







看别人见解违法coursera荣誉,看懂和做对是两码事
What is the "cache" used for in our implementation of forward propagation and backward propagation?
- We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.
- It is used to cache the intermediate values of the cost function during training.
- We use it to pass variables computed during backward propagation to the corresponding forward propagation step. It contains useful values for forward propagation to compute activations.
- It is used to keep track of the hyperparameters that we are searching over, to speed up computation.
缓存意义 W = W - learning_rate * dW 前向保存值,后向直接使用
Among the following, which ones are "hyperparameters"? (Check all that apply.)
- weight matrices
- size of the hidden layers
- number of layers L in the neural network
- activation values
- number of iterations
- learning rate α
- bias vectors
超参量,不需要计算,(W,b等需要计算),用于描述神经网络一些特征的,比如深度,个数,学习程度等
Which of the following statements is true?
- The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers.
- The earlier layers of a neural network are typically computing more complex features of the input than the deeper layers.
建议记那个电路模块,深=层数多=元器件少=节省空间,浅=层数少=元器件多=节省时间
Vectorization allows you to compute forward propagation in an L-layer neural network without an explicit for-loop (or any other explicit iterative loop) over the layers l=1, 2, …,L. True/False?
False
第一层没办法,如果你把X导入为A0,或许不错,但是相应的数据会混乱
Assume we store the values for in an array called layer_dims, as follows: layer_dims = [
, 4,3,2,1]. So layer 1 has four hidden units, layer 2 has 3 hidden units and so on. Which of the following for-loops will allow you to initialize the parameters for the model?
for i in range(1, len(layer_dims)):
parameter['W' + str(i)] = np.random.randn(layer_dims[i], layer_dims[i-1]) * 0.01
parameter['b' + str(i)] = np.random.randn(layer_dims[i], 1) * 0.01
初始化的意义在于打破对称性(非线性关系)(线性关系不需要,其只和输入有关),因此需要对所有参数进行初始化。其次是大小对应关系,不会就画图,A=WX+b,X是由x构成,x列向量,W里每一个单元应该是行向量(wi*x),再将该层参数叠在一起,所以 行数=n层 ,列数=n-1层
Consider the following neural network.How many layers does this network have?
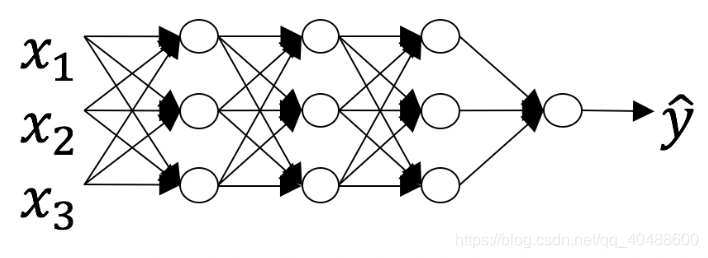
- The number of layers L is 4. The number of hidden layers is 3.
- The number of layers L is 3. The number of hidden layers is 3.
- The number of layers L is 4. The number of hidden layers is 4.
- The number of layers L is 5. The number of hidden layers is 4.
x层是输入层,不算到网络里面,在代码的画图演示里一般用A0代替,y是输入,而我们的目的就是预测y,所以y输出层算入网络,所以一共4层网络,y层是输出层,x是输入层,中间的是隐藏层/掩蔽层
During forward propagation, in the forward function for a layer ll you need to know what is the activation function in a layer (Sigmoid, tanh, ReLU, etc.). During backpropagation, the corresponding backward function also needs to know what is the activation function for layer ll, since the gradient depends on it. True/False?
True
不知道用的什么非线性函数怎么知道变换的,不要因为我们一直用sigmoid函数就以为不需要算,sigmoid是因为导书很容易表示,方便我们初学者使用,在写代码过程中理解网络含义
There are certain functions with the following properties:
(i) To compute the function using a shallow network circuit, you will need a large network (where we measure size by the number of logic gates in the network), but (ii) To compute it using a deep network circuit, you need only an exponentially smaller network. True/False?
