







1. basic
- h ( u ) = 1 2 ∥ u − β ∥ 2 2 + λ ∥ u ∥ 1 h(u) = \frac{1}{2}\| u -\beta \|_2^2 + \lambda \|u \|_1 h(u)=21∥u−β∥22+λ∥u∥1 is strictly convex,
we need to prove S λ ( β ) = p r o x λ ∥ ⋅ ∥ 1 S_{\lambda}(\beta) = {\rm prox}_{\lambda \| \cdot\|_{1}} Sλ(β)=proxλ∥⋅∥1
f
:
R
N
→
R
f: \mathbf{R}^{N} \rightarrow \mathbf{R}
f:RN→R
y
y
y is a subgradient of
f
f
f at
x
0
x_0
x0, if
f
(
x
)
≥
f
(
x
0
)
+
⟨
y
,
x
−
x
0
⟩
f(x) \ge f(x_0) + \langle y, x - x_0 \rangle
f(x)≥f(x0)+⟨y,x−x0⟩ for all
x
∈
R
N
x \in \mathbf{R}^{N}
x∈RN, and
y
∈
∂
f
(
x
0
)
y \in \partial{f(x_0)}
y∈∂f(x0)
0
∈
u
−
β
+
∂
(
λ
∥
u
∥
1
)
0 \in u - \beta + \partial(\lambda \| u \|_1)
0∈u−β+∂(λ∥u∥1), the i-th component
u
i
u_i
ui obeys
u
i
=
β
i
−
∂
(
λ
∣
u
i
∣
)
u_i = \beta_i - \partial(\lambda |u_i|)
ui=βi−∂(λ∣ui∣). Then
u
i
=
max
(
∣
β
i
∣
−
λ
,
0
)
⋅
s
i
g
n
(
β
i
)
=
P
λ
(
β
i
)
u_i = \max{(| \beta_i| - \lambda , 0) \cdot {\rm sign}(\beta_i) } = \mathscr{P}_{\lambda}(\beta_i)
ui=max(∣βi∣−λ,0)⋅sign(βi)=Pλ(βi)
Thus, we have
S
λ
(
β
)
=
p
r
o
x
λ
∥
⋅
∥
1
β
S_{\lambda}(\beta) = {\rm prox}_{\lambda \| \cdot \|_1}{\beta}
Sλ(β)=proxλ∥⋅∥1β by the concept of the soft-thresholding operator.



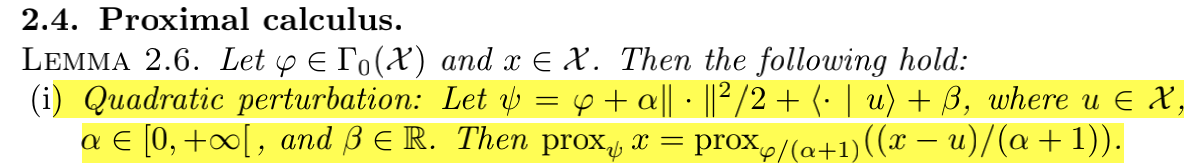
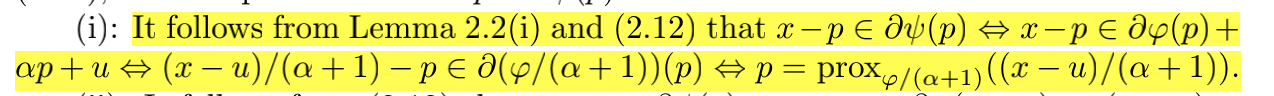
2. The proof of Lemma2
p ( β ) = λ γ ∥ β ∥ 1 p( \beta) = \lambda \gamma \| \beta \|_1 p(β)=λγ∥β∥1 tell us that p r o x p β = S λ γ ( β ) {\rm prox}_{p} \beta = S_{ \lambda \gamma }(\beta) proxpβ=Sλγ(β).
