






初读文章时看到原文图二想到了PredRNN与PredRNN++之间的改进思路,即加了个GHU(高速公路)单元可以减缓梯度消失,并且替换掉ST-LSTM改为CasualLSTM,而MotionGRU期初看起来改进思路跟上述比较相似,即加了两条由GRU为基础搭建的高速公路,用巧妙的链接方式连起来。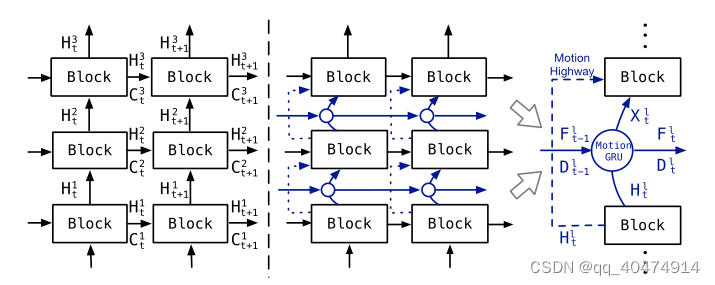
下面细说:
原文3.1节:
提出MotionRNN框架,将MotionGRU作为一个算子堆叠在每层RNN中间,不改变原始状态转换流。MotionGRU可以捕捉运动,并给予学习到的运动进行到隐藏状态的状态转换。当过渡的特征通过多层时运动会模糊甚至消失。后MotionRNN引入高速公路避免运动模糊。
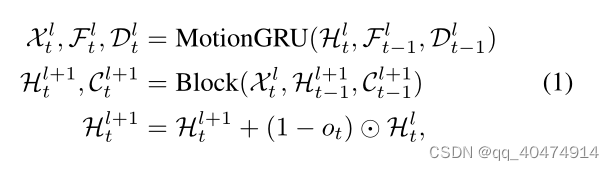
如图为MotionRNN,在第一层之后的公式。
可见MotionGRU的输出只有X会作为输入进入Block,而其余F,D继续沿时间步传播。下一层Block的输入为X和上一时间步的H,C。最后一行公式类似残差连接,作者解释为:“它通过先前的隐藏状态Hlt来补偿预测块的输出。我们重用输出门以显示所需的不变内容信息。这种高速公路连接为隐藏状态提供了额外的细节,并平衡了不变部分和可变运动部分。”
原文3.2节:
作者将MotionGRU分为两个部分:瞬态变化和趋势动量
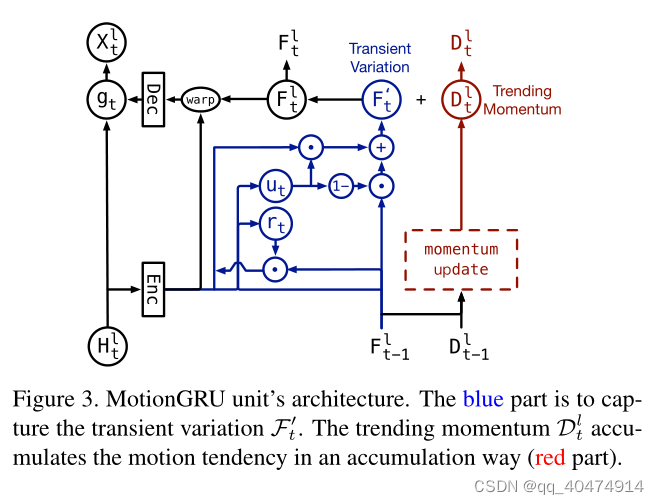
3.2.1瞬态变化
作者用一个ConvGRU来学习瞬态变化,如上图蓝色部分,输入为Htl,F(t-1, l)。
蓝色部分公式为: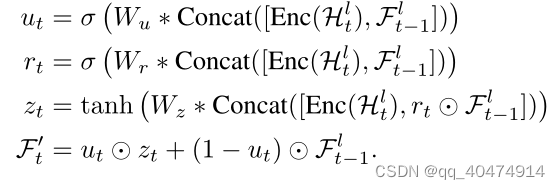
蓝色部分可用如下公式简述。
![]()
3.2.2趋势动量
作者受时间差分学习的启发,使用累加的方式捕获运动变化的模式。这让我想起来Memory In Memory的文章也是受差分的启发(根据Cramér 分解理论即任何时间序列数据的非平稳过程都可分解为若干个确定性的时变多项式和一个零均值的随机项,所以可以适当地使用差分运算降低其中时变多项式的阶数将其逐渐趋于平稳,使确定性的复杂趋势信息变得可预测。)
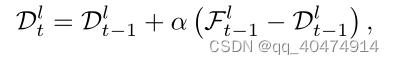
3.2.3MotionGRU总体模式
















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









