







 CNN的层级结构一、数据的输入层二、卷积计算层-1、
CNN的层级结构一、数据的输入层二、卷积计算层-1、
CNN的层级结构
[参考CNN的网络结构](https://blog.csdn.net/u014303046/article/details/86021346)一、数据的输入层
二、卷积计算层(核心部分)
- 1、传统的电脑进行图片匹配:
我们给定一个字母X的图片,若电脑中存在一张一模一样的图片,我们将其进行比对则可以识别;若X经过放缩或者旋转后,则电脑可能就无法识别(照片中对应点的像素值不同) - 2、CNN识别:
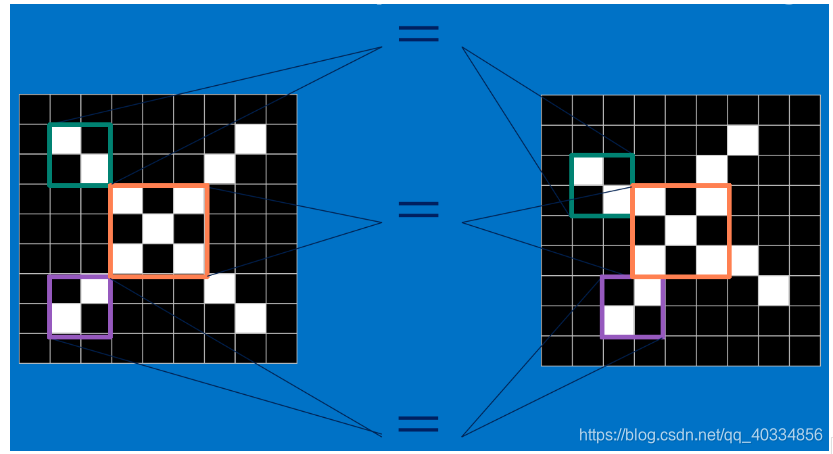
(1)CNN可以对一些经过变化后的图片进行识别,它是通过将未知图片的局部和标准图片的局部进行一个局部的对比,如上图。将两者局部对比的过程,则为卷积的操作,结果为1则表示匹配,否则表示不匹配。
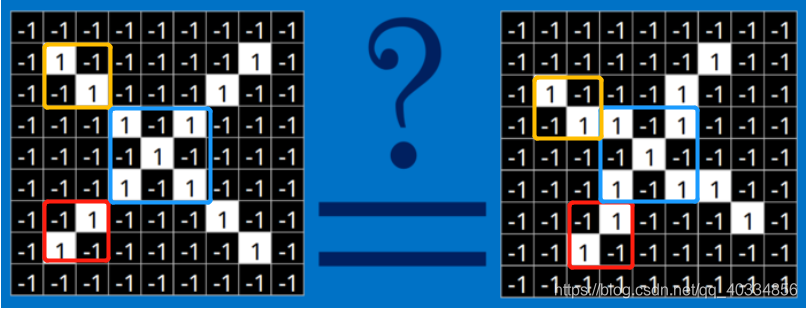
(2)对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为feature(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法。其中每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的feature匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。

这是标准X中的features;这些features几乎可以匹配含有X的图中,字母X的四个角和它的中心,具体匹配如下:
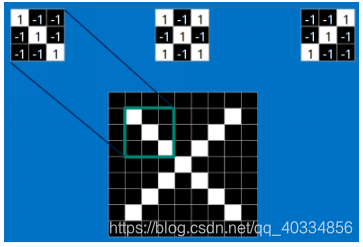
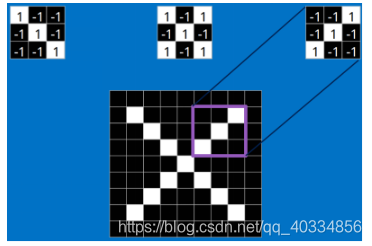
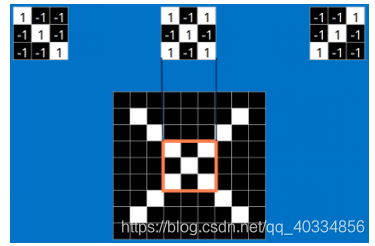

