






问:
什么是过拟合
答:
模型在训练集上效果好,在测试集上效果差
问:
产生过拟合的原因
答:
1.相对于数据量来说,模型的参数量过多,拟合能力过强
2.训练集中存在噪音数据,模型学习到了噪音的特征
3.训练集中某些特征的分布和测试集的不一致,模型学习到了与测试集分布不一致的特征
4.训练轮数过多,没有使用earlystopping
问:
如何解决过拟合
答:
1.增加数据量
2.增加正则项,减少参数
3.选择参数更少的模型
4.采用earlystopping
5.采用模型集成,过拟合的表现为偏差小、方差大,模型集成bagging可以平均多个模型的结果,降低方差;boosting不仅可以减少偏差,还可以减少方差
解决过采样的欠采样的方法
随机上采样
从少数类的样本中进行随机采样来增加新的样本
随机下采样
从多数类样本中随机选择少量样本,再合并原有少数类样本作为新的训练数据集
随机欠采样有两种类型分别为有放回和无放回两种,无放回欠采样在对多数类某样本被采样后不会再被重复采样,有放回采样则有可能
随机采样的优缺点
优点:
简单
缺点:
上采样后的数据集中会反复出现一些样本,训练出来的模型会有一定的过拟合;
而下采样的缺点显而易见,那就是最终的训练集丢失了数据,模型只学到了总体模式的一部分。
上采样会把小众样本复制多份,一个点会在高维空间中反复出现,这会导致一个问题,那就是运气好就能分对很多点,否则分错很多点。
为了解决这一问题,可以在每次生成新数据点时加入轻微的随机扰动,经验表明这种做法非常有效,但是这一方式会加重过拟合。
过采样的改进:SMOTE与ADASYN
SMOTE
对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中
算法流程
1、对于少数类中每一个样本x,计算该点与少数类中其他样本点的距离,得到最近的k个近邻(即对少数类点进行KNN算法)。
2、根据样本不平衡比例设置一个采样比例以确定采样倍率,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为x’。
3、对于每一个随机选出的近邻x’,分别与原样本按照如下的公式构建新的样本:
xnew=x+rand(0,1) ∗ (x′−x)
缺点
1.K值需要人工选择
2.如果选取的少数类样本周围也都是少数类样本,则新合成的样本不会提供太多有用信息。这就像支持向量机中远离margin的点对决策边界影响不大。
3.如果选取的少数类样本周围都是多数类样本,这类的样本可能是噪音,则新合成的样本会与周围的多数类样本产生大部分重叠,致使分类困难。
Border-line SMOTE
这个算法会先将所有的少数类样本分成三类:
“noise” : 所有的k近邻个样本都属于多数类
“danger” : 超过一半的k近邻样本属于多数类
“safe”: 超过一半的k近邻样本属于少数类
Border-line SMOTE 算法只会从处于**”danger“**状态的样本中随机选择,然后用SMOTE算法产生新的样本。处于”danger“状态的样本代表靠近”边界“附近的少数类样本,而处于边界附近的样本往往更容易被误分类。因而 Border-line SMOTE 只对那些靠近”边界“的少数类样本进行人工合成样本,而 SMOTE 则对所有少数类样本一视同仁。
ADASYN
采用某种机制自动决定每个少数类样本需要产生多少合成样本,而不是像SMOTE那样对每个少数类样本合成同数量的样本
算法流程
1.首先计算需要合成的样本总量
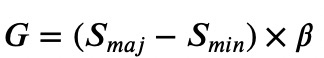
2.对于每个少类别样本,找出其K近邻个点,并计算:
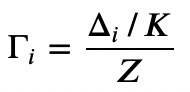
3.最后对每个少类别样本计算需要合成的样本数量,再用SMOTE算法合成新样本

优点
自动决定每个少数类样本所需要合成的样本数量,这等于是给每个少数类样本施加了一个权重,周围的多数类样本越多则权重越高
缺点
易受离群点的影响,如果一个少数类样本的K近邻都是多数类样本,则其权重会变得相当大,进而会在其周围生成较多的样本
EasyEnsemble 和 BalanceCascade
采用集成学习机制来处理传统随机欠采样中的信息丢失问题。
EasyEnsemble将多数类样本随机划分成n个子集,每个子集的数量等于少数类样本的数量,这相当于欠采样。接着将每个子集与少数类样本结合起来分别训练一个模型,最后将n个模型集成,这样虽然每个子集的样本少于总体样本,但集成后总信息量并不减少。
如果说EasyEnsemble是基于无监督的方式从多数类样本中生成子集进行欠采样,那么BalanceCascade则是采用了有监督结合Boosting的方式。在第n轮训练中,将从多数类样本中抽样得来的子集与少数类样本结合起来训练一个基学习器H,训练完后多数类中能被H正确分类的样本会被剔除。在接下来的第n+1轮中,从被剔除后的多数类样本中产生子集用于与少数类样本结合起来训练,最后将不同的基学习器集成起来。BalanceCascade的有监督表现在每一轮的基学习器起到了在多数类中选择样本的作用,而其Boosting特点则体现在每一轮丢弃被正确分类的样本,进而后续基学习器会更注重那些之前分类错误的样本。
NearMiss
(不懂)
数据清洗方法 (data cleaning tichniques)
这类方法主要通过某种规则来清洗重叠的数据,从而达到欠采样的目的
Tomek Link:
Tomek Link表示不同类别之间距离最近的一对样本,即这两个样本互为最近邻且分属不同类别。这样如果两个样本形成了一个Tomek Link,则要么其中一个是噪音,要么两个样本都在边界附近。这样通过移除Tomek Link就能“清洗掉”类间重叠样本,使得互为最近邻的样本皆属于同一类别,从而能更好地进行分类。
Edited Nearest Neighbours(ENN):
对于属于多数类的一个样本,如果其K个近邻点有超过一半都不属于多数类,则这个样本会被剔除。这个方法的另一个变种是所有的K个近邻点都不属于多数类,则这个样本会被剔除。
缺点:
最后,数据清洗技术最大的缺点是无法控制欠采样的数量。由于都在某种程度上采用了K近邻法,而事实上大部分多数类样本周围也都是多数类,因而能剔除的多数类样本比较有限。
过采样和欠采样结合
上文中提到SMOTE算法的缺点是生成的少数类样本容易与周围的多数类样本产生重叠难以分类,而数据清洗技术恰好可以处理掉重叠样本,所以可以将二者结合起来形成一个pipeline,先过采样再进行数据清洗。主要的方法是 SMOTE + ENN 和 SMOTE + Tomek ,其中 SMOTE + ENN 通常能清除更多的重叠样本
















 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









