







前言:读者需在引擎&依赖及镜像安装的基础上,才可顺利使用蚂蚁所推出的产品。本文主要介绍通过案例介绍如何进行全局配置和知识库创建,以及后续的知识构建:包括知识建模、知识抽取和知识问答等。前文可参考:蚂蚁 KAG 环境部署、技术实践和全部复现(面向用户)-CSDN博客
目录
二、开启 openspg 服务端(KAG 是基于 openspg 的)
① 启动 openspg 服务端命令(上一篇文章讲过,不再重复:蚂蚁 KAG 环境部署、技术实践和全部复现(面向用户)_蚂蚁kag-CSDN博客)
② 查看状态是否开启,出现以下图标(Open-SPG)等标志,代表服务端开启成功:
⑤ 通过 pip 安装 SDK,这样可以通过 Python SDK 进行模型调用
五、KAG 项目案例实践 -hotpotqa(无实体类型关系知识图谱 schema)
六、KAG 项目案例实践-医疗图谱(有实体类型关系知识图谱 schema)
七、KAG 项目案例实践-黑产挖掘(事件图谱 schema)
一、蚂蚁 KAG 开发环境搭建
① 安装 python 虚拟环境
conda create -n kag-demo python=3.10 && conda activate kag-demo
② 代码 clone
git clone https://github.com/OpenSPG/KAG.git③ 进入项目根目录即 ./KAG,进行安装
cd ./KAG && pip install -e .
④ 验证是否安装成功
knext --version
knext --help
二、开启 openspg 服务端(KAG 是基于 openspg 的)
① 启动 openspg 服务端命令(上一篇文章讲过,不再重复:蚂蚁 KAG 环境部署、技术实践和全部复现(面向用户)_蚂蚁kag-CSDN博客)
# service start
docker-compose -f docker-compose-west.yml up -d
② 查看状态是否开启,出现以下图标(Open-SPG)等标志,代表服务端开启成功:
docker ps
docker logs -f release-openspg-server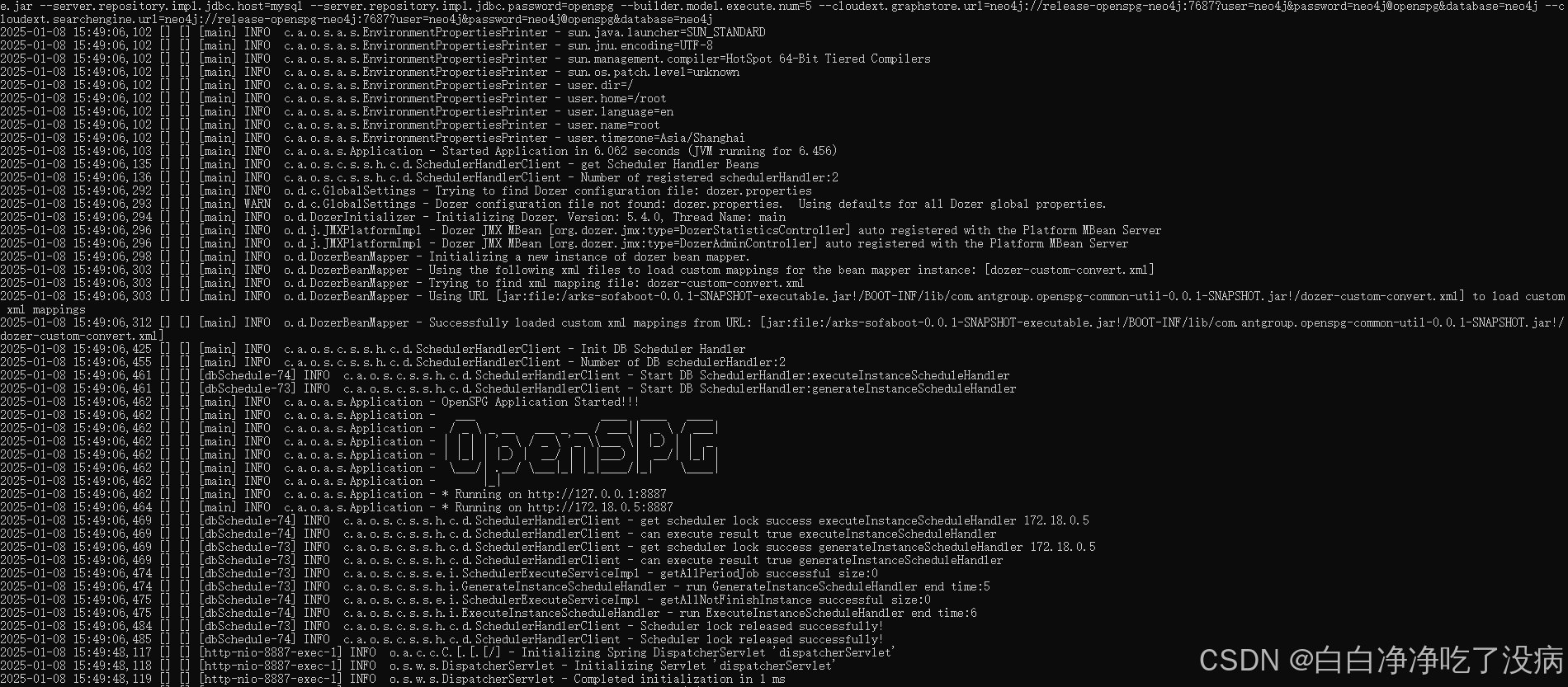
