







摘要
此篇博客主要介绍了MFEA理论推导及其改进算法MFEA-II。在多任务优化的情景下,如果任务之间存在潜在关系,那么高质量的解在这些任务之间的转移可以显著提高算法的性能。然而有的时候缺乏关于任务间协同作用的任何先验知识(黑盒优化),主要是负迁移导致算法的性能受损,因此负向任务间交互的易感性会阻碍整体的收敛行为。为了减轻这种负迁移的情况,MFEA-II在MFEA-I的基础上利用在线学习以及不同任务在多任务设置中的相似性(和差异)增强了优化进程。此算法具有原则性的理论分析,其试图让任务之间有害交互的趋势最小化。本博客首先阐述了进化多任务优化的背景,然后介绍了分布估计算法收敛性的理论分析,其次介绍了Kavitesh Kumar Bali等人利用理论分析结果设计了新的算法MFEA-II。
一.背景
首先阐述一下迁移学习和多任务学习的区别。迁移学习利用来自各种源任务的可用数据池来提高相关目标任务的学习效率。例如目前有一个任务B是分辨出一张图片里面是否有猫,假设我们之前做过一个任务A是分辨出一张图片里面是否有狗,那么我们可以利用任务A的数据提高任务B的学习效率,具体来说假设我们任务A的学习模型是一个深度卷积神经网络,此时我们任务两个分类任务很大程度上是相关的,因此我们可以直接将A模型拿来当做B的学习模型,并且可以直接利用A模型的参数,这样可以提高B任务的学习效率。迁移学习主要针对的是目标任务,而多任务学习则是通过在不同任务之间共享信息,同时学习所有任务,以提高整体泛化性能。具体来说,多任务优化的目的是通过促进全方位的知识转移,实现更大的协同搜索,从而促进多个问题的同时高效解决。
之前大多数的多任务学习主要用于回归和预测等领域,而从多任务贝叶斯优化[1]开始,越来越多的学者才在优化领域里开始研究知识迁移。多任务贝叶斯优化是支持自动机器学习超参数优化的一个突出进展。利用多任务高斯过程模型自适应学习任务间依赖关系,改进了贝叶斯优化算法的整体搜索,取得了较好的效果。然而,贝叶斯优化通常局限于相当低或中等维数的问题。这是因为,随着搜索空间维数的增加,保证良好的空间覆盖率(用于学习精确的高斯过程模型)所需的数据点数量呈指数级增长(通常称为冷启动问题)。此外,贝叶斯优化的应用主要局限于连续搜索空间,不直接应用于组合搜索空间,其中不定核可能难以处理。相比之下,进化算法(EAs)在填补这些空白方面一直很有前景。EAs在适应不同的数据表示(无论是连续还是组合)方面提供了巨大的灵活性,并且可以很好地扩展到更高的维度。因此产生了很多多任务进化优化算法,并解决了许多实际问题以及理论问题。但由于缺乏任务间的协同作用,负迁移会导致算法性能受损,因此MFEA-II考虑到这一点,使用数据驱动的在线学习潜在的相似性问题。
二.多任务贝叶斯优化
高斯过程(GPs)是一个用于指定函数
f
:
χ
→
R
f:\chi \rightarrow \mathbb{R}
f:χ→R上先验分布的一个灵活分类模型。它们由N个点的任意有限集合
X
=
{
x
n
∈
χ
}
n
=
1
N
X=\left \{ x_n\in \chi \right \}^N_{n=1}
X={xn∈χ}n=1N导出一个
R
N
\mathbb{R}^N
RN高斯分布。高斯过程由一个均值函数
m
:
χ
→
R
m:\chi\rightarrow \mathbb{R}
m:χ→R,一个正定协方差矩阵或者内核函数
K
:
χ
⋅
χ
→
R
K:\chi \cdot \chi\rightarrow\mathbb{R}
K:χ⋅χ→R指定。预测值和方差可以表示如下:
μ
(
x
;
{
x
n
,
y
n
}
,
θ
)
=
K
(
X
,
x
)
⊤
K
(
X
,
X
)
−
1
(
y
−
m
(
X
)
)
Σ
(
x
,
x
′
;
{
x
n
,
y
n
}
,
θ
)
=
K
(
x
,
x
′
)
−
K
(
X
,
x
)
⊤
K
(
X
,
X
)
−
1
K
(
X
,
x
′
)
\begin{aligned} \mu\left(\mathbf{x} ;\left\{\mathbf{x}_{n}, y_{n}\right\}, \theta\right) &=K(\mathbf{X}, \mathbf{x})^{\top} K(\mathbf{X}, \mathbf{X})^{-1}(\mathbf{y}-m(\mathbf{X})) \\ \Sigma\left(\mathbf{x}, \mathbf{x}^{\prime} ;\left\{\mathbf{x}_{n}, y_{n}\right\}, \theta\right) &=K\left(\mathbf{x}, \mathbf{x}^{\prime}\right)-K(\mathbf{X}, \mathbf{x})^{\top} K(\mathbf{X}, \mathbf{X})^{-1} K\left(\mathbf{X}, \mathbf{x}^{\prime}\right) \end{aligned}
μ(x;{xn,yn},θ)Σ(x,x′;{xn,yn},θ)=K(X,x)⊤K(X,X)−1(y−m(X))=K(x,x′)−K(X,x)⊤K(X,X)−1K(X,x′)
这里
K
(
X
,
x
)
K(X,x)
K(X,x)是一个x和X之间互协方差的N维列向量。N*N矩阵
K
(
X
,
X
)
K(X,X)
K(X,X)是集合X的Gram矩阵,即
K
(
x
1
,
x
2
,
…
,
x
k
)
=
(
(
x
1
,
x
1
)
(
x
1
,
x
2
)
…
(
x
1
,
x
k
)
(
x
2
,
x
1
)
(
x
2
,
x
2
)
…
(
x
2
,
x
k
)
⋯
⋯
⋯
…
(
x
k
,
x
1
)
(
x
k
,
x
2
)
…
(
x
k
,
x
k
)
)
K\left(x_{1}, x_{2}, \ldots, x_{k}\right)=\left(\begin{array}{cccc}{\left(x_{1}, x_{1}\right)} & {\left(x_{1}, x_{2}\right)} & {\dots} & {\left(x_{1}, x_{k}\right)} \\ {\left(x_{2}, x_{1}\right)} & {\left(x_{2}, x_{2}\right)} & {\ldots} & {\left(x_{2}, x_{k}\right)} \\ {\cdots} & {\cdots} & {\cdots} & {\ldots} \\ {\left(x_{k}, x_{1}\right)} & {\left(x_{k}, x_{2}\right)} & {\dots} & {\left(x_{k}, x_{k}\right)}\end{array}\right)
K(x1,x2,…,xk)=⎝⎜⎜⎛(x1,x1)(x2,x1)⋯(xk,x1)(x1,x2)(x2,x2)⋯(xk,x2)……⋯…(x1,xk)(x2,xk)…(xk,xk)⎠⎟⎟⎞
我们将高斯过程扩展到向量值函数的情况,例如
f
:
χ
→
R
T
f:\chi \rightarrow \mathbb{R}^T
f:χ→RT。可以将其解释为属于T个不同的回归任务。用高斯过程建模这类函数的关键是在两两任务之间定义一个有用的协方差函数
K
(
(
x
,
t
)
,
(
x
′
,
t
′
)
)
K\left((\mathrm{x}, t),\left(\mathrm{x}^{\prime}, t^{\prime}\right)\right)
K((x,t),(x′,t′))。一种简单的方法被称为共区域化的内在模型(intrinsic model of coregionalization),它转换一个潜在的函数来产生每个输出,即
K
multi
(
(
x
,
t
)
,
(
x
′
,
t
′
)
)
=
K
t
(
t
,
t
′
)
⊗
K
x
(
x
,
x
′
)
