







目录
统计学习方法——k近邻法
算法描述
k近邻算法是一种基本分类与回归方法。李航老师的书中只讨论了分类问题。
k近邻算法简单直观:
(1)给定一个训练数据集
(2)对于新的输入实例,在训练数据集中找到与该实例最邻近的k个实例
(3)这k个实例多数属于某个类,就将该输入实例分到这个类中
算法3.1(k近邻法)
输入:训练数据集
其中,为实例的特征向量,
为实例的类别,
实例特征向量
;
输出:实例所属的类y
(1)根据给定的距离度量,在训练集T中找出与x最邻近的k个点,涵盖这k个点x的邻域记为
(2)在中根据分类决策规则(如多数表决)决定x的类别y
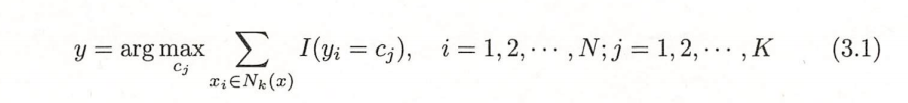
I为指示函数,当时I为1,否则为0,I值最大,求出的
也就是新的输入实例类别
k=1时,称为最近邻算法,最近邻算法将训练数据集中与x最邻近的点的类作为x的类
k近邻模型
k近邻模型三要素=距离度量+k值选择+分类决策规划
距离度量
设特征空间X时n为实数向量空间,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









