






 本文探讨了在深度学习中如何通过GradNorm和DWA等方法平衡多任务的损失优化,避免梯度冲突,同时介绍了如何通过多目标融合推理模型综合预估多个目标以提升用户满意度。
本文探讨了在深度学习中如何通过GradNorm和DWA等方法平衡多任务的损失优化,避免梯度冲突,同时介绍了如何通过多目标融合推理模型综合预估多个目标以提升用户满意度。
多目标loss平衡:
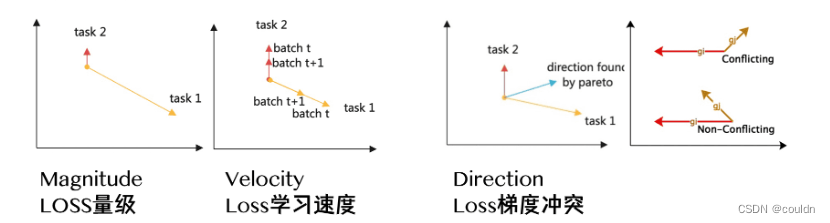
优化方法更多的考虑的是在已有结构下,更好地结合任务进行训练和参数优化,它从Loss与梯度的维度去思考不同任务之间的关系。在优化过程中缓解梯度冲突,参数撕扯,尽量达到多任务的平衡优化。
-
GradNorm 尝试将不同任务的梯度调节到相似的量级来控制多任务网络的训练,以鼓励网络以尽可能相同的速度学习所有任务。
-
DWA 它也通过考虑每个任务的损失改变,去学习平均不同训练轮数下各任务的权重。
多目标融合推理
为了建模用户的满意度,我们会对多个隐式、显式目标进行预估,如点击率、有效播放率、播放时长、点赞率、关注率等。最终用统一的融合公式将预估值合成一个排序分。
















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









