







paper:https://arxiv.org/abs/2005.12872
Github开源地址:facebookresearch/detr
一、创新点
将目标检测任务转化为一个序列预测(set prediction)的任务,使用transformer编码-解码器结构和双边匹配的方法,由输入图像直接得到预测结果序列。和SOTA的检测方法不同,没有proposal(Faster R-CNN),没有anchor(YOLO),没有center(CenterNet),也没有繁琐的NMS,直接预测检测框和类别,利用二分图匹配的匈牙利算法,将CNN和transformer巧妙的结合,实现目标检测的任务。
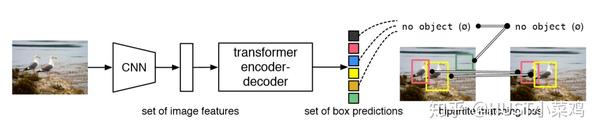
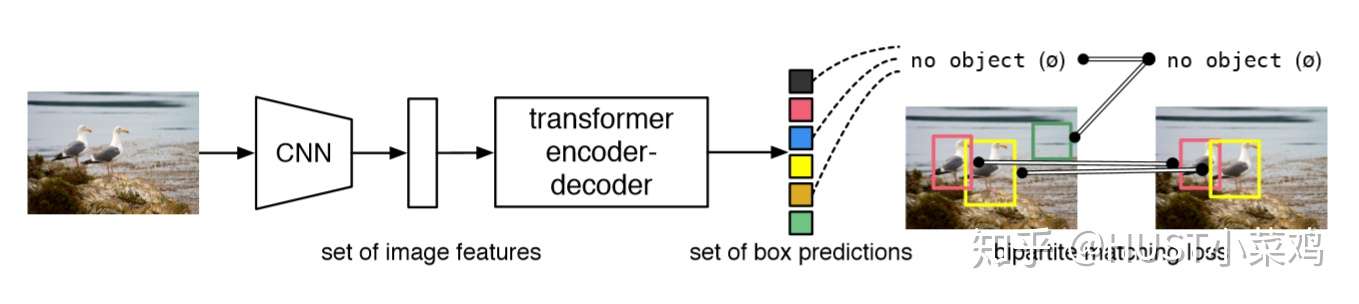
在本文的检测框架中,有两个至关重要的因素:①使预测框和ground truth之间一对一匹配的序列预测loss;②预测一组目标序列,并对它们之间关系进行建模的网络结构。接下来依次介绍这两个因素的设计方法。
1、模型的整体结构
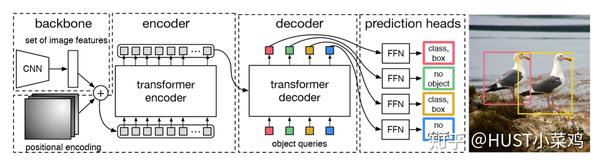
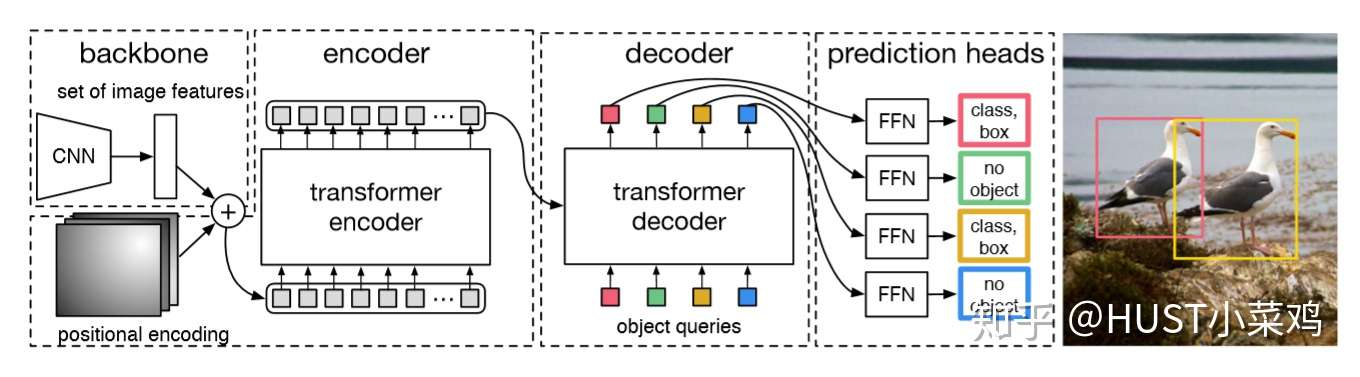
Backbone + transformer + Prediction
CNN + encoder+decoder + FFN
(1)backbone
利用传统的CNN网络,将输入的图像 变成尺度为
的特征图f
(2)Transformer
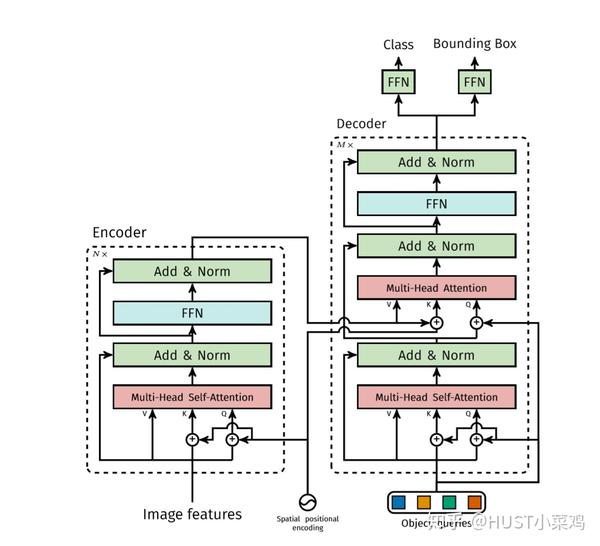
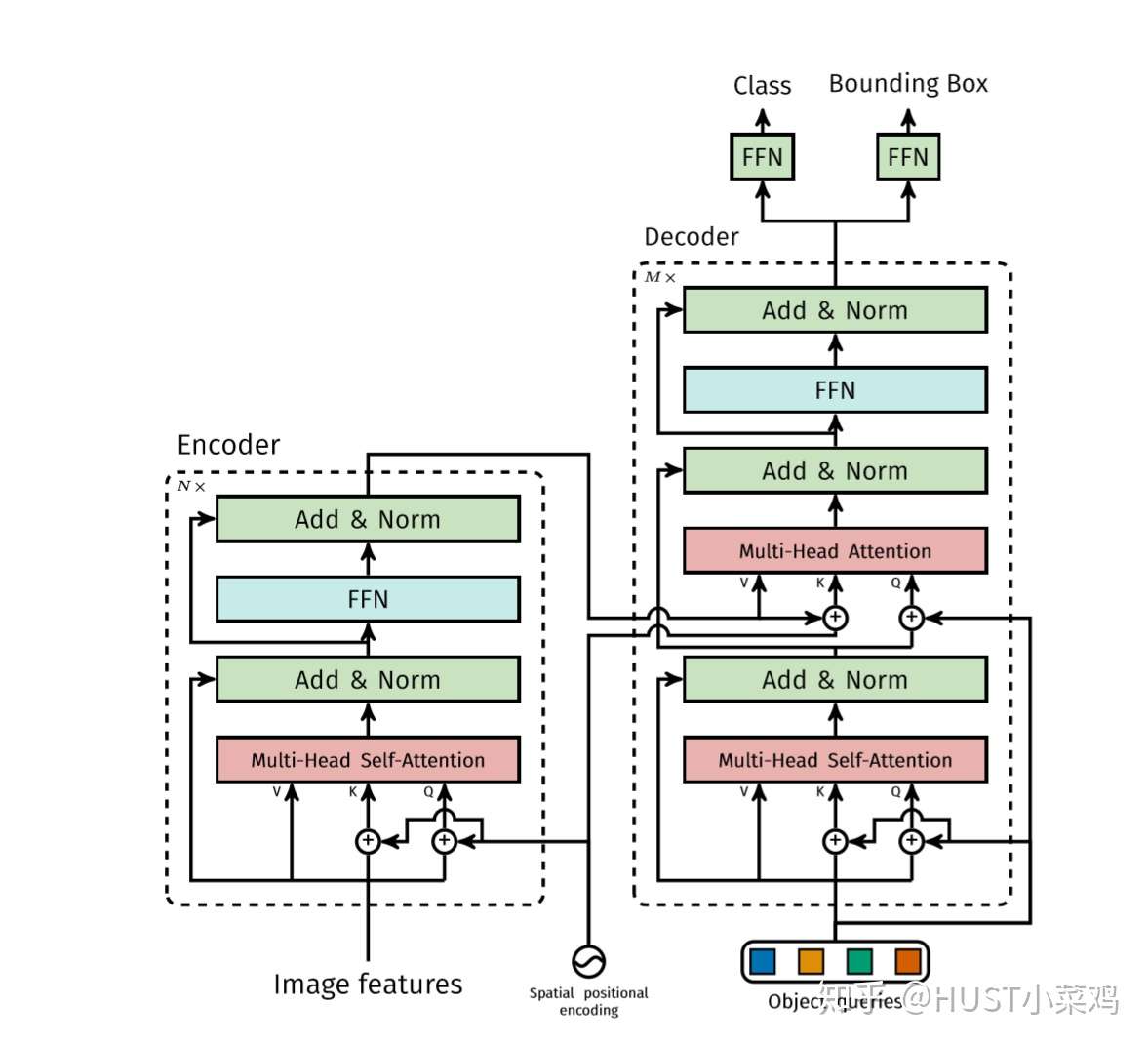