K_{\text { multi }}\left((\mathrm{x}, t),\left(\mathrm{x}^{\prime}, t^{\prime}\right)\right)=K_{\mathrm{t}}\left(t, t^{\prime}\right) \otimes K_{\mathrm{x}}\left(\mathrm{x}, \mathrm{x}^{\prime}\right)
K multi ((x,t),(x′,t′))=Kt(t,t′)⊗Kx(x,x′)
这里表示
⊗
\otimes
⊗克罗内克乘积,
K
x
K_{\mathrm{x}}
Kx度量输入之间的关系,
K
t
K_{t}
Kt度量任务之间的关系。给定
K
multi
K_{\text { multi }}
K multi ,这只是一个标准的GP。因此,在观测的总数仍然是立方增长的。
贝叶斯优化是一种用于全局优化噪声、代价昂贵的黑盒函数的通用框架。该方法可以使用相对廉价的概率模型去代理财务、计算或物理上昂贵的函数评价。贝叶斯规则用于推导给定观测值的真实函数的后验估计,然后使用代理确定下一个最有希望查询的点。一种常见的方法是使用GP定义从输入空间到希望最小化损失的目标函数的分布。也就是说,给定形式的观察序列对: { x n , y n } n = 1 N \left \{ x_n,y_n \right \}^N_{n=1} {xn,yn}n=1N,这里 x n ∈ χ , y n ∈ R x_n\in \chi,y_n\in \mathbb{R} xn∈χ,yn∈R,我们假设f(x)用一个高斯过程来刻画,这里 y n ∼ N ( f ( x n ) , v ) y_n\sim N(f(x_n),v) yn∼N(f(xn),v)并且 v v v是一个函数观测的噪声误差。
一种标准的方法是通过查找函数
a
(
x
;
{
x
n
,
y
n
}
,
θ
)
a(x;\left \{x_n,y_n\right\},\theta)
a(x;{xn,yn},θ)在定义域
χ
\chi
χ上的最大值来选择下一个点。期望改进标准(EI):
a
E
I
(
x
;
{
x
n
,
y
n
}
,
θ
)
=
∑
(
x
,
x
;
{
x
n
,
y
n
}
,
θ
)
(
γ
(
x
)
Φ
(
γ
(
x
)
)
+
N
(
γ
(
x
)
;
0
,
1
)
)
a_{EI}(x;\left\{ x_n,y_n \right\},\theta)=\sqrt{\sum(x,x;\left\{ x_n,y_n \right\},\theta)}(\gamma(x)\Phi(\gamma(x))+N(\gamma(x);0,1))
aEI(x;{xn,yn},θ)=∑(x,x;{xn,yn},θ)(γ(x)Φ(γ(x))+N(γ(x);0,1))
γ ( x ) = y b e s t − μ ( x ; { x n , y n } , θ ) ∑ ( x , x ; { x n , y n } , θ ) \gamma(x)=\frac{y_{best}-\mu(x;\left\{x_n,y_n\right\},\theta)}{\sqrt{\sum(x,x;\left\{x_n,y_n\right\},\theta)}} γ(x)=∑(x,x;{xn,yn},θ)ybest−μ(x;{xn,yn},θ)
这里 Φ ( ⋅ ) \Phi(\cdot) Φ(⋅)为标准正太的累积分布函数, γ ( x ) \gamma(\mathbf{x}) γ(x)是一个分数。由于其形式简单,EI可以使用标准的黑盒优化算法进行局部优化。
与启发式获取函数(如EI)相比,另一种方法是考虑函数的最小值上的分布,并迭代地评估最能降低该分布熵的点。这种熵搜索策略[18]对降低优化过程中最小值位置的不确定性有很好的解释。在这里,我们将熵搜索问题表示为从预先指定的候选集中选择下一个点。设置一个C个点的集合
X
~
⊂
X
\tilde{\mathbf{X}} \subset \mathcal{X}
X~⊂X,我们可以写出一个在
X
~
\tilde{\mathbf{X}}
X~中函数值最小的点
x
∈
X
~
\mathrm{x} \in \tilde{\mathrm{X}}
x∈X~的概率:
Pr
(
min
at
∣
θ
,
X
~
,
{
x
n
,
y
n
}
n
=
1
N
)
=
∫
R
C
p
(
f
∣
x
,
θ
,
{
x
n
,
y
n
}
n
=
1
N
)
∏
x
~
∈
X
~
\
x
h
(
f
(
x
~
)
−
f
(
x
)
)
d
f
\operatorname{Pr}\left(\min \text { at } | \theta, \tilde{\mathbf{X}},\left\{\mathbf{x}_{n}, y_{n}\right\}_{n=1}^{N}\right)=\int_{\mathbb{R}^{C}} p\left(\mathbf{f} | \mathbf{x}, \theta,\left\{\mathbf{x}_{n}, y_{n}\right\}_{n=1}^{N}\right) \prod_{\tilde{\mathbf{x}} \in \tilde{\mathbf{X}} \backslash \mathbf{x}} h(f(\tilde{\mathbf{x}})-f(\mathrm{x})) \mathrm{d} \mathbf{f}
Pr(min at ∣θ,X~,{xn,yn}n=1N)=∫RCp(f∣x,θ,{xn,yn}n=1N)x~∈X~\x∏h(f(x~)−f(x))df
这里
f
\mathbf{f}
f是点
X
~
\tilde{\mathbf{X}}
X~的函数值向量,
h
h
h是Heaviside阶跃函数。如果在x上的y 值被揭示,熵搜索过程依赖于对该分布的不确定性减少的估计。进行以下定义:
Pr
(
min
at
x
∣
θ
,
X
~
,
{
x
n
,
y
n
}
n
=
1
N
)
\operatorname{Pr}\left(\min \text { at } x | \theta, \tilde{\mathbf{X}},\left\{\mathbf{x}_{n}, y_{n}\right\}_{n=1}^{N}\right)
Pr(min at x∣θ,X~,{xn,yn}n=1N) as
P
m
i
n
\mathrm{P}_{\mathrm{min}}
Pmin,
p
(
f
∣
x
,
θ
,
{
x
n
,
y
n
}
n
=
1
N
)
p\left(\mathbf{f} | \mathbf{x}, \theta,\left\{\mathbf{x}_{n}, y_{n}\right\}_{n=1}^{N}\right)
p(f∣x,θ,{xn,yn}n=1N) as
p
(
f
∣
x
)
p(\mathbf{f} | \mathbf{x})
p(f∣x),高斯过程(GP)似然函数为
p
(
y
∣
f
)
p(y | \mathrm{f})
p(y∣f)。定义P的熵为
H
(
P
)
H(\mathbf{P})
H(P)。目标是从一组候选点中找出x点,使信息增益在最小位置分布上最大化,
a
K
L
(
x
)
=
∬
[
H
(
P
min
)
−
H
(
P
min
y
)
]
p
(
y
∣
f
)
p
(
f
∣
x
)
d
y
d
f
a_{\mathrm{KL}}(\mathrm{x})=\iint\left[H\left(\mathrm{P}_{\min }\right)-H\left(\mathrm{P}_{\min }^{y}\right)\right] p(y | \mathrm{f}) p(\mathrm{f} | \mathrm{x}) \mathrm{d} y \mathrm{df}
aKL(x)=∬[H(Pmin)−H(Pminy)]p(y∣f)p(f∣x)dydf
这里
P
m
i
n
y
\mathrm{P}_{\mathrm{min}}^{y}
Pminy表明幻想观测
{
x
,
y
}
\{x, y\}