三、开通 API 服务,进行全局配置(大模型、数据库等)
登录后,进入全局配置:
# Default login information:
# Username: openspg
# Default password: openspg@kag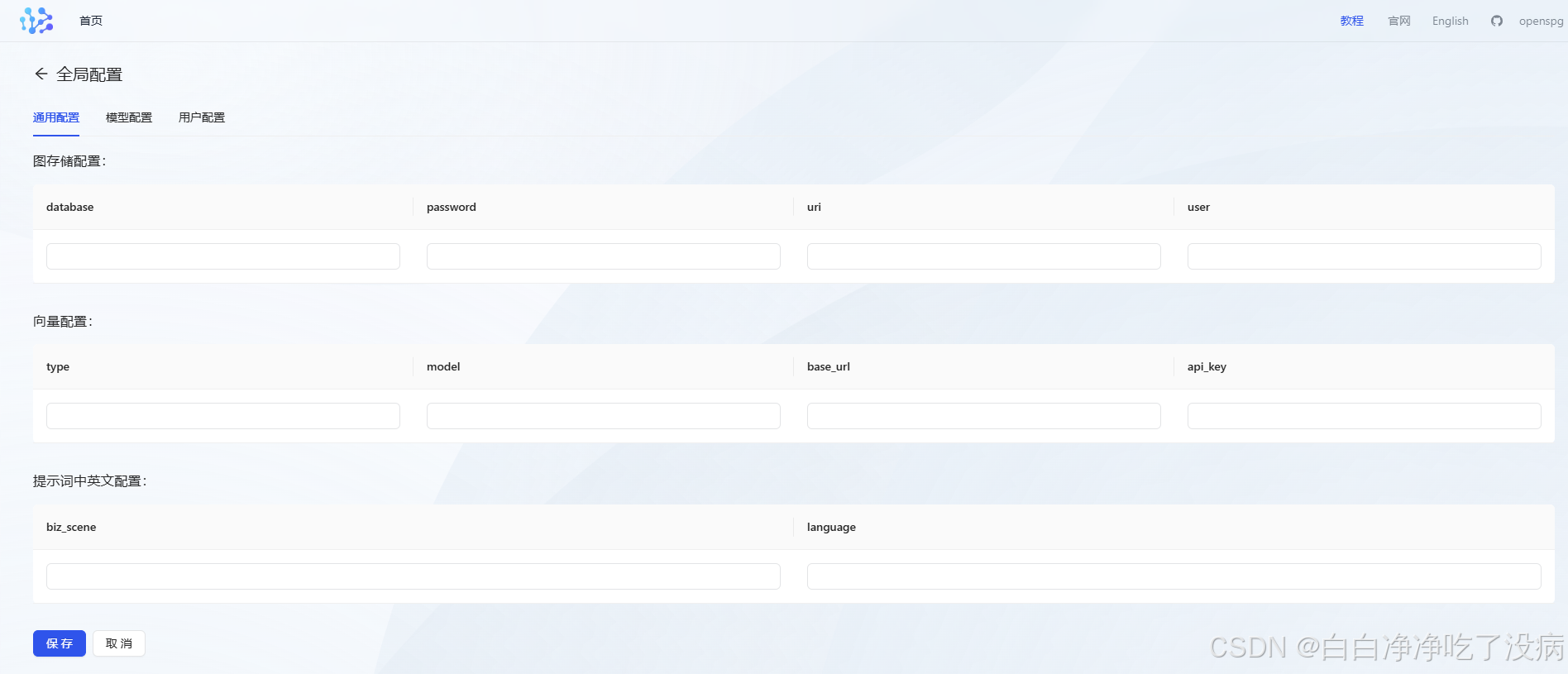
① 图存储配置
我用的是 openspg-neo4j 图存储数据库(也可以不用docker里边的neo4j,参考我之前的博文本地配置:使用 Neo4j 图数据库可视化(网络安全)知识图谱_neo4j知识图谱可视化-CSDN博客):
按照以下用户名密码直接填入到全局配置中(记得保存):
{
"database":"neo4j", # default database name, which will be replaced by namespace of knowledge base
"uri":"neo4j://release-openspg-neo4j:7687", # neo4j server address, which can be replaced by customized neo4j server which is accessbile
