







Transformer+Detection:引入视觉领域的首创DETR
也没有精力看原文了,直接看了博客:
这几天又仔细看了原版Transformer的解读,确实是跟CNN有区别,算是一种全新的层设计理念,顺着博客思路看到了End-to-End Object Detection with Transformers,博客里面将的很不错,下面是我对一些问题的看法。
1、位置编码的思路
个人理解,想要看懂位置编码,必须看懂原版Transformer,原版中位置编码就是为了解决单词前后顺序的问题,而单词是通过矩阵投影形成词嵌入的,因此为了附加上位置信息,也需要将one-hot编码的位置信息转变为位置嵌入,那么用的就是:
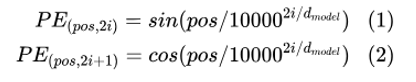
这里应该强调的是,位置编码需要满足:每一个位置的编码都是唯一的,长度无需固定,并且可以通过线性函数进行相对位置的计算,因此,从这个角度出发,位置编码函数里面的10000并非是唯一的,只要保证![]() 的周期不是2pi即可。
的周期不是2pi即可。
另外,pos是单词的序列号,而2i或2i+1是pos处位置编码的序号,其长度是与词嵌入的长度是一致的。
有了这两点,再来看DETR的位置编码。在这之前,先说一下CNN。DETR的CNN扮演的角色类似于词嵌入,将图像通过CNN变为(B,d,H,W),再通过拉平操作变为(HW,B,256),这里的B是bantch的意思,就是批,CNN里面的一批图片同时作为输入进行训练,HW就相当于词嵌入的维度(长度),256相当于是单词的数量。这样一来,位置编码的思路就清晰很多了,DETR的posx和posy实际上就是CNN输出的特征图的位置,这些特征图序列共256幅,每一幅的大小是H*W,每一幅特征图会对应一幅大小相同的位置编码图。这样CNN子特征图和位置编码图都拉平,再按元素相加,即实现了位置编码。这里其实没必要以10000为底,因为子特征图的大小一般不会太大,顶多几百像素,所以1000就足够了,不过也无可厚非,只要保证编码唯一就行。
这里的要点就是,不要把256当做是类似词嵌入的维度数,它是词嵌入的数量,这样便于和原版Transformer对应。

下面是做点笔记,划重点。
2 位置编码只应用于Query和Key
从逻辑上来讲,这是正确的,因为Q和K仅用于生成一个伪协方差矩阵,衡量着各个子特征图序列之间的相关性,而V就是为了存储特征值,因此V中不需要包含位置信息,位置信息应该仅存在于Q和K中,否则Q\K\V的功能就不明确了。
3 位置编码需要加入到每个Encoder layer中
是否是相当于强化这个空间位置?
4 Decoder的每一个Multi-head Self-attention的输入不一样
刚开始看就弄懵了,一个是hw行,一个是100行,这能做矩阵乘法吗?能。。。逼着我又看原文咯

这里统一省略batch的维度。先看DETR的结构图,包括2个Multi-head Self-attention。刚开始时,decoder的输入是一个初始化为全0的张量,形状是[100,256],原文中使用的符号是N和d,也就是说,N=100,d=256。这里有一个称作Object queries的可学习的张量,形状与输入输出一致。那么第一个Multi-head Self-attention的V就是全0张量,K和Q是全0张量+Object queries,第一个Multi-head Self-attention的输出的形状仍然是[100,256]。第二个Multi-head Self-attention的输入,对V来讲是Encoder的输出,形状是[HW,256],对K来讲是Encoder的输出+PE,对Q来讲是第一个Multi-head Self-attention的输出+Object queries,这样一来,看似形状就不统一了。但是我们发现,此时的Q是[100,256],K是[HW,256],那么Q*K^T的形状是[100,HW],softmax后再乘V,形状就是[100,HW]*[HW,256]=[100, 256],又与Object queries的形状一致了。看到这里,终于明白了。。然后这两个Multi-head Self-attention+FFN需要循环执行M次,那么第二次循环的输入就是第一次循环的输出再加上Object queries,这就OK了~~。
5 损失函数
使用双边匹配算法:

Lmatch: ![]()
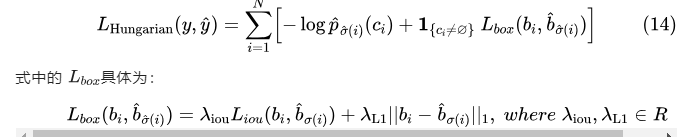
6 DETR的思想改变
就是将目标检测问题转化为一个直接集合预测问题,有效地消除了对许多手工设计的组件的需要,例如NMS或锚生成,这些组件其实是编码了我们关于任务的先验知识(物体边界框的先验尺寸)。这一点就像是解放了生产力一样,具有变革性影响。















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