{x,y}已经添加到观察集里。虽然上式没有一个简单的形式,但是我们可以用蒙特卡罗方法通过采样f来近似它。这个公式的另一种替代方法是考虑相对于均匀基分布的熵的减少,但是我们发现公式(7)在实际中工作得更好。
在多任务GPs框架下,对相关任务进行优化是相当直接的。我们只是把未来的观察限制在感兴趣的任务上,然后像往常一样继续下去。一旦我们对感兴趣的任务有了足够的观察,就可以进行适当的估计
K
t
K_{t}
Kt,然后其他任务将作为额外的观察,不需要任何额外的功能评估。图1给出了多任务GP与单任务GP的对比及其对EI的影响。
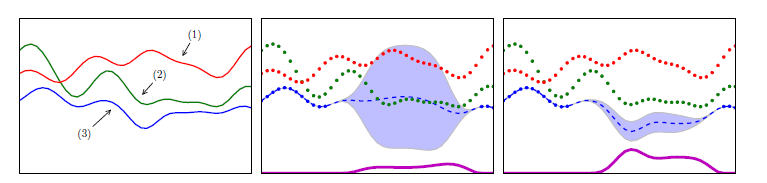
图1 (a)一个包含来自多任务GP的三个任务的示例函数。任务2和任务3是相关的,任务1和任务3是反相关的,任务1和任务2是不相关的。(b)独立的。©第三个任务的多任务预测。点表示观察值,虚线表示预测平均值。这里我们展示了三个任务和相应的观察值,目标是最小化第三个任务。底部显示的曲线代表了该任务上每个输入位置的预期改进。独立的GP不能很好地表达函数,优化EI会导致错误的评价。多任务GP利用其他任务,最大EI点对应于真实的最小化。
在这里,我们将考虑在多个任务上优化平均函数。这包含了单任务和多任务设置的元素,因为我们有一个表示多个任务上的联合函数的目标。我们通过考虑k-fold交叉验证上的更细化的贝叶斯优化来激活这种方法。我们希望优化所有k次折叠的平均性能,但是为了确定考虑中的超参数的质量,可能没有必要实际评估所有这些性能。平均目标的预测均值和方差为:
μ
‾
(
x
)
=
1
k
∑
t
=
1
k
μ
(
x
,
t
;
{
x
n
,
y
n
}
,
θ
)
,
σ
‾
(
x
)
2
=
1
k
2
∑
t
=
1
k
∑
t
′
=
1
k
Σ
(
x
,
x
,
t
,
t
′
;
{
x
n
,
y
n
}
,
θ
)
\overline{\mu}(\mathrm{x})=\frac{1}{k} \sum_{t=1}^{k} \mu\left(\mathrm{x}, t ;\left\{\mathrm{x}_{n}, y_{n}\right\}, \theta\right), \quad \overline{\sigma}(\mathrm{x})^{2}=\frac{1}{k^{2}} \sum_{t=1}^{k} \sum_{t^{\prime}=1}^{k} \Sigma\left(\mathrm{x}, \mathrm{x}, t, t^{\prime} ;\left\{\mathrm{x}_{n}, y_{n}\right\}, \theta\right)
μ(x)=k1t=1∑kμ(x,t;{xn,yn},θ),σ(x)2=k21t=1∑kt′=1∑kΣ(x,x,t,t′;{xn,yn},θ)
如果我们愿意为我们查询的每个点x花费一个函数评估,那么这个目标的优化可以使用标准方法进行。然而,在许多情况下,这可能是昂贵的,甚至可能是浪费。作为一个极端的例子,如果我们有两个完全相关的任务,那么每个查询花费两个函数计算不会提供额外的信息,其代价是单任务优化的两倍。更有趣的情况是,尝试联合选择x和任务t,并且每个查询只花费一个函数评估。
我们选择 a ( x , t ) \mathrm{a}(\mathrm{x}, t) a(x,t)使用两步启发式配对。首先,我们利用预测方法估算缺失的观测值。然后利用估计平均函数选择一个有希望的候选x对EI进行优化。以x为条件,然后我们选择产生最高的单任务预期改进的任务。
有一种研究多任务平均误差最小化的方法是应用贝叶斯优化来优化多个数据集上的单个模型。他们的方法是将每个函数投射到一个联合的潜在空间中,然后依次迭代地访问每个数据集。
与其从一个已经完成的相关任务的搜索中转移知识来引导一个新的任务,更可取的策略是让优化例程动态地查询相关的任务,这可能会大大降低成本。直观地说,如果两个任务紧密相关,那么评估一个更便宜的任务可以揭示信息,并减少关于更昂贵任务上最小值位置的不确定性。例如,一个聪明的策略可以在冒险评估一个昂贵的任务之前,对一个有希望的位置进行低成本的探索。在本节中,我们为这种动态多任务策略开发了一个获取函数,该函数特别考虑了基于熵搜索策略的噪声估计成本。虽然EI准则在单个任务用例中是直观有效的,但它不能直接推广到多任务用例中。然而,熵搜索可以很自然地转化为多任务问题。在这种情况下,我们有来自多个任务的观察对
{
x
n
t
,
y
n
t
}
n
=
1
N
\left\{\mathrm{x}_{n}^{t}, y_{n}^{t}\right\}_{n=1}^{N}
{xnt,ynt}n=1N并且选择一个候选的
x
t
\mathbf{x}^{t}
xt,它最大程度地降低了主要任务的
P
m
i
n
\mathrm{P}_{\mathrm{min}}
Pmin的熵,这里我们设置
t
=
1
t=1
t=1。对于
x
t
>
1
x^{t>1}
xt>1而言,
P
m
i
n
\mathrm{P}_{\mathrm{min}}
Pmin评估为0。然而对于
y
t
>
1
y^{t>1}
yt>1,我们可以评估
P
m
i
n
y
\mathrm{P}_{\mathrm{min}}^{y}
Pminy,并且如果辅助任务与主任务相关,
P
m
i
n
y
\mathrm{P}_{\mathrm{min}}^{y}
Pminy会改变基本分布并且
H
(
P
min
)
−
H
(
P
min
y
)
H\left(\mathrm{P}_{\min }\right)-H\left(\mathrm{P}_{\min }^{y}\right)
H(Pmin)−H(Pminy)是正的。降低f的不确定性,对相关辅助任务的观测值进行评价可以降低
P
m
i
n
P_{min}
Pmin对感兴趣的主要任务的熵。但是,请注意,在相关任务上评估一个点永远不会比在感兴趣的任务上评估相同的点揭示更多的信息。因此,上述策略永远不会选择评估相关的任务。然而,当考虑到成本时,辅助任务每单位成本可能传递更多的信息。因此,我们将目标由式(6)转化为反映评价候选点的单位成本信息增益:
a
I
G
(
x
t
)
=
∬
(
H
[
P
min
]
−
H
[
P
min
y
]
c
t
(
x
)
)
p
(
y
∣
f
)
p
(
f
∣
x
t
)
d
y
d
f
a_{\mathrm{IG}}\left(\mathrm{x}^{t}\right)=\iint\left(\frac{H\left[\mathrm{P}_{\min }\right]-H\left[\mathrm{P}_{\min }^{y}\right]}{c_{t}(\mathrm{x})}\right) p(y | \mathrm{f}) p\left(\mathrm{f} | \mathrm{x}^{t}\right) \mathrm{d} y \mathrm{df}
aIG(xt)=∬(ct(x)H[Pmin]−H[Pminy])p(y∣f)p(f∣xt)dydf
这里
c
t
(
x
)
,
c
t
:
X
→
R
+
c_{t}(\mathrm{x}), c_{t} : \mathcal{X} \rightarrow \mathbb{R}^{+}
ct(x),ct:X→R+为计算任务t在x处的实值成本,虽然我们事先不知道这个成本函数,但是我们可以用类似于任务函数的方法来估计它,
f
(
x
t
)
f\left(\mathbf{x}^{t}\right)
f(xt)*:*使用相同的多任务GP机制对
log
c
t
(
x
)
\log c_{t}(\mathrm{x})
logct(x)进行建模。

图2:一个可视化的多任务信息增益每单位成本的获取函数。在每个图中,目标是求出实蓝色函数的最小值。绿色函数是辅助目标函数。在每个图的底部都有一些线,表示关于主要目标函数的预期信息增益。绿色虚线表示通过评估辅助目标函数得到的关于主要目标的信息增益。图2a显示了来自GP的两个不相关的采样函数,评估主要目标可以获得信息,而评估辅助目标则不能。图2b我们看到,在两个强相关函数的作用下,对其中一个任务的观察不仅减少了对另一个任务的不确定性,而且来自辅助任务的观察获得了关于主任务的信息。最后,在2c中,我们假设主要目标的成本是辅助任务的三倍,因此评估相关任务在单位成本上获得了更多的信息收益。
