






程序旨在学习如何使用Transformer对一维序列进行分类,如何调整序列的输入格式和构建网络。
在使用此程序时,建议先大致了解Transformer框架的基本结构:
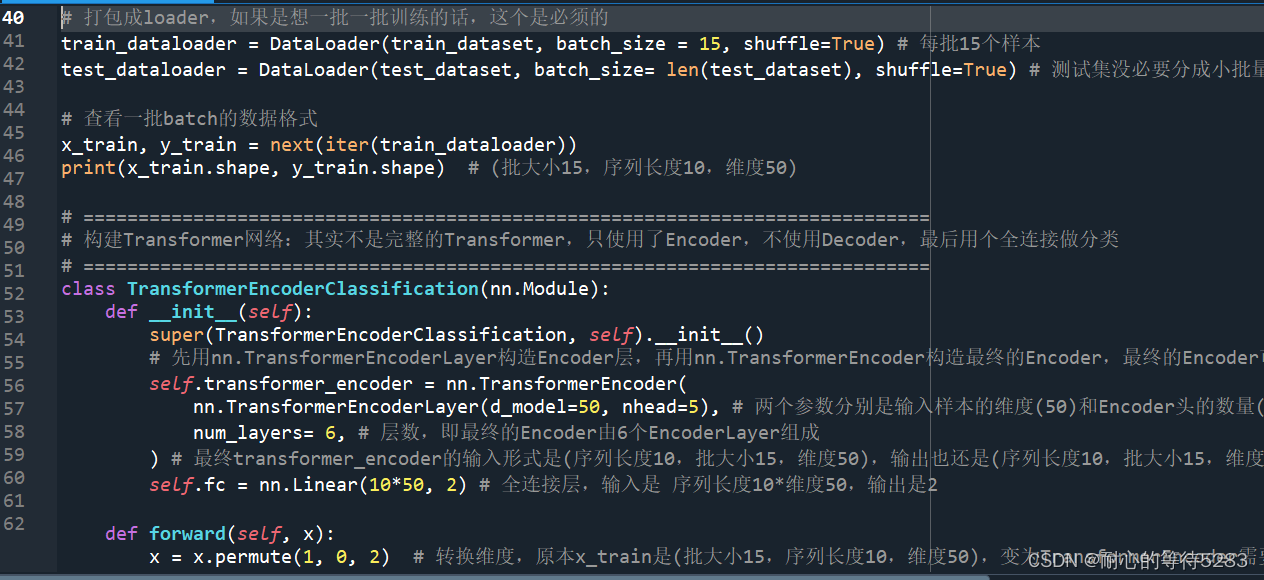
Transformer模型中有Encoder和Decoder模块。参考了许多使用Transformer做分类的程序,模型中均是只使用了Encoder模块。本程序中,使用了6层Encoder模块和最终的全连接层进行序列分类,没有使用Decoder模块和Embedding模块(Embedding模块是用于文本嵌入的,本程序数据是序列,因此不用做嵌入)。
程序工作如下:
1、加载数据,调整为模型需要的输入格式。原始数据为Excel,400条1*500的序列(心电信号),其中200条正常,200条异常。将每条1*500的信号reshape成10*50,即序列长度10*维度50。这里也可以理解成把序列看成了文本,每个样本由10个单词(序列长度10)组成,每个单词是50个数字(维度50)。这样做是为了满足Transformer的输入格式。
2、构建Transformer模型。其中包含6层的Encoder层和最终的全连接层。
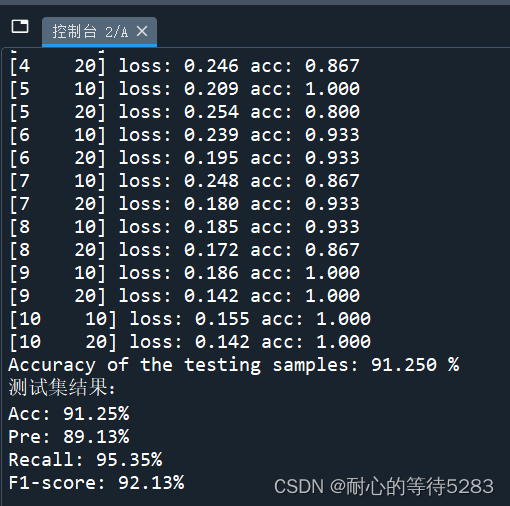
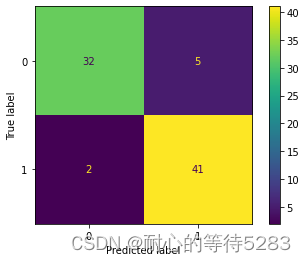
3、训练、测试。显示训练集准确率和Loss变化,计算测试集Acc、Pre、Recall、F1-score,绘制混淆矩阵。
注:程序注释详细,书写规范,容易看懂。包含原始数据和代码,能直接运行,如运行遇到问题可远程帮忙调通。本程序是实现二分类,看懂后也可方便改为多分类。数据为Excel,方便替换为自己的数据,但需要大致看懂并修改程序中的数据维度转化部分和修改模型的输入维度等参数。时间关系仅解答简单问题,谢谢理解。
程序完全由本人手写,整理不易,价格19元。唯一渠道为闲鱼售卖,诚信第一,谴责其他网站高价售卖~
【闲鱼链接】:https://m.tb.cn/h.5wVr0Hs?tk=GvpoWNqIVVv MF7997
如果链接失效的话,可在闲鱼搜索:耐心的等待5283,然后点“用户”即可找到个人主页下的程序。














 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









