验证和使用交叉熵损失的人脸识别。为了平衡丢失信号以进行识别和验证,他们研究了由λ控制的权重变化对人内和人际变化的影响,其中λ= 0仅留下人脸识别损失,而λ→∞则使人脸验证损失。当λ= 0.05的个人内部变异最大化同时区分这两个类别时,可以找到最佳结果。
Wen等。 (2016年)提出了一个中心损失功能,以改善人脸识别中的判别特征学习。提出的中心损失函数旨在通过最小化类内差异同时保持不同类的特征可分离来改善特征表示之间的可分辨性。中心损失用L表示,其中![]() 。
。 ![]() 是与第i类有关的特征表示的质心,这惩罚了类中心之间的距离并最小化了类内差异,同时softmax使类间特征可分离。质心是在随机梯度下降过程中计算出来的,因为对于大型网络而言,完整批次更新是不可行的。
是与第i类有关的特征表示的质心,这惩罚了类中心之间的距离并最小化了类内差异,同时softmax使类间特征可分离。质心是在随机梯度下降过程中计算出来的,因为对于大型网络而言,完整批次更新是不可行的。
刘等。 (2017)提出了Sphereface,这是一种超球面嵌入,它使用角softmax损失来约束超球面流形上的歧视,这是由面位于流形上的先验驱动的。该模型在LFW数据集上达到99.22%,在Youtube Face(YTF)和MegaFace上具有竞争性结果。 Sankaranarayanan等。 (2016年)提出了使用三重损失![]() 进行人脸验证的三重相似度嵌入方法,其中对于T个三重态集,其锚点类别为α,正类别为p,负类别为n,投影矩阵W(通过执行PCA获得W0)最小化
进行人脸验证的三重相似度嵌入方法,其中对于T个三重态集,其锚点类别为α,正类别为p,负类别为n,投影矩阵W(通过执行PCA获得W0)最小化![]() 的约束条件。更新规则为
的约束条件。更新规则为![]() ..Hu等。 (2014)将深度度量学习用于损失
..Hu等。 (2014)将深度度量学习用于损失![]()
![]() 的人脸验证,其中
的人脸验证,其中![]() ,
,![]() 控制逻辑函数的斜率,
控制逻辑函数的斜率,![]() 是A的frobenius范数,而λ是正则化参数。因此,损失函数由逻辑损失和参数θ= [W,b]的正则化组成。结合使用SIFT描述符,密集的SIFT和局部二进制模式(LBP)可获得最佳结果,在LFW数据集上获得90.68%(+/- 1.41)的精度。
是A的frobenius范数,而λ是正则化参数。因此,损失函数由逻辑损失和参数θ= [W,b]的正则化组成。结合使用SIFT描述符,密集的SIFT和局部二进制模式(LBP)可获得最佳结果,在LFW数据集上获得90.68%(+/- 1.41)的精度。
Ranjan等。 (2017)对softmax损失使用了l2-约束来进行人脸验证,从而使编码后的人脸特征位于超球面的范围内,从而表现出良好的性能提升。这项工作也对胶囊编码的面部嵌入使用了l2-约束。FaceNetSchroff等人。 (2015年)也使用结合了Inception网络的三元组网络Szegedy等人。 (2015)和一个8层卷积模型Zeiler和Fergus(2014),该模型在训练过程中学习对齐面部斑块以执行面部验证,识别和聚类。该方法使用负面示例挖掘技术在难度越来越高的三元组上训练网络。同样,我们将针对这些任务的暹罗起始网络视为与SCN进行的一些比较之一。