Transformer encoder部分首先将输入的特征图降维并flatten,然后送入下图左半部分所示的结构中,和空间位置编码一起并行经过多个自注意力分支、正则化和FFN,得到一组长度为N的预测目标序列。其中,每个自注意力分支的工作原理为可参考刘岩:详解Transformer (Attention Is All You Need),也可以参照论文:https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
接着,将Transformer encoder得到的预测目标序列经过上图右半部分所示的Transformer decoder,并行的解码得到输出序列(而不是像机器翻译那样逐个元素输出)。和传统的autogreesive机制不同,每个层可以解码N个目标,由于解码器的位置不变性,即调换输入顺序结果不变,除了每个像素本身的信息,位置信息也很重要,所以这N个输入嵌入必须不同以产生不同的结果,所以学习NLP里面的方法,加入positional encoding并且每层都加,作者非常用力的在处理position的问题,在使用 transformer 处理图片类的输入的时候,一定要注意position的问题。
(3)预测头部(FFN)
使用共享参数的FFNs(由一个具有ReLU激活函数和d维隐藏层的3层感知器和一个线性投影层构成)独立解码为包含类别得分和预测框坐标的最终检测结果(N个),FFN预测框的标准化中心坐标,高度和宽度w.r.t. 输入图像,然后线性层使用softmax函数预测类标签。




2、模型的损失函数
基于序列预测的思想,作者将网络的预测结果看作一个长度为N的固定顺序序列 ,
,(其中N值固定,且远大于图中ground truth目标的数量)
,同时将ground truth也看作一个序列
(长度一定不足N,所以用
