







目标检测
单目标检测
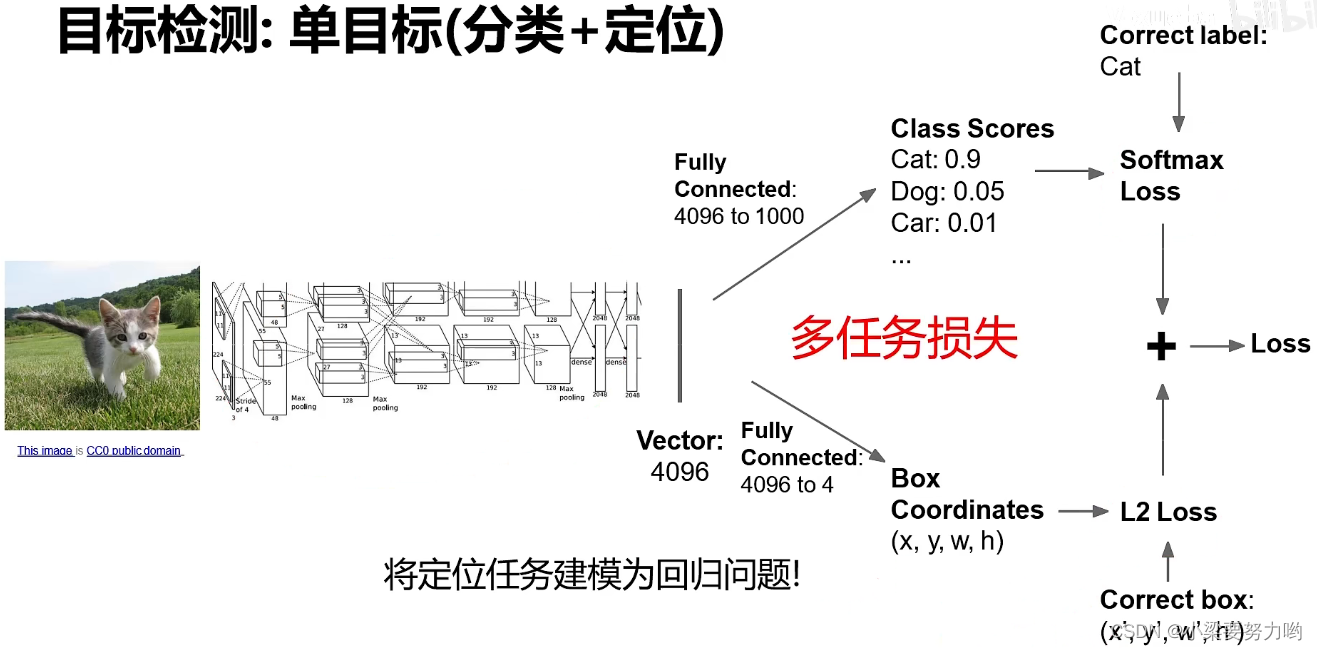
训练思路:一般分三个阶段,先训练分类(一般是拿现成已经训练好的模型),再训练定位,再一起训练分类+定位。
Ps:目标检测中,一般不从头开始训练网络,而是使用ImageNet上预训练的模型。
多任务损失:网络训练的目标是降低总损失,所以 softmax loss 和 L2 loss 将同时减小,也可以为 softmax loss 和 L2 loss 分别设置一个权重,通过改变权重,调整 softmax loss 和 L2 loss 在总损失中所占的比重。
姿态估计:在人体上标注关键点,然后通过训练,与标答进行对比。
多目标检测