图2使用两个任务示例提供了此获取函数的可视化。它展示了如何在相关辅助任务上选择一个点,以减少有关感兴趣的主要任务上的最小值位置的不确定性(蓝色实线)。在本文中,我们假设计算 a I G a_{\mathrm{IG}} aIG的所有候选点都来自一个固定子集。
三.多任务进化优化——MFEA系列
多任务进化优化顾名思义是利用进化算法去优化多个任务,Yew-Soon Ong等学者将其提出的MFEA建模成了分布估计算法,对其构造和采样了概率混合分布(结合来自不同任务的搜索分布)作为在多任务设置中初始化知识的交换方法。为了通过混合概率分布研究迁移的内部原理,其在之前的理论分析上又提出来新的算法MFEA-II。
3.1 混合模型概述
混合模型必须要求定义一个公共的搜索空间,因此下面先介绍一下统一搜索空间(unified search space)。
在多任务优化中,由于每个优化任务都有自己的搜索空间,因此我们必须建立一个统一的搜索空间以至于可以进行知识迁移。不是一般性,考虑同时求解K个最大化任务 { T 1 , T 2 , … , T K } \left\{T_{1}, T_{2}, \ldots, T_{K}\right\} {T1,T2,…,TK},每个任务对应的搜索维度为 D 1 , D 2 , … , D K D_{1}, D_{2}, \ldots, D_{K} D1,D2,…,DK,在这种情况下,我们可以定义一个维度为 D u n i f i e d = max { D 1 , D 2 , … , D K } D_{u n i f i e d}=\max \left\{D_{1}, D_{2}, \ldots, D_{K}\right\} Dunified=max{D1,D2,…,DK}的统一空间 X X X。这样定义主要有以下两点好处:第一,当同时使用多维搜索空间解决多个任务时,它有助于规避与维数诅咒相关的挑战。第二,它被认为是一种基于种群搜索的有效方法,可以促进有用的遗传物质的发现和从一个任务到另一个任务的隐性转移。这里 X X X的范围限制为 [ 0 , 1 ] D u n i f i e d [0,1] D_{u n i f i e d} [0,1]Dunified,它作为一个连续的统一空间,所有候选解都映射到其中(编码),对于各种离散/组合问题,可以设计不同的编码/解码过程。
接下来我们就可以正式定义混合模型的知识迁移啦!不失一般性的,我们定义
P
k
P^{k}
Pk为第k个子任务对应的子种群。定义
f
k
∗
=
f
k
(
x
∗
)
f_{k}^{*}=f_{k}\left(x^{*}\right)
fk∗=fk(x∗)为第k个任务的全局最大值。假设对于任务
T
k
T_k
Tk而言,x是
X
X
X中的候选解之一,那么定义以下假设:对于任意的
f
k
′
<
f
k
∗
f_{k}^{\prime}<f_{k}^{*}
fk′<fk∗,集合
H
=
{
x
∣
x
∈
X
,
f
k
(
x
)
>
f
k
′
}
H=\left\{x | x \in X, f_{k}(x)>f_{k}^{\prime}\right\}
H={x∣x∈X,fk(x)>fk′}的Borel measure是正的。在进化多任务算法里,我们可以将与每个任务相联系的子种群在一个时间步
t
>
0
t>0
t>0内源于的潜在概率分布定义为
p
1
(
x
,
t
)
,
p
2
(
x
,
t
)
,
…
,
p
K
(
x
,
t
)
p^{1}(x, t), p^{2}(x, t), \ldots, p^{K}(x, t)
p1(x,t),p2(x,t),…,pK(x,t)。因此,在促进任务间交互的过程中,第t次迭代时为第k个任务生成的后代种群被认为是从下面的混合分布中得到的
q
k
(
x
,
t
)
=
α
k
⋅
p
k
(
x
,
t
)
+
∑
j
≠
k
α
j
⋅
p
j
(
x
,
t
)
q^{k}(x, t)=\alpha_{k} \cdot p^{k}(x, t)+\sum_{j \neq k} \alpha_{j} \cdot p^{j}(x, t)
qk(x,t)=αk⋅pk(x,t)+j=k∑αj⋅pj(x,t)
有限的
q
k
(
x
,
t
)
q^{k}(x, t)
qk(x,t)是所有K个可用分布的线性组合,混合系数为
α
′
s
≥
0
\alpha^{\prime} s\geq 0
α′s≥0。其满足
α
k
+
∑
j
≠
k
α
j
=
1
\alpha_{k}+\sum_{j \neq k} \alpha_{j}=1
αk+∑j=kαj=1。
通过上述建模我们可以认为多任务进化优化中的知识转移是(9)中从混合概率分布里采样出来的候选点。混合的程度是由系数 α ′ s \alpha^{\prime} s α′s控制的,可想而知在缺乏对任务间关系的先验知识的情况下,混合概率分布有可能会错误地造成以负迁移。然而MFEA中并没有考虑,因此原作者在其基础上又提出了MFEA-II进行改进。以下我们还是先分析一下混合模型在多任务下的全局收敛性。主要是要证明基于概率建模的EAs的渐进全局收敛性保持不变。
为了便于数学推导,必须要假设每个子种群很大,即
N
→
∞
N \rightarrow \infty
N→∞。虽然其不符合实际,但它被认为是一种合理的简化。有这么条件,我们就可以通过Glivenko-Cantelli theorem(随着样本的增加,经验分布函数将随着样本的增加而收敛于其真实的分布函数)推得,子种群
P
k
P^{k}
Pk的经验概率密度更接近于真实的潜在分布
p
k
(
x
)
p^{k}(x)
pk(x)。假设初始化的所有子种群中,
p
k
(
x
,
t
=
0
)
p^{k}(x, t=0)
pk(x,t=0)是正的且连续。如果
lim
t
→
∞
E
[
f
k
(
x
)
]
=
lim
t
→
∞
∫
X
f
k
(
x
)
⋅
p
k
(
x
,
t
)
⋅
d
x
=
f
k
∗
,
∀
k
\lim _{t \rightarrow \infty} \mathbb{E}\left[f_{k}(x)\right]=\lim _{t \rightarrow \infty} \int_{X} f_{k}(x) \cdot p^{k}(x, t) \cdot d x=f_{k}^{*}, \forall k
limt→∞E[fk(x)]=limt→∞∫Xfk(x)⋅pk(x,t)⋅dx=fk∗,∀k,那么在多任务环境下每个子任务渐进收敛到全局最优。通俗点说就是随着优化过程的进行,种群分布必须逐渐集中在统一空间中与全局最优对应的点上。在进化多任务算法里,我们通常采用
(
μ
,
λ
)
(\mu, \lambda)
(μ,λ)的选择策略,即对于每个任务,从
λ
\lambda
λ中选择
μ
\mu
μ个个体(
μ
<
λ
\mu<\lambda
μ<λ)作为下一代的父代。那么选出来的父代定义为
P
c
k
P_{c}^{k}
Pck。首先,让我们定义一个参数
θ
=
μ
/
λ
,
0
<
θ
<
1
\theta=\mu / \lambda,0<\theta<1
θ=μ/λ,0<θ<1。那么在此选择方式下,混合概率分布为
p
k
(
x
,
t
+
1
)
=
{
q
k
(
x
,
t
)
θ
if
f
k
(
x
)
≥
β
k
(
t
+
1
)
0
otherwise
p^{k}(x, t+1)=\left\{\begin{array}{ll}{\frac{q^{k}(x, t)}{\theta}} & {\text { if } f_{k}(x) \geq \beta^{k}(t+1)} \\ {0} & {\text { otherwise }}\end{array}\right.
