







深层神经网络

深度学习其实就是有很多隐层的神经网络。
图1是四层的有三个隐层的神经网络,隐层中的单元数目是五、五、三,然后有一个输出单元。我们用符号L表示神经网络的层数,图1中的神经网络可表示为L=4。我们使用n[i]表示第i层的单元数,比如图1中第一层的单元数可表示为n[1]=5。我们通过n[0]=nx=3表示输入层的单元数。我们使用a[i]表示第i层中的激活函数,通常会看到a[i]=g(z[i])。我们使用w[i]表示在a[i]中计算z[i]值的权重,z[i]方程中的b[i]也是同样的道理。输入特征用x表示,它也是第0层的激活函数,故可以用a[0]表示。最后一层的激活函数a[l]等于y帽,也就是说a[l]等于预测输出。
深层网络中的正向传播
以图1为例,对其中一个训练样本x应用正向传播过程如下:
- 第一层:z[1]=w[1]x+b[1],a[1]=g[1](z[1])
- 第二层:z[2]=w[2]a[1]+b[2],a[2]=g[2](z[2])
- 第三层:z[3]=w[3]a[2]+b[3],a[3]=g[3](z[3])
- 第四层:z[4]=w[4]a[3]+b[3],a[4]=g[4](z[4])
以图1为例,用向量化的方法训练整个训练集的正向传播过程如下:
- 第一层:Z[1]=W[1]x+b[1],A[1]=g[1](Z[1])
- 第二层:Z[2]=W[2]A1]+b[2],A[2]=g[2](Z[2])
- 第三层:Z[3]=W[3]A[2]+b[3],A[3]=g[3](Z[3])
- 第四层:Z[4]=W[4]A[3]+b[3],A[4]=g[4](Z[4])
核对矩阵的维数
n[i]表示第i层的的单元数。以图1为例,n[0]=3,n[1]=5,n[2]=5,n[3]=3,n[4]=1。
正向传播中矩阵的维数:
- W[i]的维度必须是(n[i],n[i-1])
- b[i]的维度必须是(n[i],1)
- z[i],a[i]的维度必须是(n[i],1)
反向传播中矩阵的维数:
- dW[i]的维度必须是(n[i],n[i-1])
- db[i]的维度必须是(n[i],1)
向量化后一切就会发生改变,现在Z[1]是从每一个单独的z[1]的值叠加得到的。所以Z[1]的维度不再是(n[1],1),维度变成(n[1],m),其中m是训练集大小。W[1]的维度还是一样的,不过X不再是(n[0],1),而是把所有训练样本水平叠在一块儿,现在的维度是(n[0],m)。最后关于b[1]的细节就是其维度还是(n[1],1),但使用Python广播机制进行矩阵加法时,会复制成一个(n[1],m)的矩阵,然后逐个元素相加。Z[1]和A[1]的维度变成(n[1],m),dZ和dA的维度跟Z和A是一样的。
为什么使用深层表示

如果在建立人脸检测系统,深度神经网络所做的事就是当你输入一张脸部照片,我们可以可以把深度神经网络的第一层当成是一个特征探测器或者边缘探测器。隐藏单元就是图里的小方块,它们回去找这张照片里边缘的方向,可能是在水平或者竖直的方向找边缘在哪里。把许多的边缘结合在一起,就可以开始检测人脸的不同部分,然后再把这些部分(眼睛鼻子下巴)放在一起就可以识别或是探测不同的人脸啦。
边缘探测器其实相对来说都是针对照片中非常小块的面积,面部探测器就会针对大一些的区域。我们一般会从比较小的细节入手,比如边缘,然后再一步步到更大更复杂的区域,比如一只眼睛或是一个鼻子,再把眼睛鼻子装一块,组成更复杂的部分。
所以深度神经网络的许多隐层中,较早的前几层能学习一些低层次的简单特征。等到后面几层,就能把简单的特征结合起来,去探测更加复杂的东西。同时我们所计算的之前的几层,是相对简单的输入函数,到网络的神经就能实现很多复杂的计算。
搭建深层神经网络块
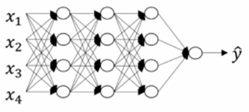
图3是一个层数较少的神经网络,在l层有正向函数和反向函数。
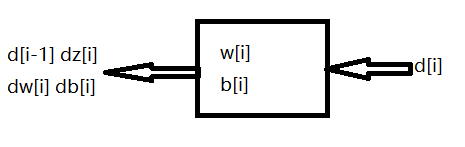
用作正向传播的是正向函数,我们输入a[l-1]并且输出a[l]作为计算结果,为此我们需要用到w[l],b[l]以及缓存中的z[l]。
用作反向传播的反向函数是另一个函数,输入da[l]输出d[l-1],你就会得到对激活函数的导数。反向函数中我们需要用到w[l]和b[l],我们可以计算出dz[l],dw[l]和db[l]。
参数和超参数
想要神经网络起到好的效果,就需要规划好模型的参数以及超参数。
在机器学习算法中还有其他参数需要输入到学习算法中,比如学习率α,我们需要设置α来决定参数如何进化。我们可能还需要设置梯度下降法循环的数量或者隐层数L、隐藏单元数。我们还可以选择激活函数,比如在隐层中是用ReLU还是sigmoid函数。前述这些参数实际上控制了最后参数w和b的值,所以它们被称作超参数,即控制实际参数的参数。
深度学习和大脑的关联性
把深度学习和人类大脑类比在这个领域早期也许值得一提,但现在这种类比已经过时了。因此,深度学习和大脑没有什么关联性。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