(表示无对象)对该序列进行填充,可理解为背景类别,使其长度等于N),其中
表示该目标所属真实类别,
表示为一个四元组(含目标框的中心点坐标和宽高,且均为相对图像的比例坐标)。
那么预测任务就可以看作是 之间的二分图匹配问题,采用匈牙利算法[1]作为二分匹配算法的求解方法,定义最小匹配的策略如下:
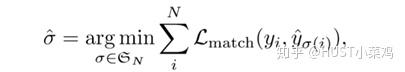
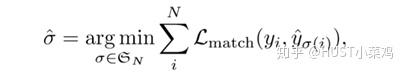
求出最小损失时的匹配策略 ,对于
同时考虑了类别预测损失即真实框之间的相似度预测。
对于 ,
的预测类别置信度为
,边界框预测为
,对于非空的匹配,定于
为:
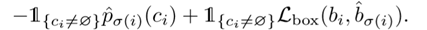
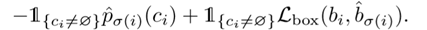
进而得出整体的损失:
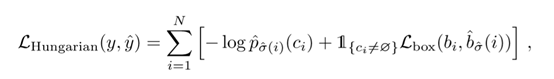
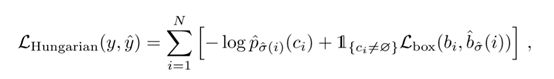
考虑到尺度的问题,将L1损失和iou损失线性组合,得出如下所示:
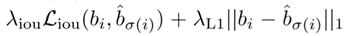
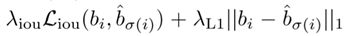
采用的是Generalized intersection over union论文提出的GIOU[2],关于GIOU后面会大致介绍。
为了展示DETR的扩展应用能力,作者还简单设计了一个基于DETR的全景分割框架,结构如下:
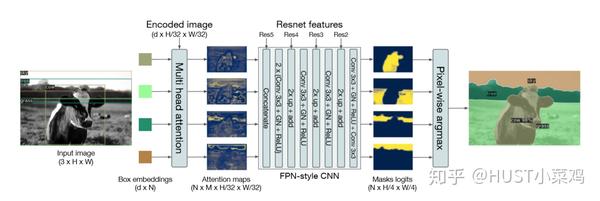
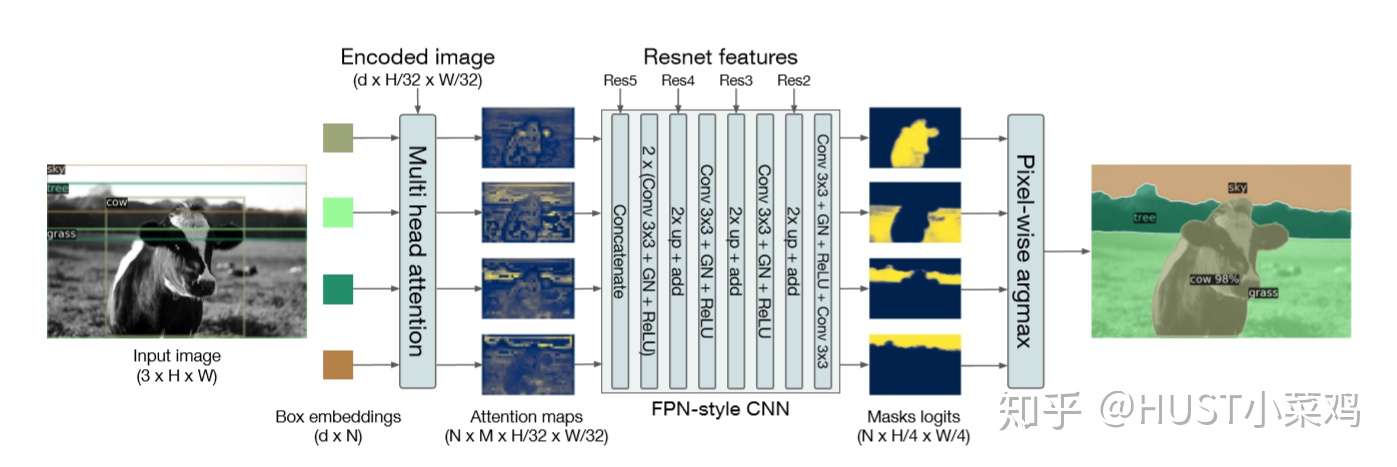
4、实验对比