pk(x,t+1)={θqk(x,t)0 if fk(x)≥βk(t+1) otherwise
这里
β
k
(
t
+
1
)
\beta^{k}(t+1)
βk(t+1)是一个实数,其满足
∫
f
k
(
x
)
≥
β
k
(
t
+
1
)
q
k
(
x
,
t
)
⋅
d
x
=
θ
\int_{f_{k}(x) \geq \beta^{k}(t+1)} q^{k}(x, t) \cdot d x=\theta
∫fk(x)≥βk(t+1)qk(x,t)⋅dx=θ
那么给出以下定理。
定理1:假设对于所有的k, p k ( x , t = 0 ) p^{k}(x, t=0) pk(x,t=0)是正的且连续并且 N → ∞ N \rightarrow \infty N→∞。在多任务处理过程中,如果 α k > θ \alpha_{k}>\theta αk>θ,那么各任务渐近收敛到全局最优解。
证明:假设第k个任务对应的目标值集合为
F
k
(
t
)
F^{k}(t)
Fk(t)。那么集合最小值是
β
k
(
t
)
=
inf
F
k
(
t
)
\beta^{k}(t)=\inf F^{k}(t)
βk(t)=infFk(t)。换句话说
p
k
(
x
,
t
)
=
0
⇔
f
k
(
x
)
<
β
k
(
t
)
p^{k}(x, t)=0 \Leftrightarrow f_{k}(x)<\beta^{k}(t)
pk(x,t)=0⇔fk(x)<βk(t)
我们可以将原问题转化为证明
β
k
(
t
)
\beta^{k}(t)
βk(t)收敛即可。
β
k
(
t
)
<
β
k
(
t
+
1
)
\beta^{k}(t)<\beta^{k}(t+1)
βk(t)<βk(t+1)使人有一种直觉,即种群的扩散一定在缩小,逐渐扩大到统一空间中最有希望的区域。因此以下证明
β
k
(
t
)
<
β
k
(
t
+
1
)
\beta^{k}(t)<\beta^{k}(t+1)
βk(t)<βk(t+1)。
根据(9)式,得
∫
f
k
(
x
)
≥
β
k
(
t
)
q
k
(
x
,
t
)
⋅
d
x
≥
∫
f
k
(
x
)
≥
β
k
(
t
)
α
k
⋅
p
k
(
x
,
t
)
⋅
d
x
\int_{f_{k}(x) \geq \beta^{k}(t)} q^{k}(x, t) \cdot d x \geq \int_{f_{k}(x) \geq \beta^{k}(t)} \alpha_{k} \cdot p^{k}(x, t) \cdot d x
∫fk(x)≥βk(t)qk(x,t)⋅dx≥∫fk(x)≥βk(t)αk⋅pk(x,t)⋅dx
根据(12)可知
∫
f
k
(
x
)
≥
β
k
(
t
)
p
k
(
x
,
t
)
⋅
d
x
=
1
\int_{f_{k}(x) \geq \beta^{k}(t)} p^{k}(x, t) \cdot d x=1
∫fk(x)≥βk(t)pk(x,t)⋅dx=1,根据(13)得,
∫
f
k
(
x
)
≥
β
k
(
t
)
q
k
(
x
,
t
)
⋅
d
x
≥
α
k
\int_{f_{k}(x) \geq \beta^{k}(t)} q^{k}(x, t) \cdot d x \geq \alpha_{k}
∫fk(x)≥βk(t)qk(x,t)⋅dx≥αk
如果
α
k
>
θ
\alpha_{k}>\theta
αk>θ,根据(14)(11)得,
∫
f
k
(
x
)
≥
β
k
(
t
)
q
k
(
x
,
t
)
⋅
d
x
>
∫
f
k
(
x
)
≥
β
k
(
t
+
1
)
q
k
(
x
,
t
)
⋅
d
x
\int_{f_{k}(x) \geq \beta^{k}(t)} q^{k}(x, t) \cdot d x>\int_{f_{k}(x) \geq \beta^{k}(t+1)} q^{k}(x, t) \cdot d x
∫fk(x)≥βk(t)qk(x,t)⋅dx>∫fk(x)≥βk(t+1)qk(x,t)⋅dx
根据(15),由于左边比右边值大,因此易知,
β
k
(
t
)
<
β
k
(
t
+
1
)
\beta^{k}(t)<\beta^{k}(t+1)
βk(t)<βk(t+1)。又因为
β
k
\beta^{k}
βk不可能超过
f
k
∗
f_{k}^{*}
fk∗,那么意味着存在一个极限
lim
t
→
∞
β
k
(
t
)
=
f
k
′
\lim _{t \rightarrow \infty} \beta^{k}(t)=f_{k}^{\prime}
limt→∞βk(t)=fk′使得
f
k
′
≤
f
k
∗
f_{k}^{\prime} \leq f_{k}^{*}
fk′≤fk∗。因此以下利用反证法证明
f
k
′
=
f
k
∗
f_{k}^{\prime}=f_{k}^{*}
fk′=fk∗。即假设
f
k
′
<
f
k
∗
f_{k}^{\prime}<f_{k}^{*}
fk′<fk∗。根据公式(9)(10)得,
p
k
(
x
,
t
)
≥
p
k
(
x
,
0
)
[
α
k
θ
]
t
∀
x
:
f
k
(
x
)
>
f
k
′
p^{k}(x, t) \geq p^{k}(x, 0)\left[\frac{\alpha_{k}}{\theta}\right]^{t} \forall x : f_{k}(x)>f_{k}^{\prime}
pk(x,t)≥pk(x,0)[θαk]t∀x:fk(x)>fk′
令
H
=
{
x
∣
x
∈
X
,
f
k
(
x
)
>
f
k
′
}
H=\left\{x | x \in \boldsymbol{X}, f_{k}(x)>f_{k}^{\prime}\right\}
H={x∣x∈X,fk(x)>fk′},因为对所有的
x
∈
X
x \in \boldsymbol{X}
x∈X,
p
k
(
x
,
0
)
>
0
p^{k}(x, 0)>0
pk(x,0)>0并且
α
k
θ
>
1
\frac{\alpha_{k}}{\theta}>1
θαk>1,那么
lim
t
→
∞
p
k
(
x
,
t
)
=
+
∞
,
∀
x
∈
H
\lim _{t \rightarrow \infty} p^{k}(x, t)=+\infty, \forall x \in H
t→∞limpk(x,t)=+∞,∀x∈H
那么根据Fatou’s lemma可知,
lim
t
→
∞
∫
H
p
k
(
x
,
t
)
⋅
d
x
=
+
∞
\lim _{t \rightarrow \infty} \int_{H} p^{k}(x, t) \cdot d x=+\infty
t→∞lim∫Hpk(x,t)⋅dx=+∞
由于
p
k
(
x
,
t
)
p^{k}(x, t)
pk(x,t)是概率密度函数,求和应该为1,因此(18)矛盾,所以
f
k
′
=
f
k
∗
f_{k}^{\prime}=f_{k}^{*}
fk′=fk∗。即
lim
t
→
∞
β
k
(
t
)
=
f
k
∗
\lim _{t \rightarrow \infty} \beta^{k}(t)=f_{k}^{*}
t→∞limβk(t)=fk∗