"user":"neo4j", # neo4j username, default to neo4j
"password":"neo4j@openspg", # neo4j password, default to neo4j@openspg
}
② 向量配置(即表示模型配置)
KAG 支持 OpenAI 兼容类接口的表示模型服务,如 OpenAI、硅基流动等。开发者可自行前往 硅基流动官网、openai官网等网站,提前完成账户的注册以及模型服务的开通,并获取 api-key,填入到后续的项目配置中。KAG 也支持对接 ollama、xinference 等提供的表示模型预测服务,详情可参考模型服务相关章节。
这里我使用的是硅基流动 (SiliconFlow),需要开通 API 服务(硅基流动统一登录):
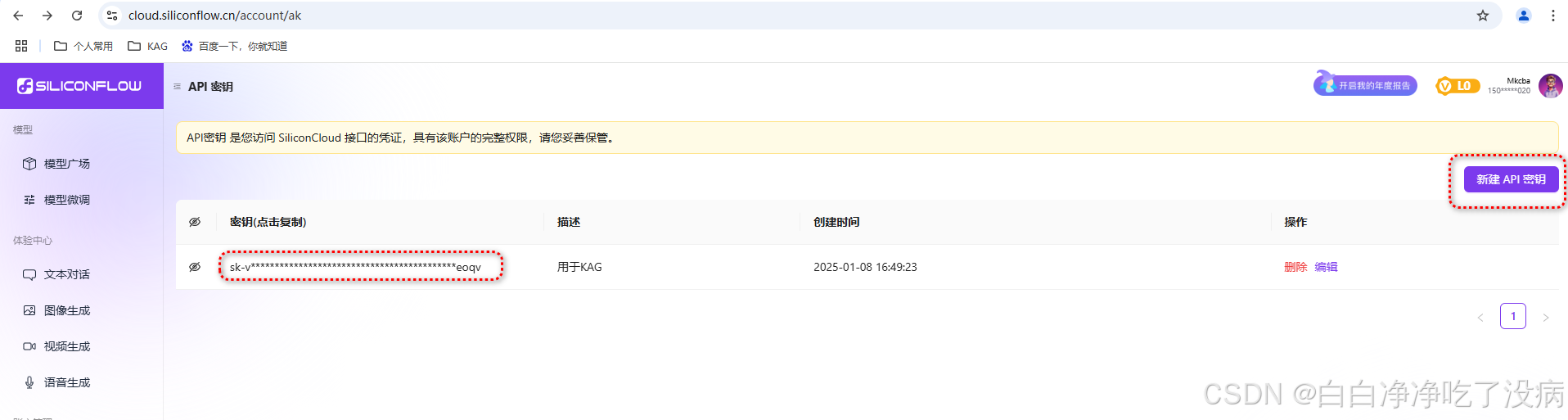
{
"type":"openai", # KAG supports openai compatible interface of embedding service