思考:神经网络的标答是预先建立好的,因为多目标检测中目标数量并不确定,输出的维度不确定,就无法建立Correct box标答,如果使用单目标检测的训练方法,无法建立多目标检测的表达,训练将不能进行。
滑动窗口
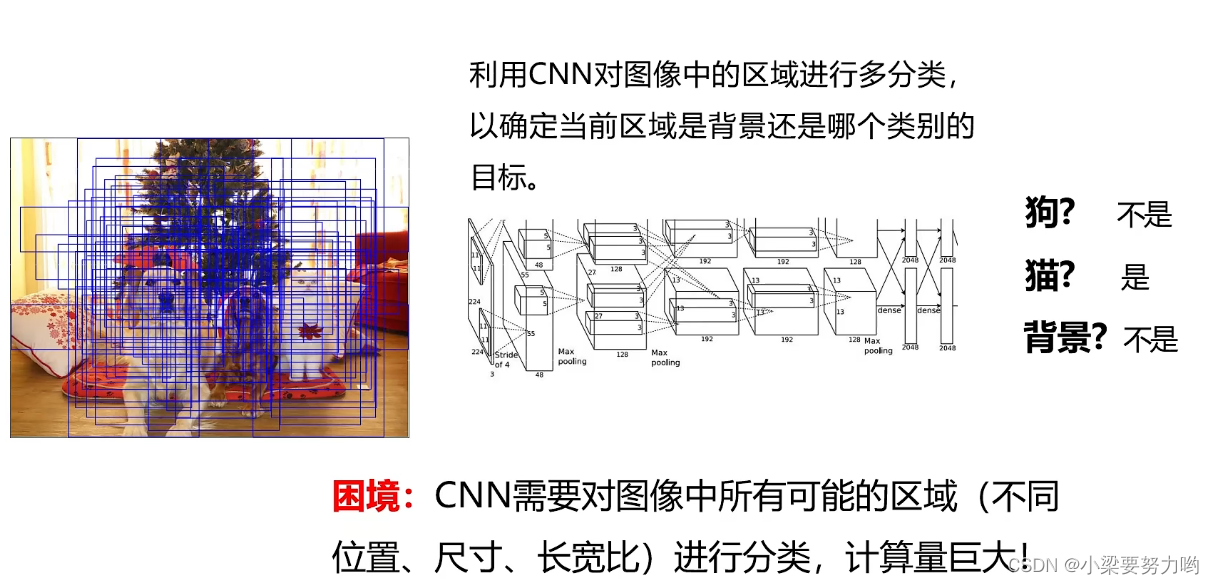
思路:将图像中所有可能的区域都给到卷积神经网络进行分类,只留下能正确分类的窗口。
注:仅当分类器速度够快的时候才能这样做,比如人脸识别时使用Adaboost进行穷举。
R-CNN
思考:针对穷举图像所有区域神经网络分类计算量大这个问题,提出了一种新的思想,先从图像中产生一些候选区域再进行分类,而不是穷举图像中所有区域。例如:区域建议 selective search。
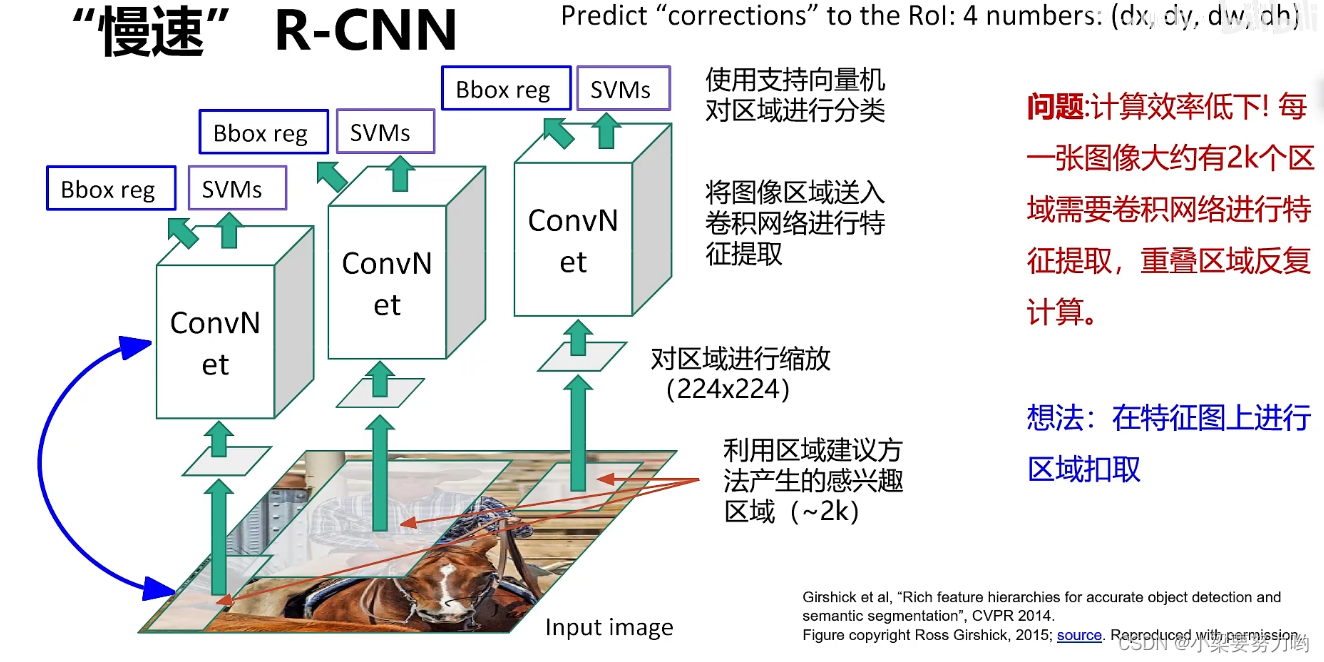
