






引言
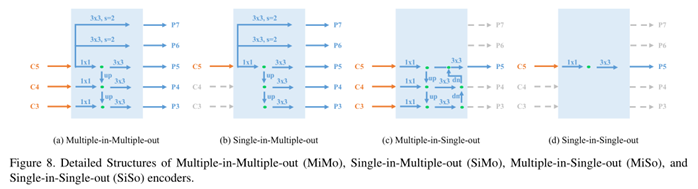
FPN带来了两个好处:(1)多尺度特征融合:融合多个低分辨率和高分辨率特征输入以获得更好的表示;(2)分而治之: 在不同层次上检测对象的尺度。本文研究了FPN的两个优点对单级探测器的影响。具体来说,作者认为FPN是一个多入多出(MiMo)编码器,它对主干的多尺度特征进行编码,并为解码器(检测头)提供特征表示。在多入多出(MiMo)、单入多出(SiMo) 、多入单出(MiSo) 、单入单出(SiSo)之间进行对照比较,如下图1:

可以发现,SIMO只用c5作为single输入的MAP,比MOMO用C5 C4 C3的输入的gap不到1;但MISO,只用p5输出的MAP,却比MIMO用p3~p7的差了很多。作者认为这种现象暗示了2种事实,(1)C5特征携带了足够的上下文来检测各种尺度上的对象,这使得SiMo编码器能够获得comparable结果;(2)多尺度特征融合的益处远没有分而治之的益处重要,因此多尺度特征融合可能不是FPN最显著的益处,这也由语义分割中的ExFuse(《Exfuse: Enhancing feature fusion for semantic segmentation》)证明。再深入一步思考,分而治之与对象检测中的优化问题有关。它通过目标尺度将复杂的检测问题分成若干个子问题,便于优化过程
上述分析表明,FPN成功的关键因素是它解决了目标检测中的优化问题。各个击破的解决方案是个好办法。但是它带来了内存负担,减慢了探测器的速度,并使探测器的结构在像RetinaNet这样的单级探测器中变得复杂。鉴于C5特性携带了足够的检测上下文,本文展示了一种解决优化问题的简单方法。
本文提出YOLOF,它只使用一个C5特征(下采样速率为32)进行检测。为了弥合SiSo编码器和MiMo编码器之间的性能差距,首先适当地设计编码器的结构,以提取各种尺度上的对象的多尺度上下文,补偿多层次特征的缺乏;然后,应用统一匹配机制来解决单个特征中稀疏锚引起的positive anchors不平衡问题。
相关工作
Multiple-level feature detectors:采用多种特征进行目标检测是一种常规技术。构建多个特征的典型方法可以分为图像金字塔方法和特征金字塔方法。基于图像金字塔的检测器,如DPM,在深度学习前的时代主导着检测。然而,图像金字塔方法不是获得多个特征的唯一方法,SSD首先利用多尺度特征,并针对不同尺度的对象在每个尺度上执行对象检测。FPN遵循SSD和UNet,通过结合浅层特征和深层特征构建语义丰富的特征金字塔。之后,FPN成为一个重要的组成部分,主导着现代探测器。它也适用于流行的单级探测器
Single-level feature detectors: 在早期,R-CNN系列和R-FCN只提取单个特征的感兴趣区域特征,而它们的性能落后于多特征(《Feature pyramid networks for object detection》)。此外,在单级检测器中,YOLO和YOLOv2仅使用主干的最后一个输出特性,它们牺牲了性能换来了速度,CornerNet和CenterNet在使用下采样速率为4的单个功能来检测所有对象时,可以获得有竞争力的结果。使用高分辨率的特征图进行检测会带来巨大的内存成本,DETR将transformer引入检测,并表明仅使用一个C5特征就可以获得最先进的结果。
MiMo编码器的成本分析
FPN在密集目标检测方面的成功是由于它对优化问题的解决。然而,多级特征范式不可避免地会使检测器变得复杂,带来内存负担,并降低检测器的速度。在这一部分,本文提供了MiMo编码器成本的定量研究。基于RetinaNet,用ResNet-50设计实验,将检测任务的管道格式化为三个关键部分的组合: backbone、encoder和decoder,如图2所示:

如图3所示,表示MIMO,SISMO的channel分别为512,256时的backbone,encoder,decoder以及speed(GFLOPS和FPS),MIMO encoder的内存开销巨大(134G vs. 6G),并且MIMO运行速度相对与SIMO更慢(13 FPS vs. 34 FPS)。

方法
在目标检测中,识别不同尺度的物体是一个基本的挑战。应对这一挑战的一个可行的解决方案是利用多级特征,在具有MiMo或SiMo编码器的检测器中,它们利用不同的感受野(P3-P7)构建多级特征,并利用与其尺度匹配的感受野检测该级上的物体。