3.2 MFEA的简介和理论分析
以上简要介绍了混合模型的基本知识,下面介绍一下MFEA并对其进行理论分析。MFEA事实上是一种基于交叉和变异的进化算法,那上面的混合模型岂不是白分析了?其实在相对强的以父为中心的进化算子约束下,基于交叉和变异的EAs算法与基于随机采样的优化算法有相似之处。其实就是以父代为中心的操作符倾向于使后代更接近父代,这种情况发生的概率更高。常见的例子包括模拟二进制交叉和多项式变异以及小方差的高斯变异等等。在这种情况下,父代和子代的经验密度分布认为相近是十分合理的。因此上面3.1的分析就可以直接拿过来分析MFEA了。
MFEA的基本思想就是使用一个种群P去解决K个优化子任务,每个任务都被视为影响种群进化的因素。与第k个任务关联的子种群表示为
P
k
P_k
Pk。对于每个个体而言,定义了技能因子为其擅长任务的编号,标量适应度定义为某个个体在所有与它具有相同技能因子的个体里函数值排名的倒数。MFEA的算法伪代码如下:

根据算法流程易知,MFEA中的知识转移程度由标为随机匹配概率(rmp)的标量(用户定义)参数控制。在MFEA的任意t代,种群 P ( t ) P(t) P(t)的概率密度函数 p ( x , t ) p(x, t) p(x,t)是K个概率密度函数 p k ( x , t ) p^{k}(x, t) pk(x,t)的混合。第K个概率密度函数对应第K个子种群 P k ( t ) ⊂ P ( t ) P^{k}(t) \subset P(t) Pk(t)⊂P(t)。*:*在进化算子的适当假设下, p c ( x , t ) ≈ p ( x , t ) p_{c}(x, t) \approx p(x, t) pc(x,t)≈p(x,t),任务之间的交叉分布 p c k ( x , t ) p_{c}^{k}(x, t) pck(x,t)不一定等于 p k ( x , t ) p^{k}(x, t) pk(x,t)。有以下定理:
定理2:在以父为中心的进化算子的假设下,在MFEA中第k个任务的子代混合分布
p
c
k
(
x
,
t
)
p_{c}^{k}(x, t)
pck(x,t)可以表示为
p
c
k
(
x
,
t
)
=
[
1
−
0.5
⋅
(
K
−
1
)
⋅
r
m
p
K
]
⋅
p
k
(
x
,
t
)
+
∑
j
≠
k
0.5
⋅
r
m
p
K
⋅
p
j
(
x
,
t
)
p_{c}^{k}(x, t)=\left[1-\frac{0.5 \cdot(K-1) \cdot r m p}{K}\right] \cdot p^{k}(x, t)+\sum_{j \neq k} \frac{0.5 \cdot r m p}{K} \cdot p^{j}(x, t)
pck(x,t)=[1−K0.5⋅(K−1)⋅rmp]⋅pk(x,t)+j=k∑K0.5⋅rmp⋅pj(x,t)
证明:让后代的解
x
a
x_a
xa被分配一个技能因子k,在以父为中心的进化算子的假设下,
x
a
x_a
xa是从
p
1
(
x
,
t
)
,
p
2
(
x
,
t
)
,
…
,
…
,
o
r
,
p
k
(
x
,
t
)
,
…
,
o
r
,
p
K
(
x
,
t
)
p^{1}(x, t), p^{2}(x, t), \ldots, \ldots, o r, p^{k}(x, t), \ldots, o r, p^{K}(x, t)
p1(x,t),p2(x,t),…,…,or,pk(x,t),…,or,pK(x,t)中得到的。有贝叶斯定理可得,
P
(
x
a
∼
p
k
(
x
,
t
)
∣
τ
a
=
k
)
=
P
(
τ
a
=
k
∣
x
a
∼
p
k
(
x
,
t
)
)
⋅
P
(
x
a
∼
p
k
(
x
,
t
)
)
P
(
τ
a
=
k
)
P\left(x_{a} \sim p^{k}(x, t) | \tau_{a}=k\right)=\frac{P\left(\tau_{a}=k | x_{a} \sim p^{k}(x, t)\right) \cdot P\left(x_{a} \sim p^{k}(x, t)\right)}{P\left(\tau_{a}=k\right)}
P(xa∼pk(x,t)∣τa=k)=P(τa=k)P(τa=k∣xa∼pk(x,t))⋅P(xa∼pk(x,t))
考虑在MFEA中统一分配资源给K个优化任务,我们有
P
(
x
a
∼
p
k
(
x
,
t
)
)
=
P
(
τ
a
=
k
)
=
1
K
P\left(x_{a} \sim p^{k}(x, t)\right)=P\left(\tau_{a}=k\right)=\frac{1}{K}
P(xa∼pk(x,t))=P(τa=k)=K1
根据上面两式得,
P
(
x
a
∼
p
k
(
x
,
t
)
∣
τ
a
=
k
)
=
P
(
τ
a
=
k
∣
x
a
∼
p
k
(
x
,
t
)
)
P\left(x_{a} \sim p^{k}(x, t) | \tau_{a}=k\right)=P\left(\tau_{a}=k | x_{a} \sim p^{k}(x, t)\right)
P(xa∼pk(x,t)∣τa=k)=P(τa=k∣xa∼pk(x,t))
根据算法流程,可以知道
P
(
τ
a
=
k
∣
x
a
∼
p
k
(
x
,
t
)
)
P\left(\tau_{a}=k | x_{a} \sim p^{k}(x, t)\right)
P(τa=k∣xa∼pk(x,t))有种3情况:
第一种情况,两个个个体具有相同的技能因子时,
x
a
x_a
xa子代继承同样的技能因子,概率为
P
(
Scenario
−
1
)
=
1
K
∗
1
=
1
K
P(\text {Scenario}-1)=\frac{1}{K}*1=\frac{1}{K}
P(Scenario−1)=K1∗1=K1
第二种情况,满足rmp要求,
x
a
x_a
xa子代继承其技能因子的概率为
P
(
Scenario
−
2
)
=
0.5
⋅
(
K
−
1
)
⋅
r
m
p
K
P(\text {Scenario}-2)=\frac{0.5 \cdot(K-1) \cdot r m p}{K}
P(Scenario−2)=K0.5⋅(K−1)⋅rmp
第三种情况,
x
a
x_a
xa是一个很小的变异,那么概率为
P
(
Scenario
−
3
)
=
(
K
−
1
)
⋅
(
1
−
r
m
p
)
K
P(\text {Scenario}-3)=\frac{(K-1) \cdot (1-r m p)}{K}
P(Scenario−3)=K(K−1)⋅(1−rmp)
那么
P
(
τ
a
=
k
∣
x
a
∼
p
k
(
x
,
t
)
)
=
∑
i
=
1
3
P
(
S
c
e
n
a
r
i
o
−
i
)
P\left(\tau_{a}=k | x_{a} \sim p^{k}(x, t)\right)=\sum_{i=1}^{3} P(S c e n a r i o-i)
P(τa=k∣xa∼pk(x,t))=i=1∑3P(Scenario−i)
因此
P
(
x
a
∼
p
k
(
x
,
t
)
∣
τ
a
=
k
)
=
1
−
0.5
⋅
(
K
−
1
)
⋅
