







1. k近邻算法定义
给定一个训练集,对新的输入实例,在训练数据集汇总找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类.
2. k近邻算法模型基本要素
2.1 距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映.距离度量可以使用欧式距离,或更一般的Lp距离、Minkowski距离.

2.2 k值的选择

在应用中,k一般取一个比较小的数值(小于20),通常采用交叉验证法来选去最优k值.
近似误差和估计误差的区别:
近似误差:可以理解为对现有训练集的训练误差。
估计误差:可以理解为对测试集的测试误差。
2.3 分类决策规则
k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类.
3. k近邻算法的实现:kd树
3.1 构造kd树
实现k近邻法时,主要考虑的问题时如何对训练数据进行快速k近邻搜索,尤其是当特征空间的维数大及训练数据容量大时.
构造kd树算法:


注:l=j(mod k) + 1,即轮流的使用k维空间的每个维度进行划分。
如有许多个点,空间为三维,首先使用x维,选取x轴中位数点进行划分,然后使用y轴,选取y轴中位数点进行划分,然后使用z轴,选取z轴中位数点进行划分,这时点如果还没有划分到每个节点(即kd树每个节点有1个点),再依次使用x、y、z轴对剩余的点进行划分。
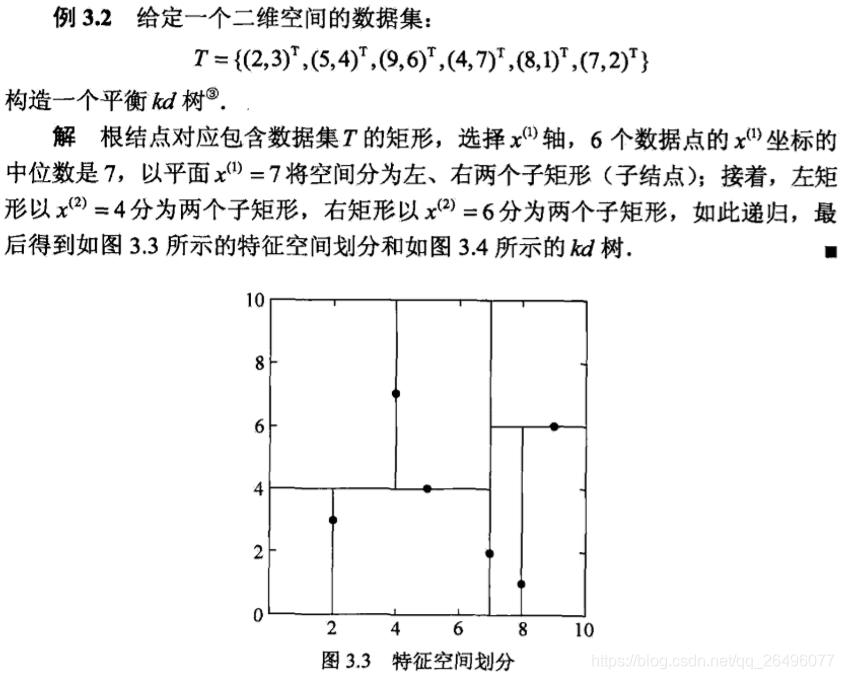
注:划分的时候取中位数该处是向上取整,如6个数取第4个。
3.2 搜索kd树
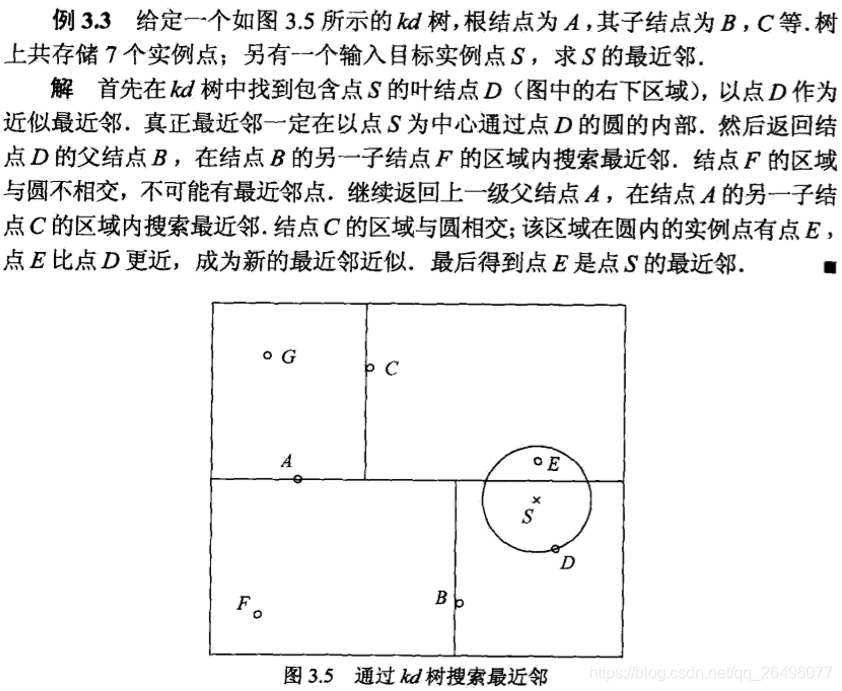
注:kd树每一个节点都表示包含该节点坐标值的一个区域。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