Taigman等人引入的DeepFace网络是Siamese网络最相关且值得注意的用途。 (2014)。所获得的性能与“野外面孔”(LFW)数据集上的人类水平性能相当,并且大大优于以前的方法。但是,值得注意的是,此模型在来自Facebook(SFC)的大型数据集上进行了训练,因此可以认为该模型在评估之前正在执行迁移学习。该模型还执行一些手动步骤,以检测,对齐和裁剪图像中的人脸。为了检测和对齐面部,使用了3D模型。在创建3D模型之前,对图像进行标准化以避免照明值的任何差异,该模型是通过使用来自LBP直方图图像描述符的支持向量回归器首先识别图像中的6个基准点而创建的。一旦基于这些点裁剪了脸部,就可以为3D网格模型确定另外67个基准点,然后对图像的每个部分进行分段仿射变换。然后将裁剪后的图像传递到3个CNN层,其中一个初始的最大合并层随后是两个完全连接的层。与Capsule Networks类似,由于信息丢失,作者们避免在每一层使用最大池。与这项工作相反,所提出的SCN的唯一预处理步骤包括像素归一化和图像缩放。
上面的工作都使用单个CNN或各种CNN的组合达到了可比的最新水平的面部验证结果,其中一些在大型相关数据集上进行了预训练。相比之下,这项工作看起来是使用效率更高,需要较少预处理步骤(即仅调整图像大小和对输入特征进行归一化,无需对齐,裁剪等)的小型胶囊网络,并且可以从相对较少的数据中学习。
4. 孪生胶囊网络
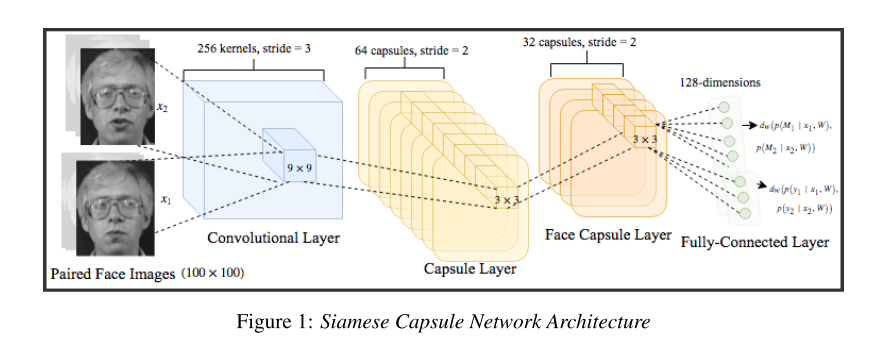
用于面部验证的胶囊网络旨在识别面部特征及其姿势的已编码的部分-整体关系,进而通过在配对图像之间对齐胶囊特征,从而导致改进的相似性度量。该架构由权重受限的5个隐藏层(包括2个胶囊层)网络组成(因为两个输入均来自同一域)。第一层是卷积滤波器,其步长为3和256个通道,在图像对![]() 上具有内核
上具有内核![]() ,产生20992个参数。第2层是主要的胶囊层,采用
,产生20992个参数。第2层是主要的胶囊层,采用![]() 并输出32个胶囊的
并输出32个胶囊的![]() 矩阵,从而得出5.309×106的参数(8个胶囊中的每一个的663552权重和32个偏差)。第三层是面部胶囊层,代表面部特征的各种属性的路由,由5.90×106参数组成。然后,通过将姿势矢量
矩阵,从而得出5.309×106的参数(8个胶囊中的每一个的663552权重和32个偏差)。第三层是面部胶囊层,代表面部特征的各种属性的路由,由5.90×106参数组成。然后,通过将姿势矢量![]() 连接为输入,将此层传递到单个完全连接的层,而S型函数控制训练期间每个胶囊的掉落率。公式1中所示的非线性矢量归一化被替换为tanh函数
连接为输入,将此层传递到单个完全连接的层,而S型函数控制训练期间每个胶囊的掉落率。公式1中所示的非线性矢量归一化被替换为tanh函数![]() ,我们在初始测试中发现该函数可产生更好的结果。欧氏距离,曼哈顿距离和余弦相似度被视为胶囊图像编码之间的度量。前述SCN体系结构描述了AT&T数据集的设置。对于LFW数据集,使用6个路由迭代,对于AT&T使用4个路由迭代。
,我们在初始测试中发现该函数可产生更好的结果。欧氏距离,曼哈顿距离和余弦相似度被视为胶囊图像编码之间的度量。前述SCN体系结构描述了AT&T数据集的设置。对于LFW数据集,使用6个路由迭代,对于AT&T使用4个路由迭代。