True
记住那个电路图,空间和时间的选择问题
第 9 个问题
Consider the following 2 hidden layer neural network:
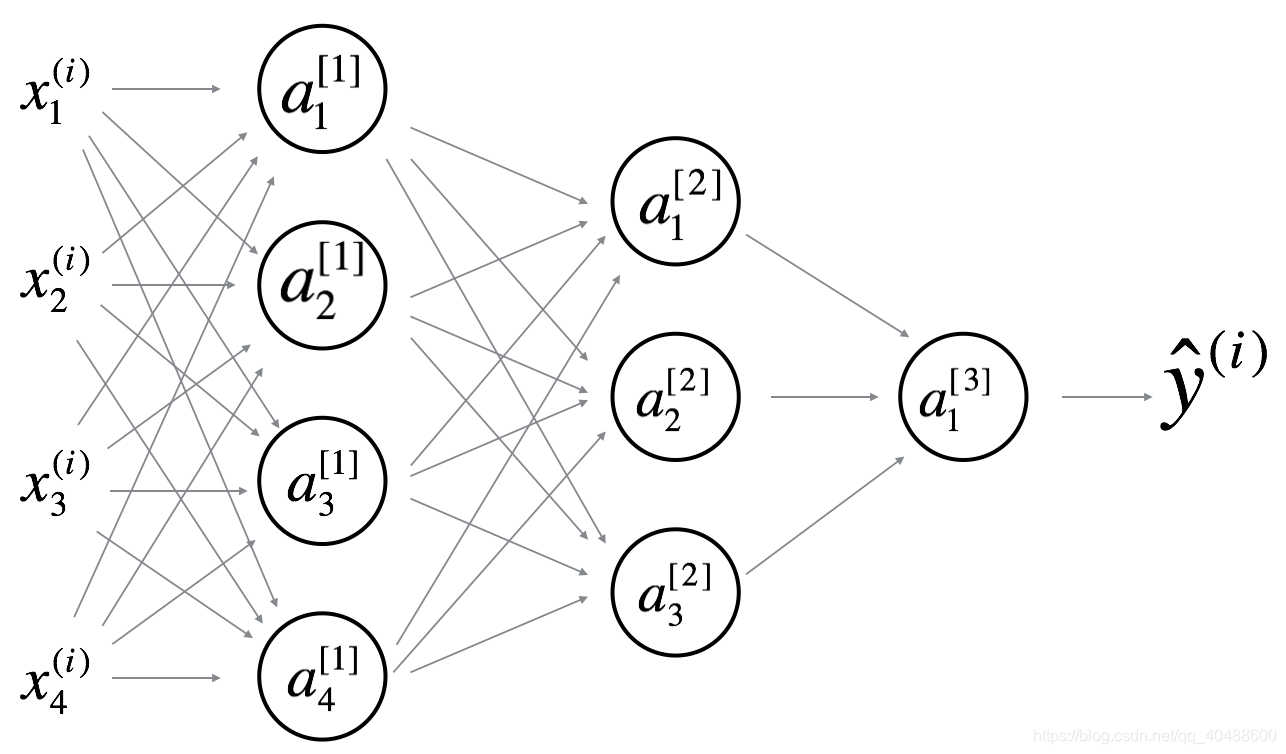
Which of the following statements are True? (Check all that apply).
will have shape (4, 4)
will have shape (4, 1)
will have shape (3, 4)
will have shape (1, 1)
will have shape (3, 1)
will have shape (1, 1)
两周还是三后内容了,反复看角标,注意对应关系ai=Wi*a(i-1)+bi
Whereas the previous question used a specific network, in the general case what is the dimension of , the weight matrix associated with layer l?
has shape (
,
)
})
同上题 【】第i层,()第几个示例,下角标第几个参数

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