本文中,作者主要和目标检测经典框架faster rcnn进行了对比,结果如下(其中带有后缀DC5的方法表示在主干网络的最后一个阶段加入一个dilation,并从这个阶段的第一个卷积中去除一个stride来增加特征分辨率):
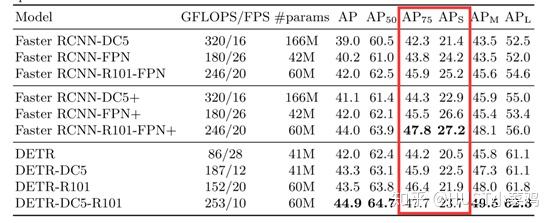
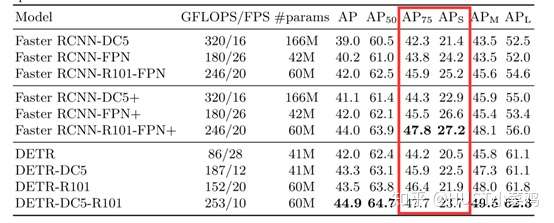
由上图可知,DETR框架虽然简洁,但效果与经典方法faster rcnn不相上下,其中DETR对于大目标的检测效果有所提升,但在小目标的检测中表现较差。该文提出的方法十分新颖,使用类似机器翻译的序列预测思想,打破了目标检测的传统思想,减少检测器对先验性息和后处理的依赖,使目标检测框架更加简洁的同时获得了与faster rcnn相媲美的效果。
该方法的不足表现在训练阶段,需要的时间和硬件资源需求较大,因此训练的难度还是挺大的


附录:GIOU


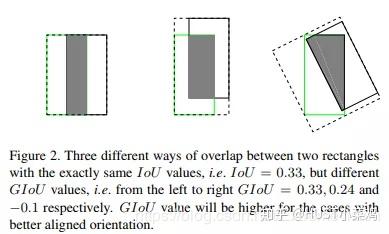
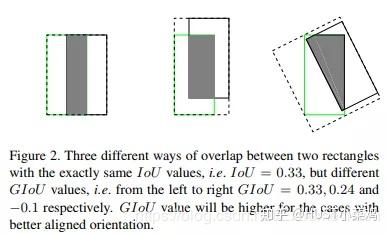
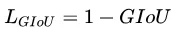
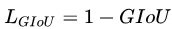
- 与IoU相似,GIoU也是一种距离度量,作为损失函数的话,满足损失函数的基本要求
- GIoU对scale不敏感
- GIoU是IoU的下界,在两个框无线重合的情况下,IoU=GIoU
- IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。
- 与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