胶囊编码表示。 为了将成对的图像<x1,x2>编码为向量对<h1,h2>,每个胶囊的姿态向量都被矢量化,并作为输入传递到包含20个激活单元的完全连接的层中。因此,对于每个输入,都有32个胶囊姿态矢量的较低20维表示,从而产生512个输入特征。为了确保所有胶囊保持活动状态,需要了解每个胶囊的脱落概率。乙状结肠功能使用Concrete Dropout Gal等人方法了解最终胶囊层的脱落率。 (2017),它是基于先前的工作Kingma等。 (2015); Molchanov等。 (2017)通过使用连续松弛来近似用于离散的离散伯努利分布,称为具体分布。公式2显示了更新混凝土分布的目标函数。对于最后一个胶囊层中给定的胶囊概率pc,S型计算伯努利变量z的弛豫〜z,其中u均匀地绘制在[0,1]之间,其中t表示温度值(在我们的实验中t = 0.1)当极小时,这会迫使极值出现在概率上。逐行导数估计器用于查找丢包的连续估计。
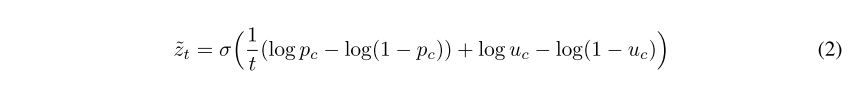
损失函数。 具有动态路由功能的原始胶囊纸Sabour等。 (2017)使用裕度损失![]() ,其中类胶囊vc的裕度m + = 0.9正,m− = 1–m +负。如果不存在类胶囊,则权重λ用于防止活动矢量长度在训练的早期恶化。那么,总损失仅仅是胶囊损失
,其中类胶囊vc的裕度m + = 0.9正,m− = 1–m +负。如果不存在类胶囊,则权重λ用于防止活动矢量长度在训练的早期恶化。那么,总损失仅仅是胶囊损失![]() 的总和。价差损失Hinton等。 (2018)也已用于最大化目标类别和其余类别之间的类别间距离,以便在smallNORB数据集上进行分类。以
的总和。价差损失Hinton等。 (2018)也已用于最大化目标类别和其余类别之间的类别间距离,以便在smallNORB数据集上进行分类。以![]() 表示,在训练过程中边距m线性增加,以确保较低水平的胶囊在整个训练过程中保持活动状态。相反,这项工作使用对比边缘损失Chopra等人。 (2005),其中上述胶囊编码相似度函数dω输出预测的相似度得分。对比损失Lc确保将相似的矢量化姿态编码汇总在一起,并排斥相异的姿态。公式3显示了一对传递到SCN模型的图像,其中
表示,在训练过程中边距m线性增加,以确保较低水平的胶囊在整个训练过程中保持活动状态。相反,这项工作使用对比边缘损失Chopra等人。 (2005),其中上述胶囊编码相似度函数dω输出预测的相似度得分。对比损失Lc确保将相似的矢量化姿态编码汇总在一起,并排斥相异的姿态。公式3显示了一对传递到SCN模型的图像,其中![]() 计算编码之间的欧几里得距离,m为边距。当使用曼哈顿距离
计算编码之间的欧几里得距离,m为边距。当使用曼哈顿距离![]() 时,在y处使用
时,在y处使用![]() 的情况。
的情况。
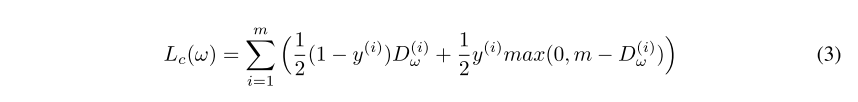
Lin等人在先前的工作中已经使用了双重保证金损失。 (2015)也被认为会影响匹配对,从而考虑到正对也可能在距离测量中具有高方差。 值得注意的是,这种双重余量类似于在不使用λ的情况下用于类胶囊的上述余量损失。 公式4显示了双边距对比损失,其中正余量mp和负余量mn用于在匹配对和非匹配对之间找到更好的分隔。 考虑到AT&T中的实例数量有限,这种损失仅用于LFW,在实验中我们发现线对之间的重叠量不太严重。
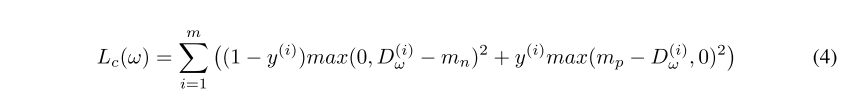
在成对学习设置中未使用用作正则化的原始重建损失![]() ,而是我们依赖于dropout进行正则化,但SCN模型除外,后者在最后一层使用了具体的dropout。