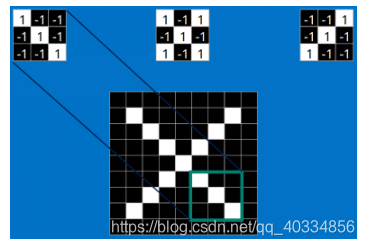
(3)上图中每一个小块之间的匹配则为卷积操作。对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看作一个恒定的滤波器filter)做内积(逐个元素相乘再进行求和)的操作就是卷积操作。
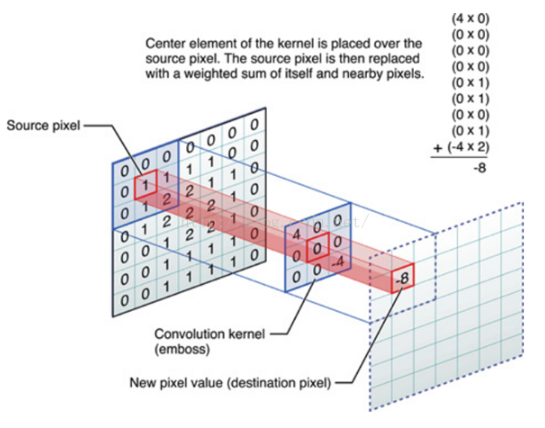
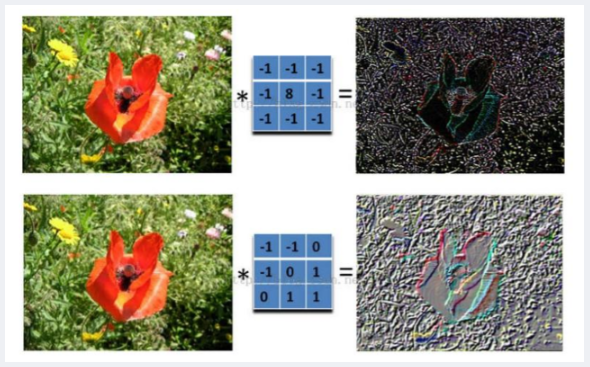
(4)同一张图片中的像素点是固定的,我们可以通过不同的滤波矩阵(共享权值矩阵)得出我们从图片中想要得到的不同特征,在下图中我们通过两组不同的滤波,分别得出了颜色深浅信息和轮廓信息
- 3、卷积层的计算
(1)在CNN中,滤波器filter(带着一组固定共享的权重神经元)对局部输入的数据进行卷积计算。每次计算完一个数据窗口内的数据后,数据窗口平滑移动,直到计算完所有的数据。在计算中有如下几个参数:
深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器的个数
步长stride:决定一次移动几步,一共多少步可以到达边缘
填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑到末尾的位置,也可以通过这种方法来控制输出数据的大小
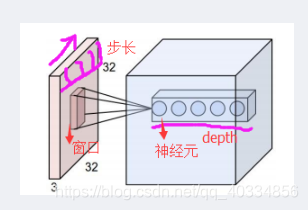
(2)如下在实际的三通道彩色图片的计算
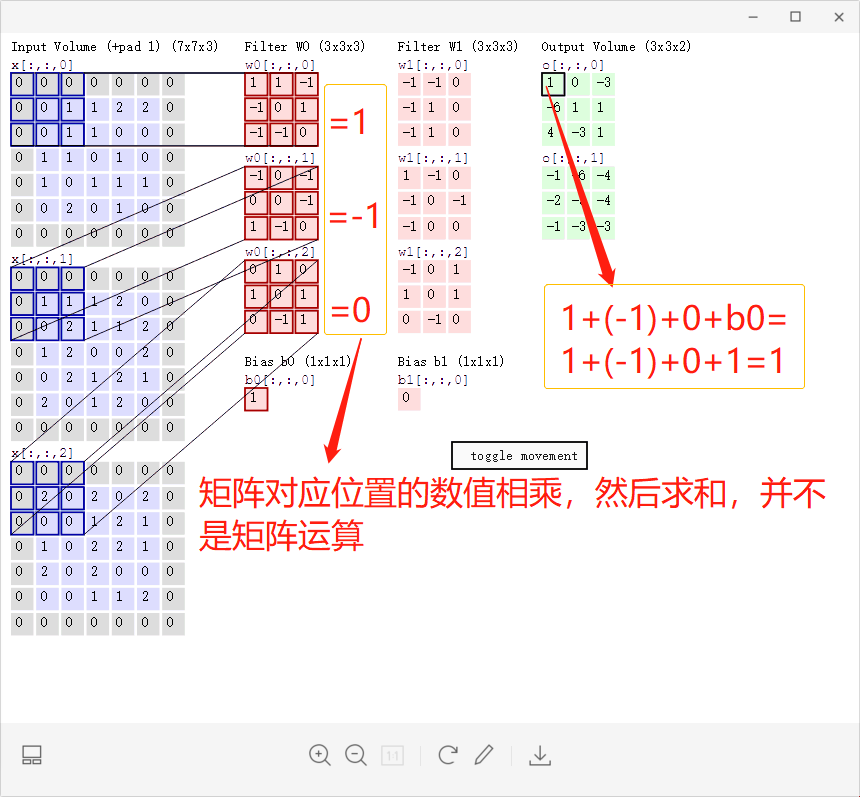
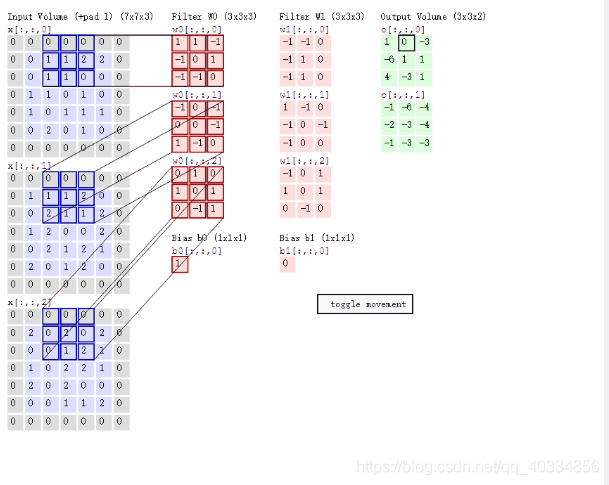
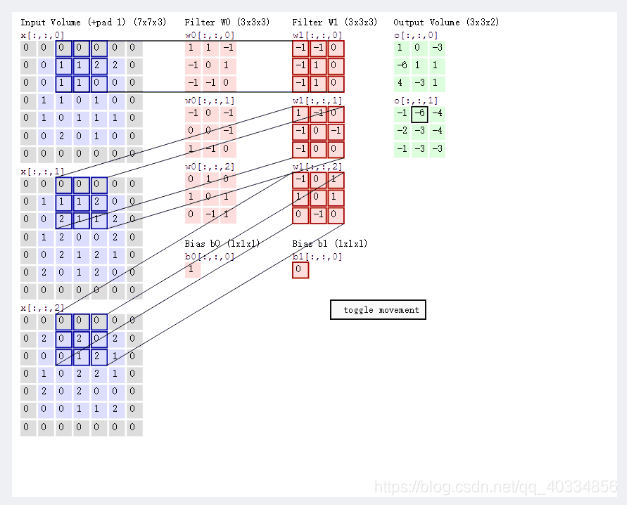
上图的计算可以得出:
P1:输入层为773(77表示的是图像的像素,外圈的0是我们自己补充的,3代表的是R、G、B三通道)
P2:存在两个神经元(滤波器W0、滤波器W1),即depth=2