思路:
1.利用区域建议产生感兴趣的区域。(存入硬盘)
2.对区域进行缩放。
3.将图像区域送入卷积网络(可以直接使用ResNet)进行特征提取。(存入硬盘)
4.使用支持向量机对区域进行分类,同时进行边界框回归(修正学习)。
边界框回归(Bbox reg):区域建议生成的区域,可能有损失,效果不好,进行边界框回归,就是为了修正区域建议生成的区域与真实区域的偏差。
问题:计算效率低下,不能进行使用。
Fast R-CNN
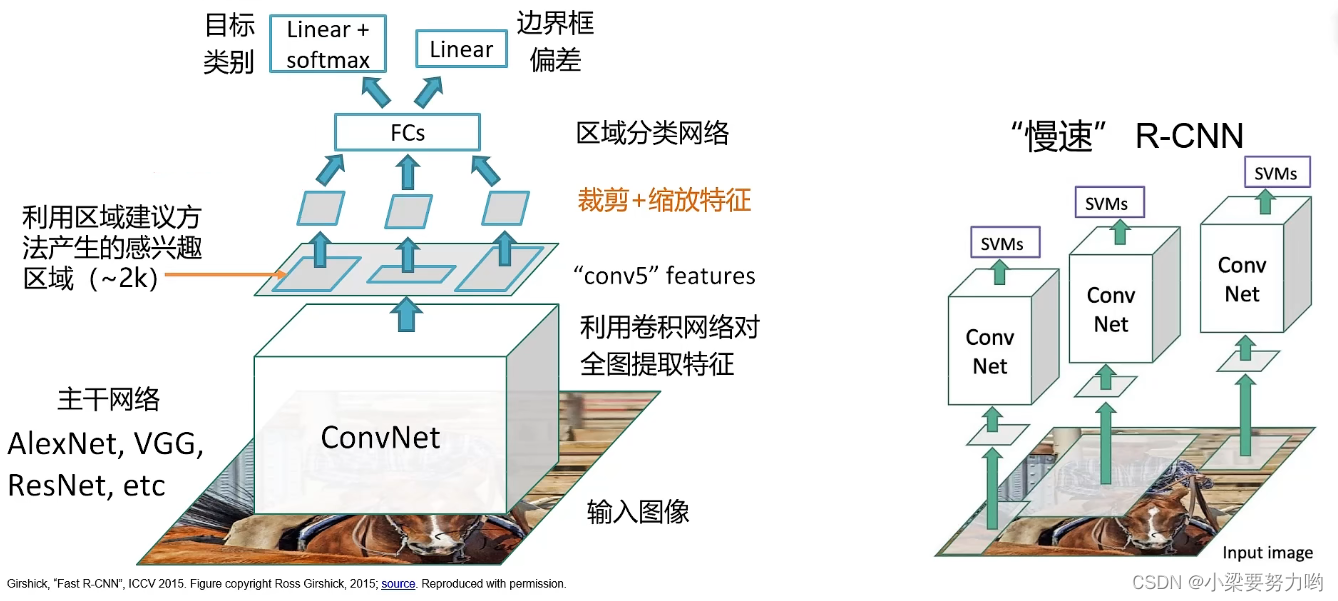
思路:
1.利用卷积网络对全图进行特征提取。
2.利用区域建议的方法产生感兴趣的区域。
3.对感兴趣的区域(特征)进行裁剪+缩放处理。
4.通过全连接神经网络进行分类。
改进:
1.先提取特征后区域建议:如果先进行区域建议后进行特征提取,计算量比较大。
2.采用全连接神经网络
3.裁剪+缩放特征(RoI Pool)
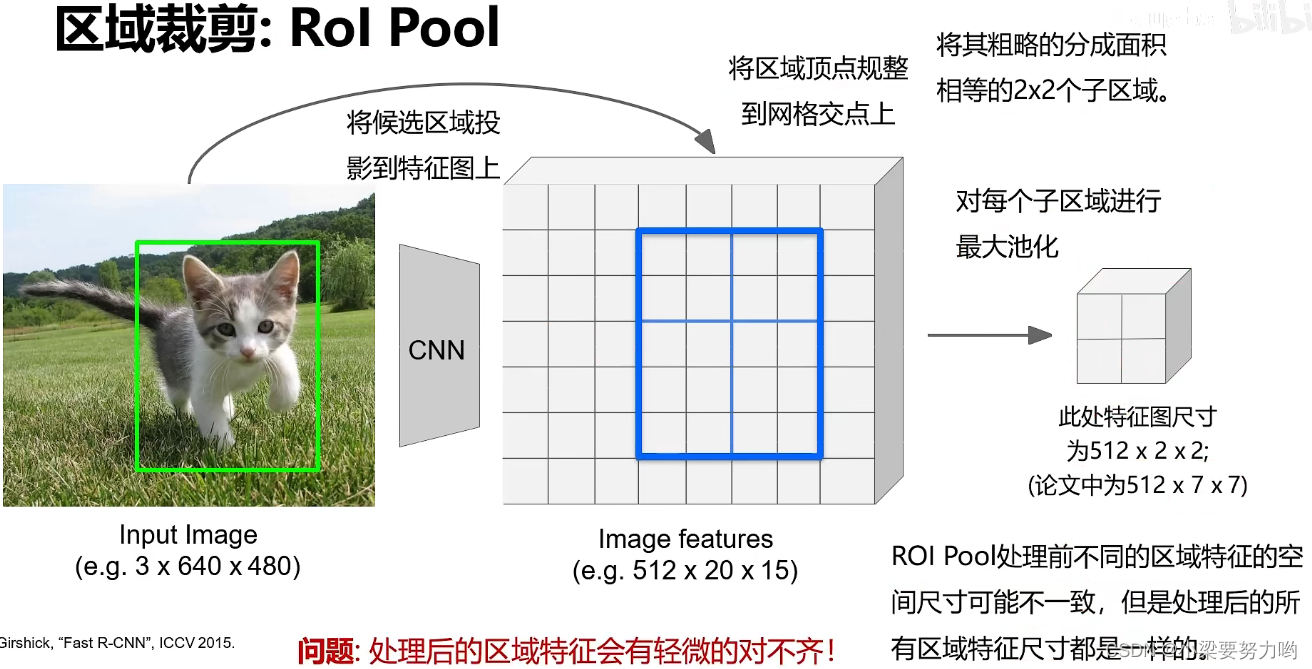
区域裁剪(Rol Pool)
思路:
1.将候选区域投影到特征图上
2.将区域顶点规整到网格交点上(处理后的区域会有轻微的对不齐)
3.将其粗略的分成面积相等的n*n个子区域
(n由最终想要的特征图尺寸决定)
4.对每个子区域进行最大池化
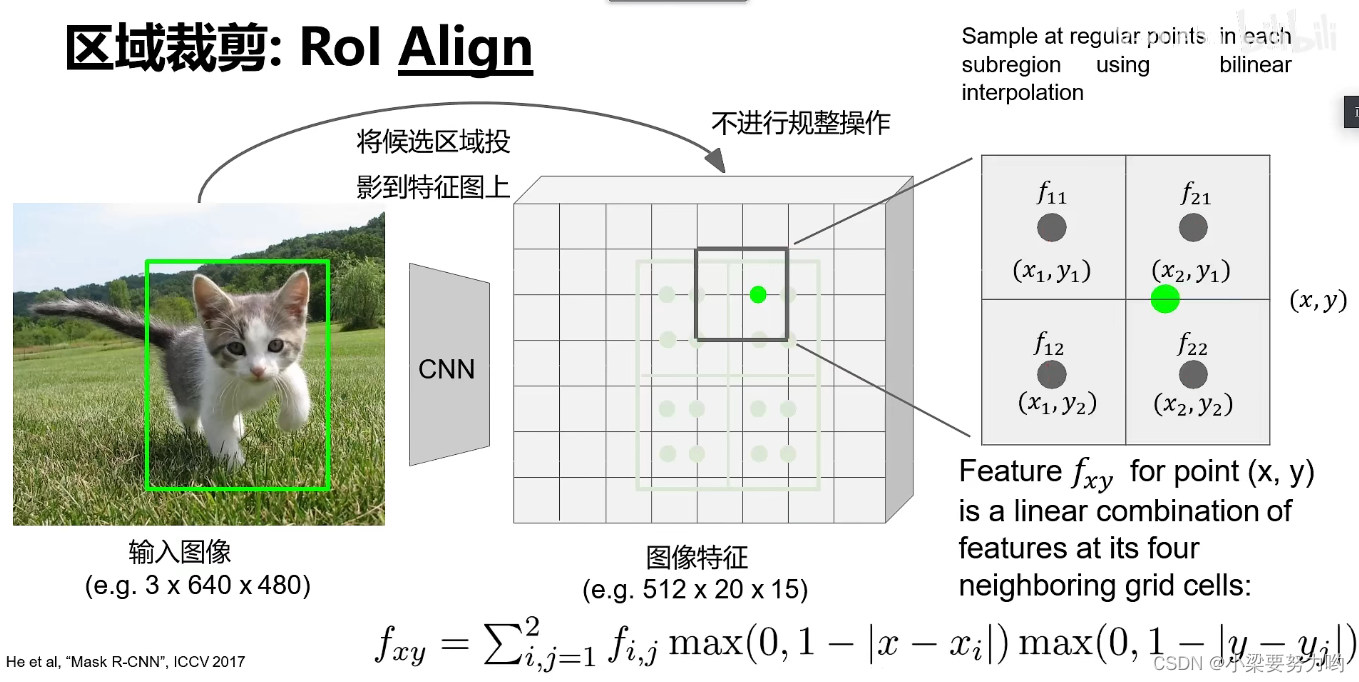
区域裁剪(Rol Align)
思路:
1.将候选区域投影到特征图上
2.将区域顶点规整到网格交点上(不进行规整操作)