,而是我们依赖于dropout进行正则化,但SCN模型除外,后者在最后一层使用了具体的dropout。
优化。 对于人脸验证任务,收敛通常相对较慢,其中很少提供有用信息的批次更新(例如,给定类别的姿势具有明显不同的样本)获得较大更新,但是在通过梯度指数平均(最初是为了防止α→ 0)。 根据最近发现的可提高自适应学习率的发现,我们使用了AMSGrad Reddi等人的方法。 (2018)。 在某些情况下,AMSGrad相对于ADAM进行了改进,将平方梯度的指数平均值替换为最大值,该最大值通过保留对过去梯度的长期记忆来缓解了该问题。 因此,AMSGrad不会基于梯度变化来提高或降低学习率,避免随着时间的推移出现发散或消失的步长。 公式5给出了更新规则,其中梯度gt的对角线为![]()
![]() ,确保α是单调的。
,确保α是单调的。
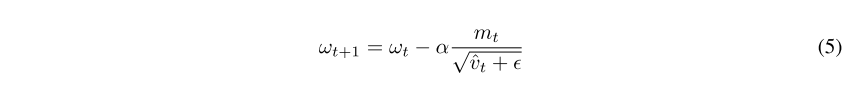
5. 人脸验证实验
A. AT&T数据集。 AT&T人脸识别和验证数据集由40个不同的对象组成,在受控设置下每个对象只有10个灰度像素图像。 这个较小的数据集使我们能够测试SCN如何用很少的数据执行。 为了进行测试,我们提供了5个科目,以便我们针对看不见的科目进行测试,而不是针对某个主题的给定视点进行训练,而针对同一主题的另一视点进行测试。 因此,在测试期间执行零射对成对预测。
B.带有标签的野外面孔(LFW)数据集。 LFW包含来自网络的13,000张彩色照片面孔。该数据集非常复杂,这不仅是因为存在1680个对象,其中一些对象仅由两个图像组成,还因为年龄,姿势,性别,光线和其他此类自然特征的变化。每个图像为250×250,在此工作中,图像被调整为100×100并进行规格化。从原始的LFW数据集中,有两个不同版本的数据集使用漏斗Huang等人的方法将图像对齐。 (2007年)和黄漏斗等。 (2012)。后者学习使用受限的Boltzmann机器对图像进行对齐,并具有稀疏度,从而提高了面部验证任务的性能。损失导致滤波器的布置改善了对准结果。这克服了以前的CNN和模型在解决姿势,方向和胶囊网络希望解决的问题时遇到的问题。相反,我们使用原始的原始图像数据集。
两者都允许一个合适的变化,因为前者仅包含灰色像素图像,较小的数据集(每个类别只有很少的实例)和在受限设置下拍摄的图像,可以进行更精细的分析,而LFW数据样本是彩色图像,相对较大具有不平衡的班级,并且不受限制。
基线。 将SCN与用于图像识别和验证任务的完善体系结构进行比较,这些体系结构是AlexNet,ResNet-34和InceptionV3,具有6个初始层,而不是使用8层的原始网络,第3节中的许多上述论文都使用了SCN。
5.1 结果
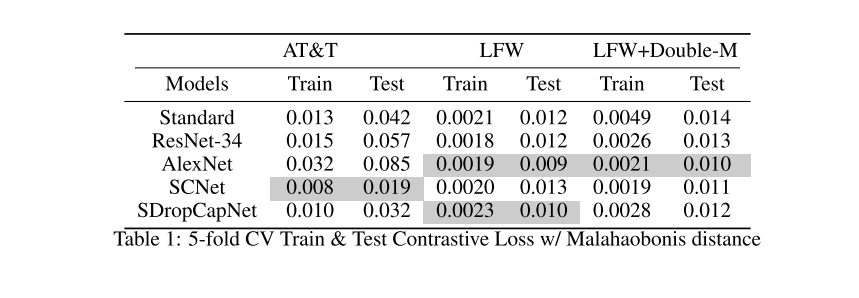
表1列出了在100个以上的时间段内,AT&T和LFW在编码之间使用欧几里得距离进行对比损失(马氏距离)时获得的最佳测试结果。前者使用m = 2.0,而后者使用m = 0.2,而对于双余量对比损失mn = 0.2匹配余量和mp = 0.5负匹配余量。这些设置是在5倍交叉验证期间选择的,网格搜索可能的边距设置。在训练了100个纪元后,SCN的表现优于AT&T数据集上的基线。我们发现,由于AT&T所包含的实例少得多,因此调整后的辍学率会导致对比损失略有增加。此外,与在除编码姿态矢量的最后一层以外的所有层上使用速率为p = 0.2的丢包相比,两张配对图像的λr= 1e-4的重建损失均导致性能下降。对于LFW数据集,我们发现SCN和AlexNet获得了最佳结果,而SCN的参数减少了25%。此外,使用双倍余量可以为标准SCN带来更好的结果,但与最后一层(即SDropCapNet)的具体压降一起使用时,性能会略有下降。