r
m
p
K
P\left(x_{a} \sim p^{k}(x, t) | \tau_{a}=k\right)=1-\frac{0.5 \cdot(K-1) \cdot r m p}{K}
P(xa∼pk(x,t)∣τa=k)=1−K0.5⋅(K−1)⋅rmp
P ( x a ∼ p j ( x , t ) ∀ j ≠ k ∣ τ a = k ) = ∑ j ≠ k 0.5 ⋅ r m p K P\left(x_{a} \sim p^{j}(x, t) \forall j \neq k | \tau_{a}=k\right)=\sum_{j \neq k} \frac{0.5 \cdot r m p}{K} P(xa∼pj(x,t)∀j=k∣τa=k)=j=k∑K0.5⋅rmp
结合上面两式得
p
c
k
(
x
,
t
)
=
[
1
−
0.5
⋅
(
K
−
1
)
⋅
r
m
p
K
]
⋅
p
k
(
x
,
t
)
+
∑
j
≠
k
0.5
⋅
r
m
p
K
⋅
p
j
(
x
,
t
)
p_{c}^{k}(x, t)=\left[1-\frac{0.5 \cdot(K-1) \cdot r m p}{K}\right] \cdot p^{k}(x, t)+\sum_{j \neq k} \frac{0.5 \cdot r m p}{K} \cdot p^{j}(x, t)
pck(x,t)=[1−K0.5⋅(K−1)⋅rmp]⋅pk(x,t)+j=k∑K0.5⋅rmp⋅pj(x,t)
证毕。
定理3:在大种群的假设下( N → ∞ N \rightarrow \infty N→∞),如果 θ ( = μ / λ ) ≤ 0.5 \theta(=\mu / \lambda) \leq 0.5 θ(=μ/λ)≤0.5,使用以父为中心的交叉以及 ( μ , λ ) (\mu, \lambda) (μ,λ)选择机制,那么MFEA算法在所有任务上具有全局的收敛性。
证明:根据定理2可知, α k = 1 − 0.5 ⋅ ( K − 1 ) ⋅ r m p K \alpha_{k}=1-\frac{0.5 \cdot(K-1) \cdot r m p}{K} αk=1−K0.5⋅(K−1)⋅rmp。因为 0 ≤ r m p ≤ 1 0 \leq r m p \leq 1 0≤rmp≤1,所以 0.5 < α k ≤ 1 0.5<\alpha_{k} \leq 1 0.5<αk≤1。因此 α k > θ \alpha_{k}>\theta αk>θ。那么根据定理1得证。
从算法1可以看出,MFEA的性能依赖于rmp的选择。由于缺乏关于任务间关系的先验知识,因此需要调优适当的rmp。从本质上讲,不好的rmp可能会导致任务间的消极交互,或者潜在的知识交换损失。原作者还在文章里证明了在任务之间没有互补性的情况下,单任务可能比多任务处理具有更快的收敛速度,MFEA收敛速度的降低是依赖于rmp的。因此为了更好的探究算法里潜在的知识迁移,作者提出了一种在线rmp估计算法MFEA-II,从理论上保证最小化不同优化任务之间的负面(有害)交互。
3.3 MFEA-II的理论分析与算法介绍
从MFEA的收敛速度分析中,易推断多任务处理中的负迁移可以通过强制
p
c
k
(
x
,
t
)
p_{c}^{k}(x, t)
pck(x,t)和
p
k
(
x
,
t
)
p^{k}(x, t)
pk(x,t)越近越好。根据定理2可知,让rmp为0即可,但这样就没有信息迁移了,因此,主要目标是提出一个促进知识转移的策略(rmp > 0),同时减轻负面的任务间交互。为此原作者提出了一种新的基于数据驱动的在线学习方式来估计rmp的值,从而推断出一个最优的混合分布。这里rmp不再是一个标量值,而是K*K大小的矩阵:
R
M
P
=
[
r
m
p
1
,
1
r
m
p
1
,
2
⋅
⋅
r
m
p
2
,
1
r
m
p
2
,
2
⋅
⋅
⋅
⋅
⋅
⋅
⋅
⋅
⋅
⋅
⋅
]
R M P=\left[\begin{array}{cccc}{r m p_{1,1} } & {r m p_{1,2}} & {\cdot} & {\cdot} \\ {r m p_{2,1}} & {r m p_{2,2}} & {\cdot} & {\cdot} \\ {\cdot} & {\cdot} & {\cdot} & {\cdot} \\ {\cdot} & {\cdot} & {\cdot} & {\cdot} & {\cdot}\end{array}\right]
RMP=⎣⎢⎢⎡rmp1,1rmp2,1⋅⋅rmp1,2rmp2,2⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⎦⎥⎥⎤
这里
r
m
p
j
,
k
=
r
m
p
k
,
j
r m p_{j, k}=r m p_{k, j}
rmpj,k=rmpk,j用来捕捉两个任务之间的协同作用。易知
r
m
p
j
,
j
=
1
,
∀
j
r m p_{j, j}=1, \forall j
rmpj,j=1,∀j。这种增强提供了一个明显的优势,在许多实际场景中,任务之间的互补性在不同的任务对之间可能不是一致的,原作者提出的方法能够捕获不一致的任务间协同。
假设在第t代,
g
k
(
x
,
t
)
g^{k}(x, t)
gk(x,t)是任意第k个任务的一个真实分布
p
k
(
x
,
t
)
p^{k}(x, t)
pk(x,t)的概率评估模型,那么
g
k
(
x
,
t
)
g^{k}(x, t)
gk(x,t)是根据子种群
P
k
(
t
)
P^{k}(t)
Pk(t)的数据集构建的。将真实的密度函数替换为已学习的概率模型,并使用RMP矩阵的元素代替标量RMP,可以将式(20)重写为
g
c
k
(
x
,
t
)
=
[
1
−
0.5
K
⋅
∑
k
≠
j
r
m
p
k
,
j
]
⋅
g
k
(
x
,
t
)
+
0.5
K
∑
j
≠
k
r
m
p
k
,
j
⋅
g
j
(
x
,
t
)
g_{c}^{k}(x, t)=\left[1-\frac{0.5}{K} \cdot \sum_{k \neq j} r m p_{k, j}\right] \cdot g^{k}(x, t)+\frac{0.5}{K} \sum_{j \neq k} r m p_{k, j} \cdot g^{j}(x, t)
gck(x,t)=⎣⎡1−K0.5⋅k=j∑rmpk,j⎦⎤⋅gk(x,t)+K0.5j=k∑rmpk,j⋅gj(x,t)
这里
g
c
k
(
x
,
t
)
g_{c}^{k}(x, t)
gck(x,t)是一种近似子代种群
p
c
k
(
x
,
t
)
p_{c}^{k}(x, t)
pck(x,t)分布的概率混合模型。为了使
p
c
k
(
x
,
t
)
p_{c}^{k}(x, t)
pck(x,t)和
p
k
(
x
,
t
)
p^{k}(x, t)
pk(x,t)越近越好,等价于学习RMP矩阵使得子代概率模型
g
c
k
(
x
,
t
)
g_{c}^{k}(x, t)
gck(x,t)精确地建模父代分布
p
k
(
x
,
t
)
p^{k}(x, t)
pk(x,t)。采用KL来度量其两者。即最小化以下式子
min
R
M