3.在每个网格上规格地取四个点,对每个点在周围的四格中进行双线性插值(对不同距离的点赋予不同的权重)
4.对每个子区域进行最大池化
R-CNN vs Fast R-CNN
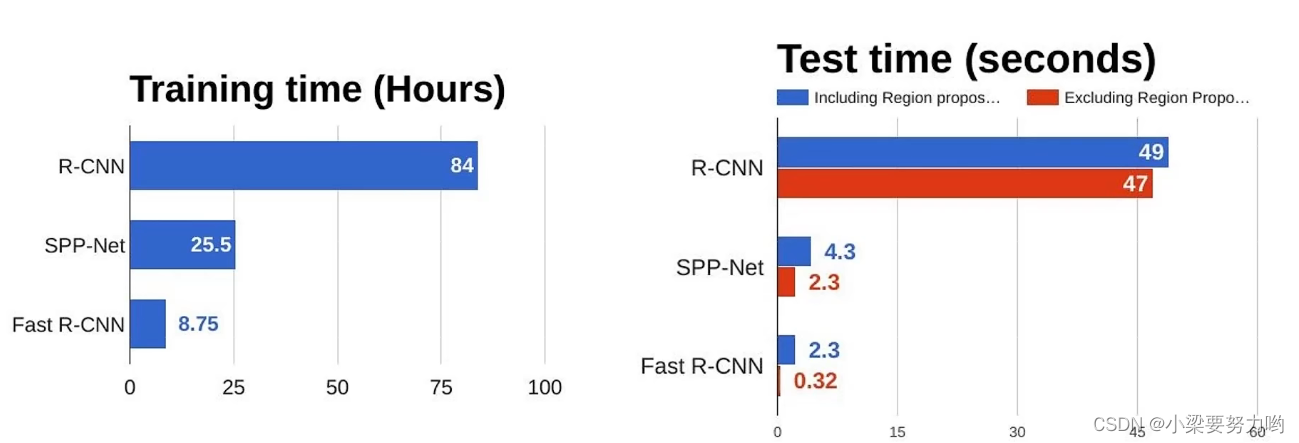
问题:在右图中可以看出,候选区域产生过程(区域建议)耗时过长,几乎等于单张图片的检测时间。
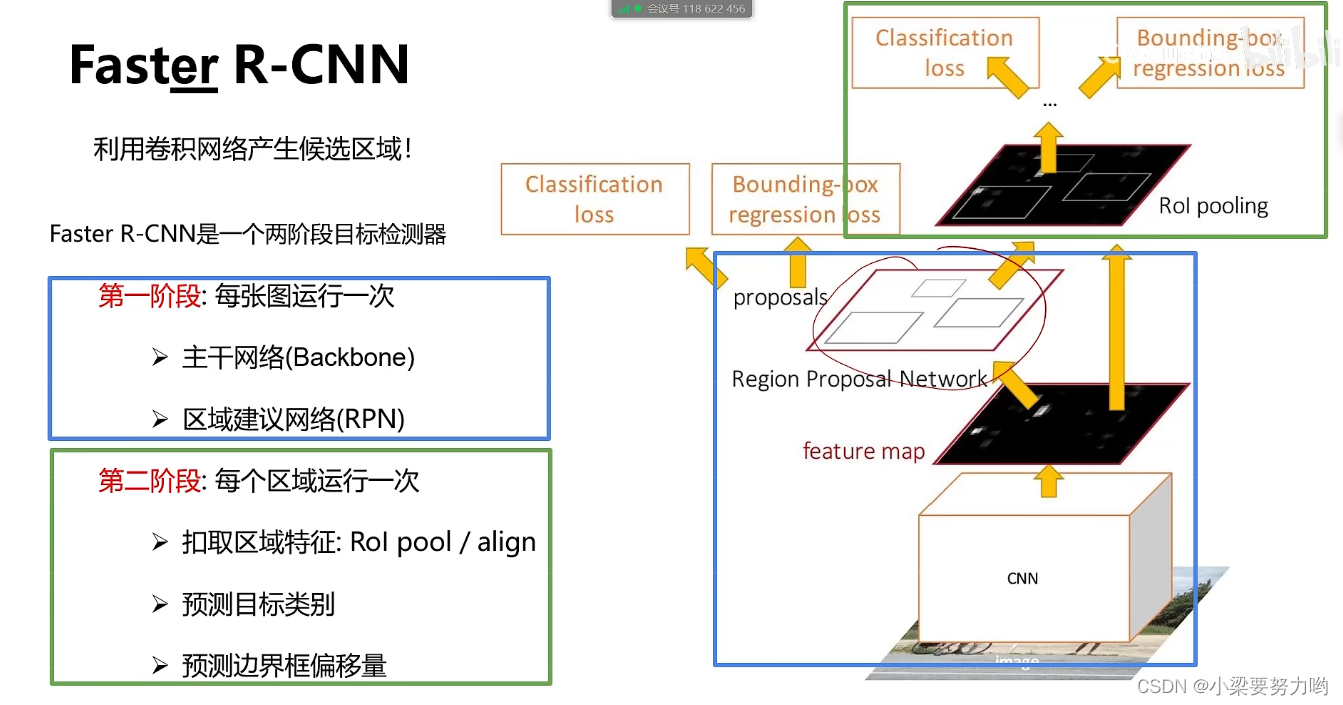
Faster R-CNN
突破点:让卷积神经网络自己产生候选区域。
RPN:
1.将利用卷积网络对全图进行特征提取的结果输入到RPN
2.将结果通过全连接神经网络判断是否为object
损失联合训练:
1.RPN分类损失(目标/非目标)
2.RPN边界框坐标回归损失
3.候选区域分类损失