P3:步长为2,每次滑动的距离为2,即stride = 2
P4:在周围补充了一圈零,zero-padding = 1
P5:输出为最右侧两个不同的33的数值矩阵
P6:每一次平滑移动后的新数据都会进行不同的计算,这些新数据的计算就相当于局部感知机制。
height = (H-F)/S+1;width = (W-F)/S+1;H、W分别指输入图的尺寸,F为卷积核大小,S表示步长
4、卷积核大小的选取
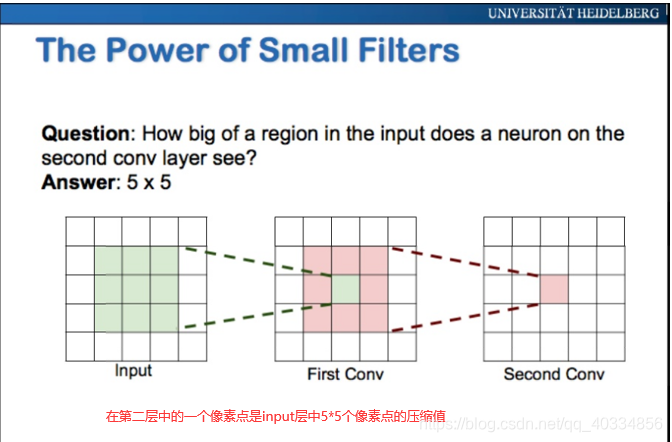
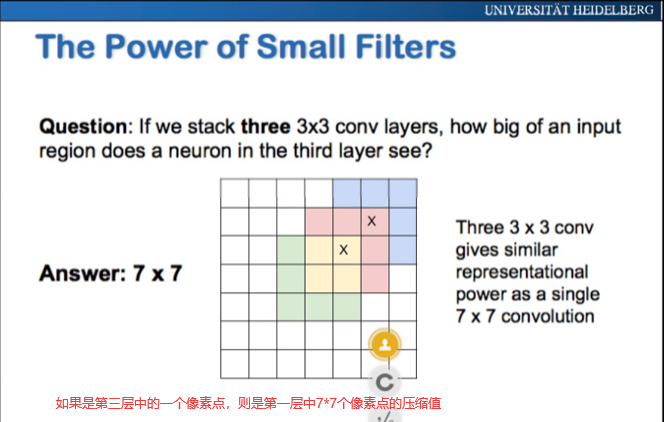

三、激励层
1、引入激活函数的目的是,在模型中引入非线性。如果没有激活函数,无论神经网络有多少层,最终都是一个线性映射,单纯的线性映射,无法解决线性不可分问题。引入非线性可以让模型解决线性不可分问题。
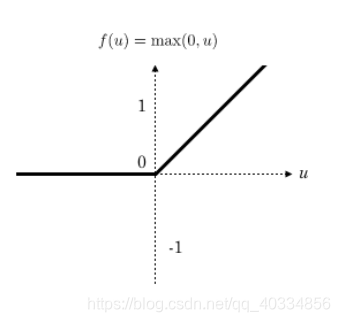
2、 R e l u ( z ) Relu(z) Relu(z)激活函数
(1)relu函数计算简单,可以加快模型的计算速度
四、池化层(pooling)
1、池化,实际是一个下采样的过程。由于输入的图片尺寸可能比较大,这时候,我们可以通过下采样来减小图片的尺寸。池化层,可以减小模型的规模,提高运算的速度以及提高所提取特征的鲁棒性。
2、池化操作也有核大小 f f f和步长 s s s参数,它们的含义和卷积参数的意义相同
3、介绍常用的两种池化(最大池化(Max Pooling)和平均池化(Average Pooling))
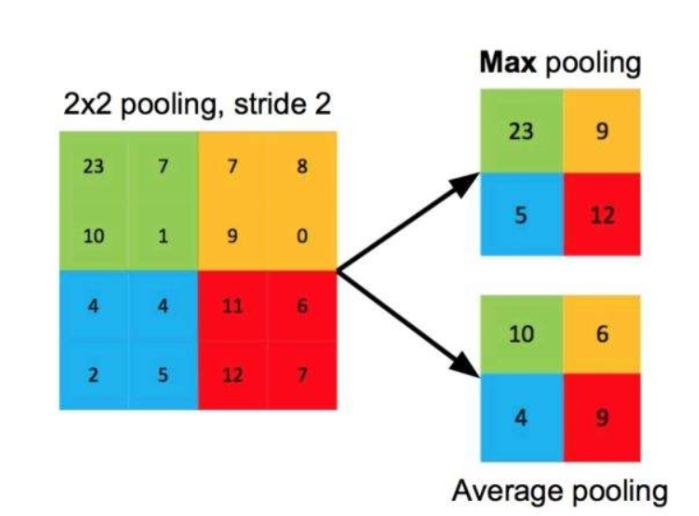
(1)最大池化
所谓最大池化,就是对于 f × f f×f f×f大小的池化核,选取原图中数值最大的那个保留下来。比如,池化核 2 ∗ 2 2*2 2∗2大小,步长为2的池化过程如下(左边是池化前,右边是池化后),对于每个池化区域都取最大值:
(2)平均池化:
所谓平均池化,就是对于 f × f f×f f×f大小的池化核,选取原图中的平均数值进行计算。比如,池化核 2 ∗ 2 2*2 2∗2大小,步长为2的池化过程如下(左边是池化前,右边是池化后),对于每个池化区域都取平均值:
五、卷积神经网络的前向传播过程
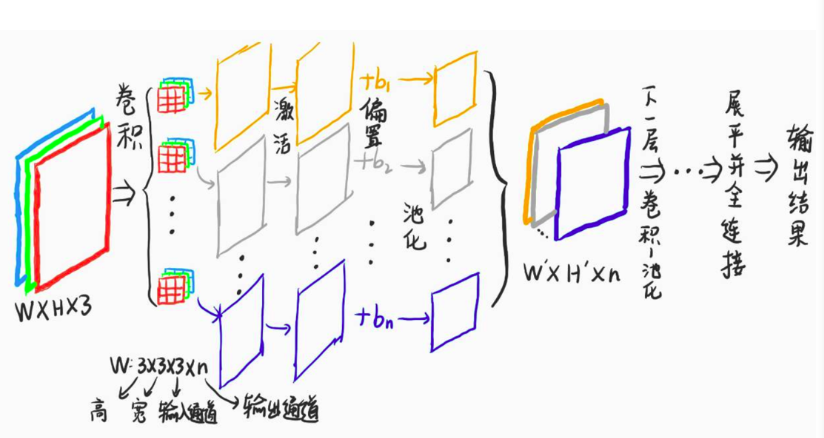
1、传播流程(多个卷积、池化…类似全连接神经网络中的多层隐藏层结构)
(1)输入数据:三通道彩色图像WH3
(2)卷积操作:卷积过程采用n个卷积核,每个卷积核都有三个通道(卷积核的通道和输入图片的通道数目相同),随着特征图的通道数不同,每次的通道数可能都会发生改变。
(3)激活操作:将卷积后的结果进行激活(个人认为偏置应该在激活前处理)
(4)池化操作
(5)将(4)得到的结果为( W ′ ∗ H ′ ∗ n W\prime*H\prime*n W′∗H′∗n)进行下一步的卷积操作(此时卷积核的层数应该为n),重复(2)(3)(5)操作,直到最后的全连接操作。
(6)全连接结构和BP网络类似。我们需要设计合适的损失函数,反向传播最小化的损失函数,优化网络的参数,达到模型的预期效果
2、一些卷积网络中的符号表示
(1)卷积conv2d(input,filter,strides,padding)
- input:卷积输入 ( H × W × C i n , C i n 指 的 是 输 入 的 通 道 数 ) (H×W×C_{in},C_in指的是输入的通道数) (H×W×Cin,Cin指的是输入的通道数)
- filter:卷积核W ( f h e i g h t × f w i d t h × C i n × C o u t ) (f_{height}×f_{width}×C_{in}×C_{out}) (fheight×fwidth×Cin×Cout)
- strides:步长,一般为1×1×1×11×1×1×1
- padding:指明padding的算法,‘SAME’或者‘VALID’(SAME表示维持原有的维度不变)
(2)激活relu(conv)
- conv:卷积的结果
(3)偏置相加add(conv,b)