P
∑
k
=
1
K
K
L
(
p
k
(
x
,
t
)
∥
g
c
k
(
x
,
t
)
)
\min _{R M P} \sum_{k=1}^{K} K L\left(p^{k}(x, t) \| g_{c}^{k}(x, t)\right)
RMPmink=1∑KKL(pk(x,t)∥gck(x,t))
即
min
R
M
P
∑
k
=
1
K
∫
X
p
k
(
x
,
t
)
⋅
[
log
p
k
(
x
,
t
)
−
log
g
c
k
(
x
,
t
)
]
⋅
d
x
\min _{R M P} \sum_{k=1}^{K} \int_{\boldsymbol{X}} p^{k}(x, t) \cdot\left[\log p^{k}(x, t)-\log g_{c}^{k}(x, t)\right] \cdot d x
RMPmink=1∑K∫Xpk(x,t)⋅[logpk(x,t)−loggck(x,t)]⋅dx
最小化上式即最大化以下式子(因为第一项和RMP没关系)
max
R
M
P
∑
k
=
1
K
∫
X
p
k
(
x
,
t
)
⋅
log
g
c
k
(
x
,
t
)
⋅
d
x
\max _{R M P} \sum_{k=1}^{K} \int_{X} p^{k}(x, t) \cdot \log g_{c}^{k}(x, t) \cdot d x
RMPmaxk=1∑K∫Xpk(x,t)⋅loggck(x,t)⋅dx
又因为
E
[
log
g
c
k
(
x
,
t
)
]
=
∫
X
p
k
(
x
,
t
)
⋅
log
g
c
k
(
x
,
t
)
⋅
d
x
\mathbb{E}\left[\log g_{c}^{k}(x, t)\right]=\int_{\boldsymbol{X}} p^{k}(x, t) \cdot \log g_{c}^{k}(x, t) \cdot d x
E[loggck(x,t)]=∫Xpk(x,t)⋅loggck(x,t)⋅dx,那么上式可修改为
max
R
M
P
∑
k
=
1
K
E
[
log
g
c
k
(
x
,
t
)
]
\max _{R M P} \sum_{k=1}^{K} \mathbb{E}\left[\log g_{c}^{k}(x, t)\right]
RMPmaxk=1∑KE[loggck(x,t)]
假设
θ
(
=
μ
/
λ
)
=
0.5
\theta(=\mu / \lambda)=0.5
θ(=μ/λ)=0.5,那么
E
[
log
g
c
k
(
x
,
t
)
]
=
1
N
/
2
∑
i
=
1
N
/
2
log
g
c
k
(
x
i
k
,
t
)
\mathbb{E}\left[\log g_{c}^{k}(x, t)\right] = \frac{1}{N/2} \sum_{i=1}^{N / 2} \log g_{c}^{k}\left(x_{i k}, t\right)
E[loggck(x,t)]=N/21∑i=1N/2loggck(xik,t),修改上式为
max
R
M
P
∑
k
=
1
K
1
N
/
2
∑
i
=
1
N
/
2
log
g
c
k
(
x
i
k
,
t
)
\max _{R M P} \sum_{k=1}^{K} \frac{1}{N/2} \sum_{i=1}^{N / 2} \log g_{c}^{k}\left(x_{i k}, t\right)
RMPmaxk=1∑KN/21i=1∑N/2loggck(xik,t)
即假设对于所有
k
∈
{
1
,
2
,
…
,
K
}
k \in\{1,2, \ldots, K\}
k∈{1,2,…,K},在每个子种群
P
k
(
t
)
P^{k}(t)
Pk(t)上建立概率模型
g
k
(
x
,
t
)
g^{k}(x, t)
gk(x,t)。那么学习RMP矩阵就是最大化下列似然函数:
max
R
M
P
∑
k
=
1
K
∑
i
=
1
N
/
2
log
g
c
k
(
x
i
k
,
t
)
\max _{R M P} \sum_{k=1}^{K} \sum_{i=1}^{N / 2} \log g_{c}^{k}\left(x_{i k}, t\right)
RMPmaxk=1∑Ki=1∑N/2loggck(xik,t)
这里
x
i
k
x_{ik}
xik是第i个采样个体在数据集
P
k
(
t
)
P^{k}(t)
Pk(t)上。
通过以上方法进行RMP矩阵的数据驱动学习,可以直接使多任务设置中的各种任务相互作用,同时有助于抑制负迁移。由于实际中 P k ( t ) P^{k}(t) Pk(t)数据较少,如果一个复杂的模型很容易过拟合,事实上在经典的迁移/多任务学习文献中,通常通过内部交叉验证步骤或引入噪声来克服,以防止过度拟合。MFEA-II的作者建议使用一个简单快速的模型去防止过拟合(例如单变量的边际分布)。
因此MFEA-II的框架如下:

图左:现有MFEA的总体框架。注意MFEA使用了一个离线标量rmp赋值。图右:MFEA-II与添加在线RMP矩阵学习模块。
其中RMP的在线学习的伪代码如下

这里要求
∑
k
=
1
K
∑
i
=
1
N
/
2
log
g
c
k
(
x
i
k
,
t
)
\sum_{k=1}^{K} \sum_{i=1}^{N / 2} \log g_{c}^{k}\left(x_{i k}, t\right)
∑k=1K∑i=1N/2loggck(xik,t)是向上凸的,因此利用经典的优化器可以在较小的计算开销下求解问题。
MFEA-II中的任务间交叉的伪代码如下

综上所述,MFEA-II在MFEA的基础上加入了在线评估rmp技术,使得直接自动的设置各种任务的相互作用,同时有助于抑制负迁移。这里就不列出它的代码了,感兴趣的同学去我主页上下载吧。
四.参考文献
[1]A. Gupta, Y.-S. Ong, and L. Feng, “Multifactorial evolution: Toward evolutionary multitasking,” IEEE Trans. Evol. Comput., vol. 20, no. 3, pp.343–357, 2016.
[2]K. K. Bali, Y. Ong, A. Gupta and P. S. Tan, “Multifactorial Evolutionary Algorithm with Online Transfer Parameter Estimation: MFEA-II,” in IEEE Transactions on Evolutionary Computation, doi: 10.1109/TEVC.2019.2906927, 2019.
[3]K. Swersky, J. Snoek, and R. P. Adams, “Multi-task bayesian optimization,” in Advances in neural information processing systems, 2013, pp. 2004–2012.















 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