4.最终边界框坐标回归损失
思路:两阶段目标检测器
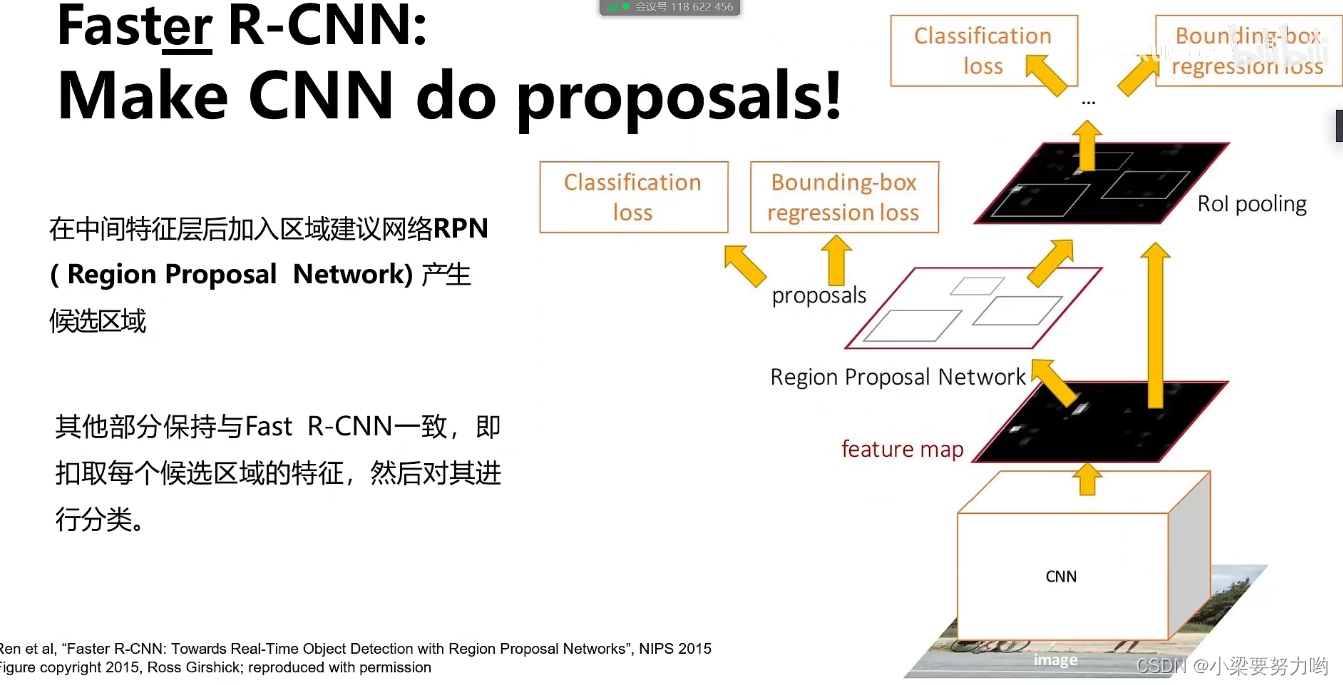
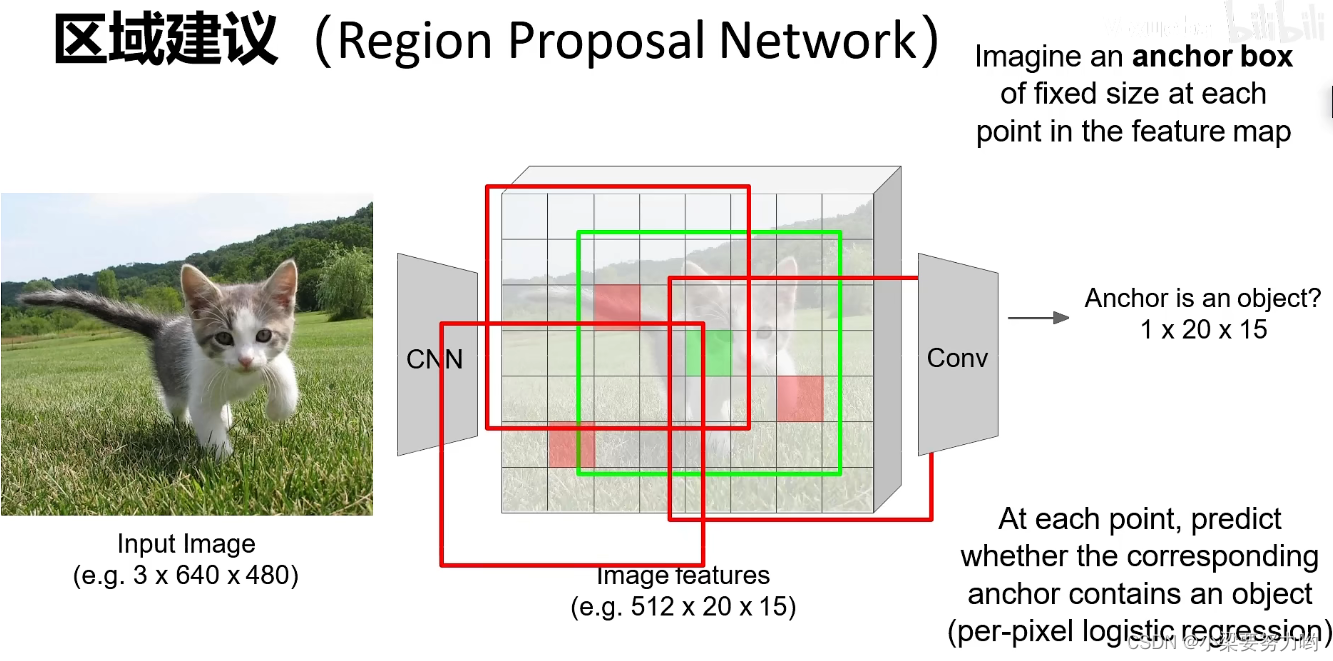
区域候选网络(Region Proposal Network)
前言:经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用Selective Search方法生成检测框。而Faster R-CNN直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
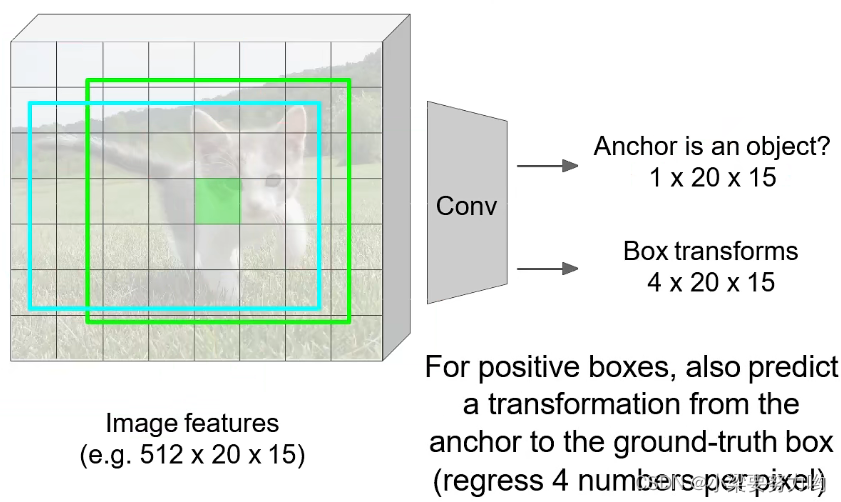