λ
p
γ
,
ε
(
β
)
=
p
(
β
)
+
λ
ε
∥
β
∥
2
2
\lambda p_{\gamma, \varepsilon}(\beta) = p(\beta)+ \lambda \varepsilon \| \beta \|_2^2
λpγ,ε(β)=p(β)+λε∥β∥22, and then we have
p
r
o
x
λ
p
γ
,
ε
β
=
p
r
o
x
p
1
+
p
(
β
−
u
1
+
ρ
)
{\rm prox}_{\lambda p_{\gamma, \varepsilon}} \beta = {\rm prox}_{\frac{p}{1+p}}(\frac{\beta - u}{1+\rho})
proxλpγ,εβ=prox1+pp(1+ρβ−u), where
ρ
=
2
λ
ε
,
u
=
0
,
σ
=
0
,
\rho = 2 \lambda \varepsilon, u = 0, \sigma = 0,
ρ=2λε,u=0,σ=0, Therefore,
p
r
o
λ
p
γ
,
ε
β
=
p
r
o
x
p
1
+
2
ε
λ
(
β
1
+
2
ε
λ
)
=
S
λ
γ
1
+
2
ε
λ
(
β
1
+
2
ε
λ
)
=
1
1
+
2
ε
λ
S
λ
γ
(
β
)
\begin{aligned} {\rm pro}_{\lambda p_{\gamma, \varepsilon}} \beta &= {\rm prox}_{\frac{p}{1 + 2 \varepsilon \lambda }} (\frac{\beta}{1 + 2 \varepsilon \lambda})\\ &= S_{\frac{\lambda \gamma}{1 + 2 \varepsilon \lambda}} (\frac{\beta}{1 + 2 \varepsilon \lambda}) \\ &= \dfrac{1}{1 + 2 \varepsilon \lambda}S_{\lambda \gamma}(\beta) \end{aligned}
proλpγ,εβ=prox1+2ελp(1+2ελβ)=S1+2ελλγ(1+2ελβ)=1+2ελ1Sλγ(β)
3. for ℓ 0.5 \ell_{0.5} ℓ0.5
Since the function
h
(
u
)
=
1
2
∥
u
−
β
∥
2
2
+
λ
∥
u
∥
0.5
h(u) = \frac{1}{2} \|u - \beta \|_2^2 + \lambda \| u \|_{0.5}
h(u)=21∥u−β∥22+λ∥u∥0.5 is strictly convex, it is easy to see that there exists a unique minimizer. According to the definition of the proximity operator, we need to prove
H
λ
(
β
)
=
p
r
o
x
λ
∥
⋅
∥
0.5
β
H_{\lambda}(\beta) = {\rm prox}_{\lambda \| \cdot \|_{0.5}} \beta
Hλ(β)=proxλ∥⋅∥0.5β
To do this, recalling the concept of a subgradient of a convex function
f
:
R
N
→
R
f: \mathbf{R}^N \rightarrow \mathbf{R}
f:RN→R, we say that
y
y
y is a subgradient of
f
f
f at
x
0
x_0
x0, if
f
(
x
)
≥
f
(
x
0
)
+
⟨
y
,
x
−
x
0
⟩
f(x) \ge f(x_0) + \langle y, x - x_0 \rangle
f(x)≥f(x0)+⟨y,x−x0⟩ for all
x
∈
R
N
x \in \mathbf{R}^N
x∈RN, denoted by
y
∈
∂
f
(
x
0
)
y \in \partial f(x_0)
y∈∂f(x0). Now
u
u
u minimizes
h
h
h if and only if
0
0
0 is a subgradient of the functional
h
h
h at point
u
u
u, that is,
0
∈
u
−
β
+
∂
(
λ
∥
u
∥
0.5
)
0 \in u - \beta + \partial (\lambda \| u \|_{0.5})
0∈u−β+∂(λ∥u∥0.5), i.e. the the
i
i
i-th component
u
i
u_i
ui obeys
u
i
=
β
i
−
∂
(
λ
∣
u
i
∣
0.5
)
u_i = \beta_i - \partial (\lambda |u_i|_{0.5})
ui=βi−∂(λ∣ui∣0.5). Then
这
里
根
据
徐
宗
本
老
师
的
证
明
写
出
结
果
\color{red}{这里根据徐宗本老师的证明写出结果}
这里根据徐宗本老师的证明写出结果 =
P
λ
(
β
i
)
\mathscr{P}_{\lambda} (\beta_i)
Pλ(βi).Thus, we have
H
λ
(
β
)
=
p
r
o
x
λ
∥
⋅
∥
0.5
β
H_{\lambda} (\beta) = {\rm prox}_{\lambda \| \cdot \|_{0.5}} \beta
Hλ(β)=proxλ∥⋅∥0.5β by the theorem of the hard-thresholding operator. This completes the proof.
p
r
o
λ
p
γ
,
ε
β
=
p
r
o
x
p
1
+
2
ε
λ
(
β
1
+
2
ε
λ
)
=
H
λ
γ
1
+
2
ε
λ
(
β
1
+
2
ε
λ
)
\begin{aligned} {\rm pro}_{\lambda p_{\gamma, \varepsilon}} \beta &= {\rm prox}_{\frac{p}{1 + 2 \varepsilon \lambda }} (\frac{\beta}{1 + 2 \varepsilon \lambda})\\ &= H_{\frac{\lambda \gamma}{1 + 2 \varepsilon \lambda}} (\frac{\beta}{1 + 2 \varepsilon \lambda}) \\ \end{aligned}
proλpγ,εβ=prox1+2ελp(1+2ελβ)=H1+2ελλγ(1+2ελβ)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