- conv:卷积的激活输出
- b:偏置系数
(4)池化max_pool(value,ksize,strides,padding)
- value:卷积的输出
- ksize:池化尺寸 一般为2*2
- strides:步长
- padding:指明padding的算法,‘SAME’(输出为等大的矩阵)或者‘VALID’
六、卷积神经网络的反向传播过程
1、对比全连接神经网络的反向传播过程。卷积神经网络的反向传播过程与其类似,但是并不是一样的,区别如下
(1)卷积神经网络的卷积核,每次滑动只与部分输入相连,具有局部映射的特点,在误差反向传播的时候,需要确定卷积核的局部连接方式。
(2)卷积神经网络的池化过程中丢失了大量的信息,误差反传,则需要恢复这些丢失的信息
2、卷积层的误差反传
(1)假设损失函数为Loss,现在通过损失函数对参数W和偏置b的梯度进行求解。
(2)卷积核W的梯度
- Z [ l ] = c o n v 2 d ( Z p o o l [ l − 1 ] , ( W , b ) , s t r i d e s = 1 , p a d d i n g = ′ S A M E ′ ) Z{^{[l]}} = conv2d(Z{^{[l-1]}_{pool}},(W,b),strides = 1,padding='SAME') Z[l]=conv2d(Zpool[l−1],(W,b),strides=1,padding=′SAME′) = ∑ m ∑ n W m ′ , n ′ [ l ] Z p o o l _ m , n [ l − 1 ] + b [ l ] =\sum^m\sum^nW{_{m',n'}^{[l]}}Z{_{pool\_m,n}^{[l-1]}}+b^{[l]}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9833
9833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