锚点(anchor):选择锚点,判断以锚点为中心的区域是否包含某一个类别。
给予一个anchor后,进行回归并返回一个偏差量,修正区域让区域描述得更加准确。
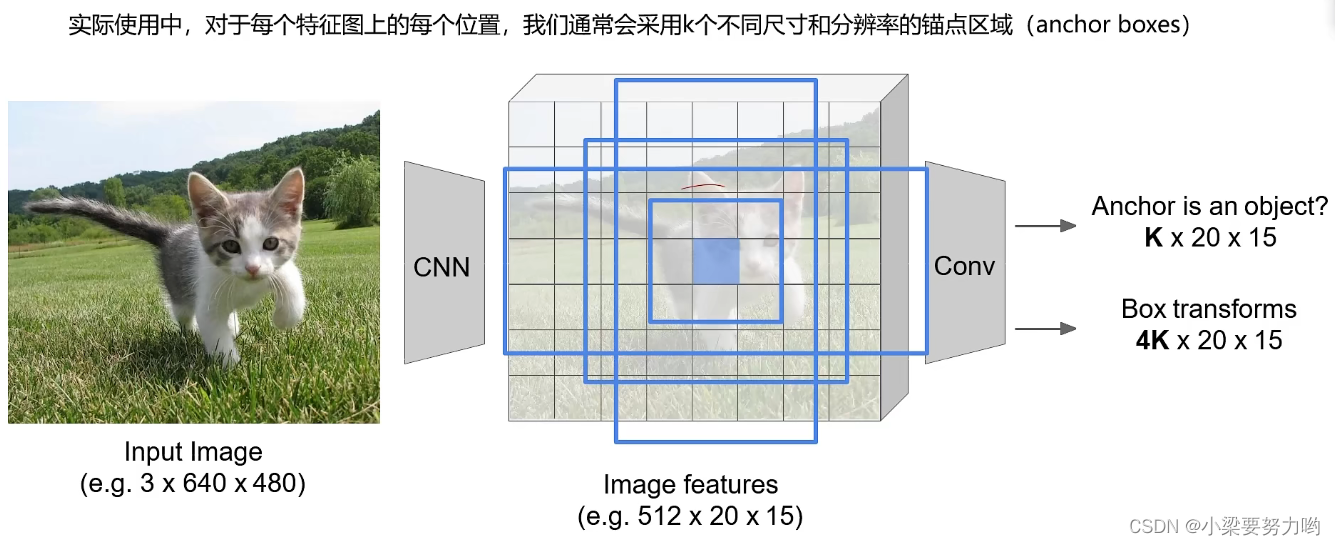
实际使用时,对应每个特征图上的每个位置,我们通常会采用k个不同尺寸和分辨率的锚点区域,在一个锚点处预测k种可能性,以此来增加一个点的预测能力。
将k * 20 * 15的boxes按照类别得分进行排序,选取前300个作为我们的候选区域。
一阶段目标检测器
1.yolo不进行区域建议。
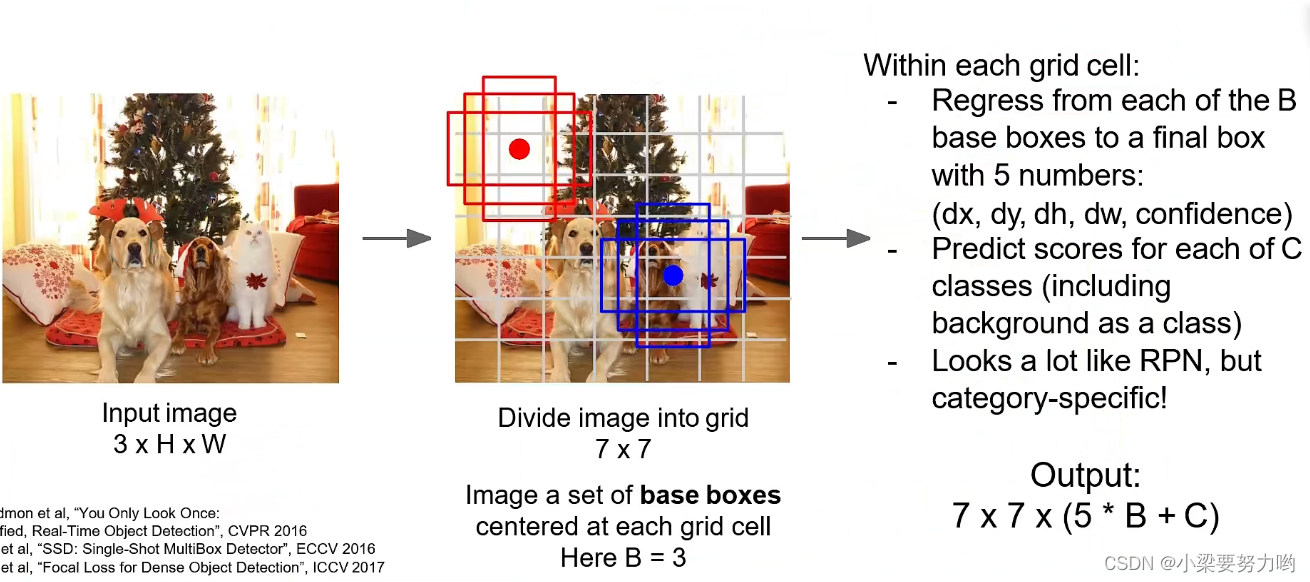
2.SSD对每层进行分类,每层都使用anchor特性,并将每一层的特征进行综合最终使用多层特征。
影响检测精度的因素