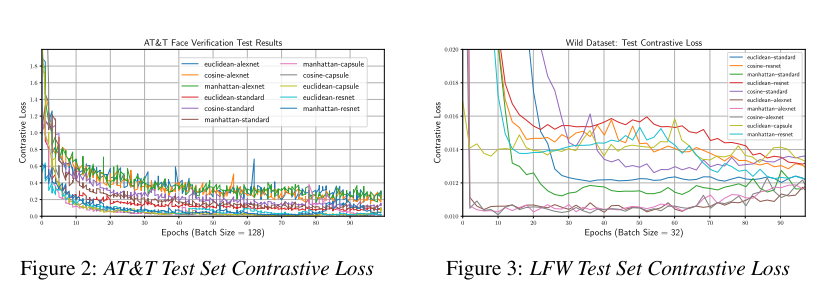
图2说明了在用AT&T上的各种距离测量测试的每个模型的l2归一化特征训练过程中的对比损失。我们发现SCN可以在AT&T上更快地收敛,特别是在使用Manhattan距离时。但是,对于欧几里得距离,我们观察到训练过程中损失方差的减少以及最佳的整体表现。通过实验,我们发现批量归一化卷积层提高了SCN的性能。在批次归一化中,![]() 提供了单位高斯批次,将其移位
提供了单位高斯批次,将其移位![]() 并按
并按![]() 进行缩放,从而得到
进行缩放,从而得到![]() 。这使网络能够了解输入范围是应扩散还是应扩散。初始卷积层上的批量归一化减少了AT&T和LFW数据集训练期间损失的方差。图3所示的LFW测试结果表明,与AlexNet相比,SCN模型收敛所需的时间更长,尤其是在训练的早期阶段。
。这使网络能够了解输入范围是应扩散还是应扩散。初始卷积层上的批量归一化减少了AT&T和LFW数据集训练期间损失的方差。图3所示的LFW测试结果表明,与AlexNet相比,SCN模型收敛所需的时间更长,尤其是在训练的早期阶段。
为了说明即使基于人脸方向略有变化,基于CNN的体系结构也存在的一些困难,我们将ResNet网络的低级特征可视化,如图4所示。这些是从第一卷积层的较大内核中获得的解码特征。 。我们看到,即使在受控设置下,从图像2、6和7(从左到右)对面部的轻微旋转也表明,由于鼻梁附近的旋转扭曲,输出变暗。与孪生胶囊网络相比,这体现在测试损失差异上。
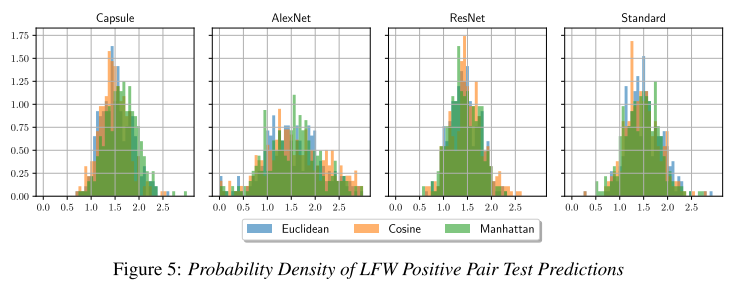
图5显示了LFW数据集在编码之间的所有距离下每个模型的正对预测的概率密度以及对比损失。我们发现与其他模型相比,预测的方差较低,这表明预测的准确性更高,尤其是对于曼哈顿距离而言。另外,这些匹配图像的变化距离与不匹配图像的变化接近。这激发了考虑用于LFW数据集的双重保证金损失。
最后,对于两个数据集,SCN模型的参数比Alexnet少104-116%,Resnet-34少24-27%,并且比最佳标准基线少127-135%。但是,即使考虑到SCN中模型之间的约束权重,由于训练期间必需的路由迭代,即使参数减少了,胶囊网络也仍然受到速度的限制。

6. 总结
本文介绍了孪生胶囊网络,这是一种新颖的体系结构,其将Capsule网络扩展到成对学习设置,并具有l2-归一化对比损失,可最大程度地减少类间差异并最小化类内差异。 结果表明,胶囊网络在仅通过少量示例进行学习时表现更好,并且在使用采用编码胶囊姿态矢量形式的面部嵌入的对比损失时,收敛速度更快。 我们发现孪生胶囊网络在快速拍摄设置中的AT&T数据集上表现特别出色,该设置在测试过程中在未见过的班级(即受试者)上进行了测试,同时与较大的野生标签数据集的基线相比具有竞争力。















 4042
4042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