如图4(a)所示,C5特征的感受野只能覆盖有限的尺度范围,如果对象的尺度与感受野不匹配,就会导致较差的性能。在图4(b)中,与图4(a)中的情况相比,整个标度范围移动到更大的标度。然后,通过添加相应的特征来组合原始尺度范围和放大的尺度范围,从而产生具有覆盖所有对象尺度的多个感受野的输出特征(图4©)。
基于以上设计,本文提出了SiSo编码器,命名为Dilated Encoder。如图5所示,它包含两个主要组件: Projector和Residual Blocks。Projector层首先应用一个1×1卷积层来降低通道维数,然后添加一个3×3卷积层来细化语义上下文,这与FPN中的相同。然后,在3×3卷积层中叠加4个具有不同dilation rates的Residual Blocks,生成具有多个感受野的输出特征,覆盖所有对象的尺度。

positive anchor的定义对于目标检测中的优化问题至关重要。在基于anchor的检测器中,定义阳性的策略主要是通过测量anchor和ground-truth box的IoU。如果最大IoU大于阈值0.5,该anchor将被设置为阳性。这种方法被称为Max-IoU匹配。
在MiMo编码器中,anchor是以密集的方式在多个级别上预定义的,而在与其尺度相对应的特征级别上生成positive anchor。给定分而治之的机制,Max-IoU匹配使每个标度中的ground-truth box能够生成足够数量的positive anchor。然而,当采用SiSo编码器时,anchor的数量与MiMo编码器相比大幅减少,从100k到5k,导致锚稀疏。稀疏锚在应用Max-IoU匹配时会给检测器带来匹配问题,如图6所示。

一般情况下,大的ground-truth box会比小的ground-truth box感应更多的positive anchor,这导致positive anchor不平衡问题。这种不平衡使得检测器在训练时更注意到大物体而忽略了小物体,为了解决这种不平衡问题,本文提出了一种统一匹配策略:采用k个最近的anchor作为每个ground-truth box的positive anchor,这确保了所有ground-truth box以与相同数量的positive anchor统一匹配,而不管它们的大小如何。
在上述解决方案的基础上,本文提出了一个快速而简单的框架,具有单级特性,称为YOLOF。
Backbone.:简单地采用ResNet和ResNeXt系列作为主干网络。模型都是在ImageNet上预先训练好的。主干的输出是C5特征图,它有2048个通道,下采样速率为32。为了与其他检测器进行公平的比较,主干中的所有batchnorm层默认都是冻结的。
Encoder:首先应用一个1×1卷积层来降低通道维数,然后添加一个3×3卷积层来细化语义上下文,这与FPN中的相同;为了使编码器的输出特征能够覆盖不同尺度上的所有对象,添加由三个连续卷积组成的剩余块:第一个1×1卷积以4的缩减率应用信道缩减,然后使用具有膨胀的3×3卷积来扩大感受野,最后,1×1卷积来恢复信道数量。
Decoder:采用了RetinaNet的主要设计,它由两个并行的特定任务头组成:分类头和回归头,本文只增加两个小的修改。第一个是我们遵循DETR中FFN的设计,使两个头的卷积层数不同。回归头上有四个卷积,后面是批次归一化层和ReLU层,而分类头上只有两个。第二个是遵循Autoassign,并为回归头上的每个anchor添加隐式对象预测(非直接监督)。
Other Details:本文在图像上添加了随机移位操作来规避这个问题。该操作在左、右、顶和底方向随机移动图像,最多32个像素,目的是在图像中对象的位置注入噪声,增加ground-truth与高质量anchor匹配的概率。此外,本文发现当使用单级特征时,对anchor的中心偏移的限制也有助于最终的分类。
实验
本文在COCO基准上评估的YOLOF,并与RetinaNet和DETR进行比较。然后,对每个部件的设计进行详细的消融研究,并给出定量结果和分析。最后,为了给单级检测的进一步研究提供见解,本文提供了误差分析并展示了YOLOF与DETR相比的弱点。
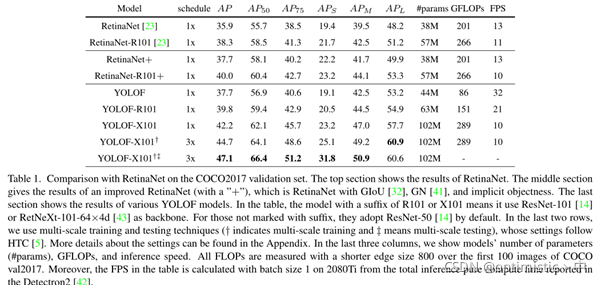
与RetinaNet的比较:
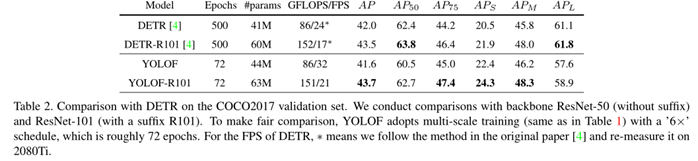
与DETR的比较:

与YOLOv4的比较:

消融实验:

误差分析:

细节展示:

附加实验结果

总结
本文回顾了用于一阶段检测器的特征金字塔网络(FPN),并指出FPN的成功在于其对目标优化问题的分治解决方案,而不是多尺度特征融合。因此本文从优化的角度来看,仅使用一层特征进行检测,而不是采用复杂的特征金字塔,该方法主要有两个重要部分:
①Dilated Encoder。它包含两个主要组件: Projector和Residual Blocks。Projector层首先应用一个1×1卷积层来降低通道维数,然后添加一个3×3卷积层来细化语义上下文,这与FPN中的相同。然后,在3×3卷积层中叠加4个具有不同dilation rates的Residual Blocks,生成具有多个感受野的输出特征,覆盖所有对象的尺度。
②Uniform Matching。采用k个最近的anchor作为每个ground-truth box的positive anchor,这确保了所有ground-truth box以与相同数量的positive anchor统一匹配,而不管它们的大小如何。
其中本文还提到:扩张卷积(《Multi-scale context aggregation by dilated convolutions.》)是在目标检测中扩大特征感受野的常用策略。














 2233
2233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