实例分割
在Faster-RCN的基础上加上Mask Prediction即可。
通过一个卷积进行上采样的过程得到Mask。
实例分割结果
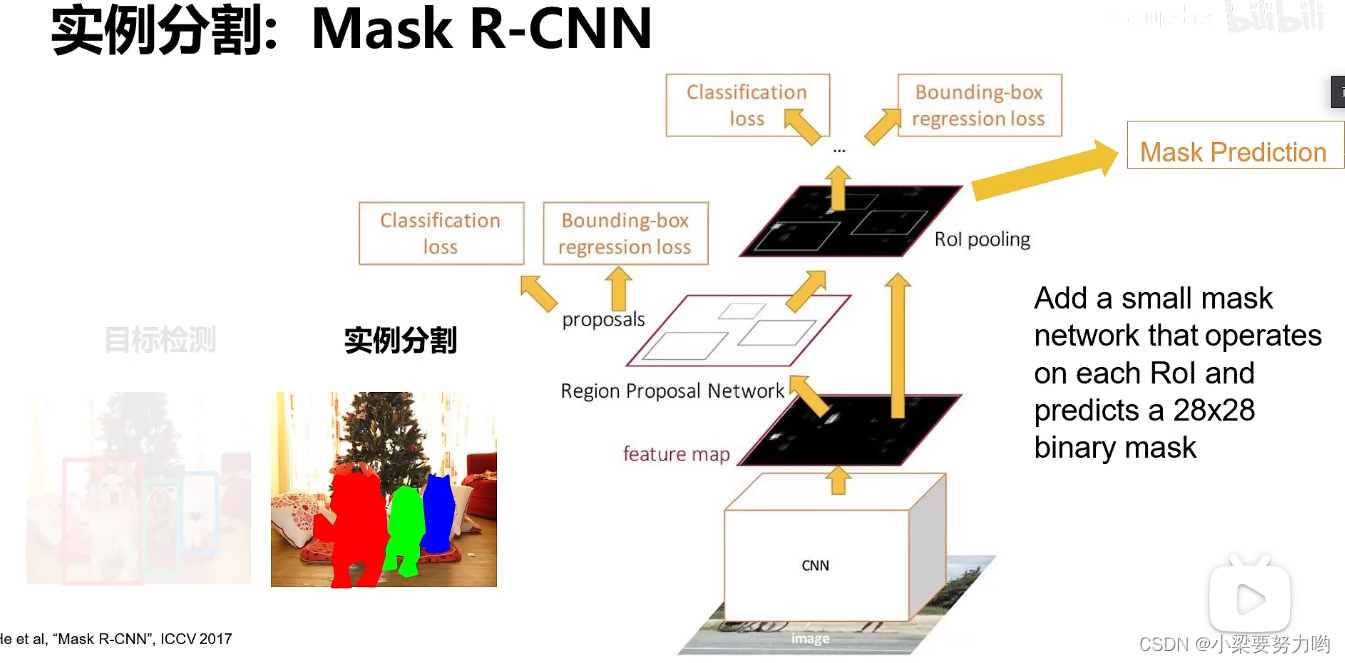
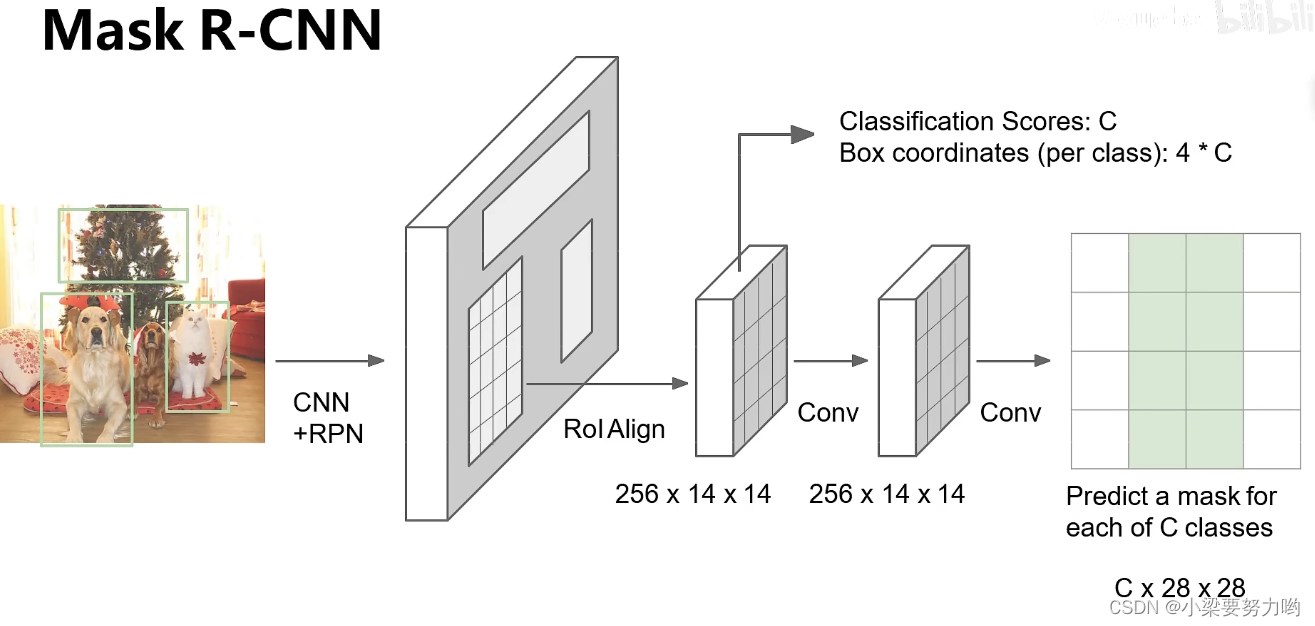

姿态检测:可以在第一次卷积后回归关键点检测。

Good implementations on GitHub!
TensorFlow Detection API:Faster RCNN, SSD, RFCN, Mask R-CNN














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