"model":"BAAI/bge-m3", # model name of embedding service
"base_url":"https://api.siliconflow.cn/v1", # url of embedding service
"api_key":"your api key"
}将以上对应填入网站中对应表格即可:

③ 提示词中英文配置
用于决定调用模型时,使用中文还是英文,按照以下提示直接填入即可:
{
"biz_scene":"default", # biz_scene for kag template
"language":"en", # en for english and zh for chinese
}
前三个配置好后,点击保存!
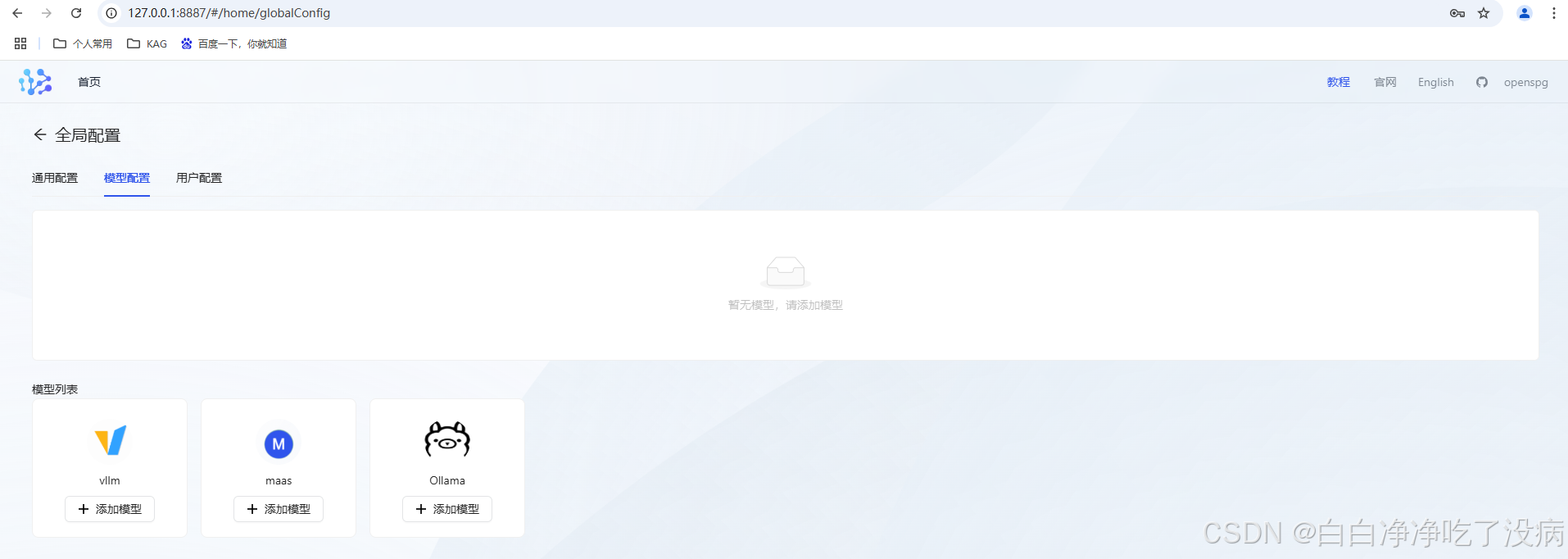
④ 大模型配置
KAG 支持 Open-AI 兼容的生成模型 API (如 chatGPT、deepseek、qwen2),支持 ollama、maas、vllm,点中间那个:
我这里用的是 DeepSeek:
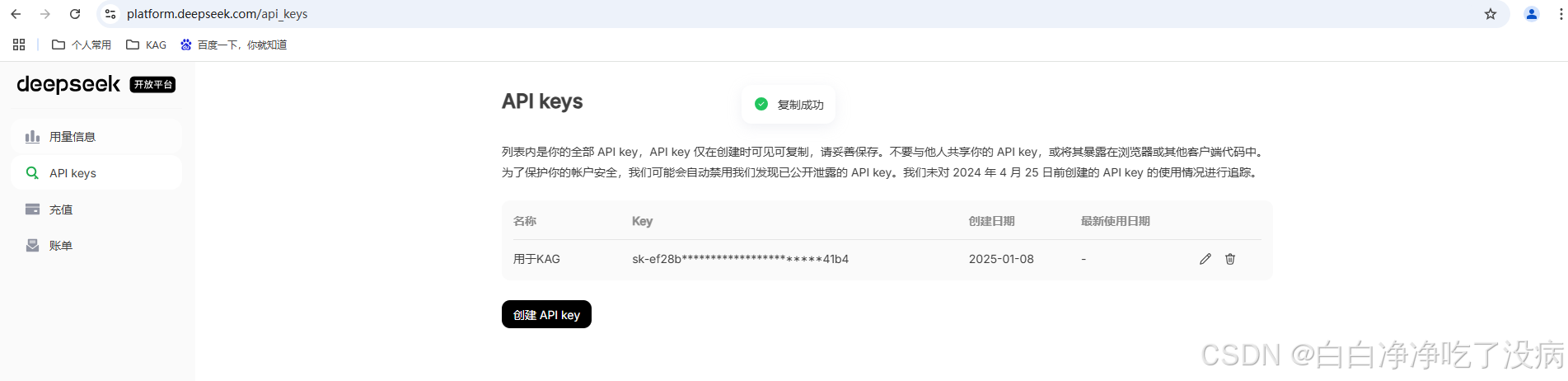
选择中间的 mass,对应 API 文档说明进行填入 :
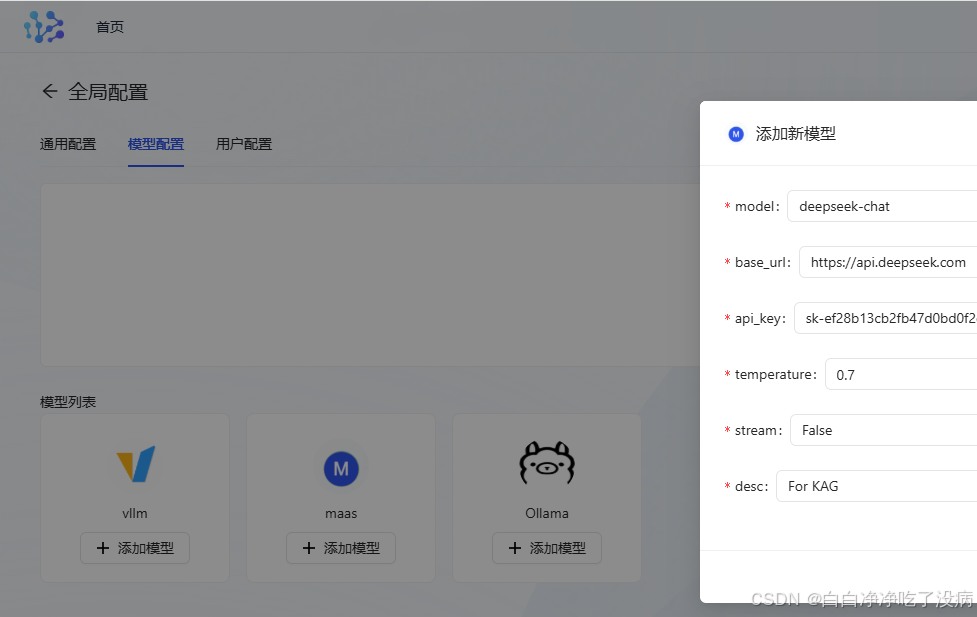
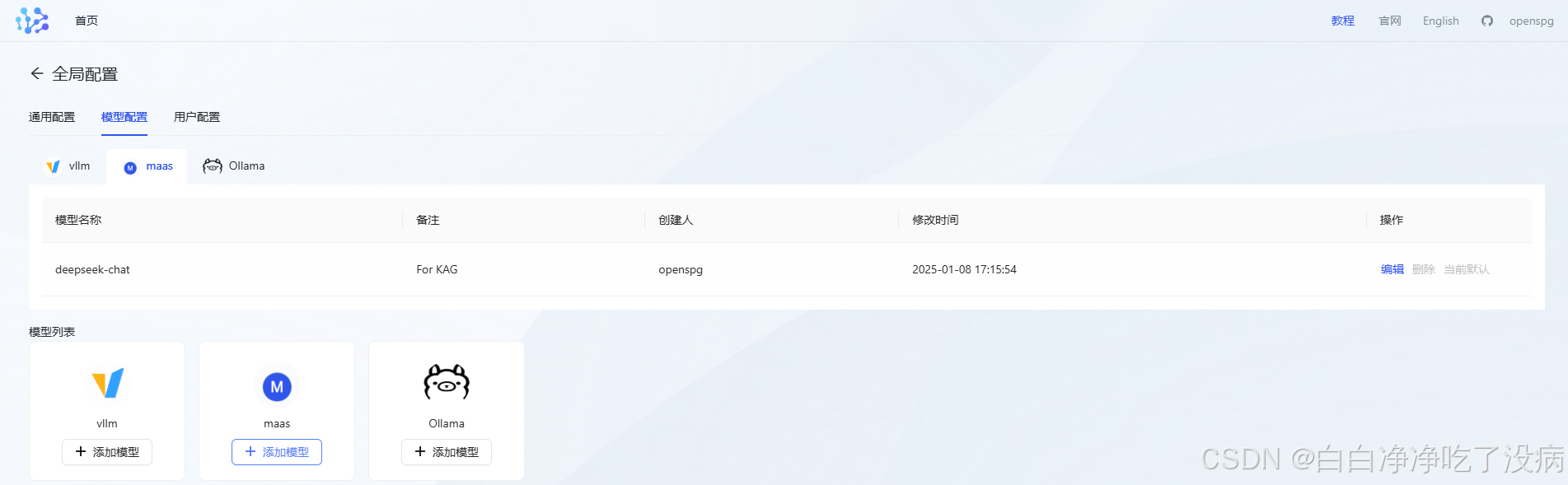
点击确定,就配置好了:
⑤ 通过 pip 安装 SDK,这样可以通过 Python SDK 进行模型调用
pip install dashscope
⑥ 安装 OpenAI Python 库。从终端/命令行运行,确认 OpenAI Python 库已成功安装。 之后可以直接通过 OpenAI 的相关接口进行调用,目前平台支持 OpenAI 相关的大多数参数
pip install --upgrade openai
四、创建和构建知识库,实现 KAG 知识关联展示及推理问答
① 创建知识库及相应的配置
可以针对特定新创建的知识库使用上述的全局配置,也可以重新自定义配置:

可以使用默认配置,但默认数据库名称会新起的知识库的名称所替换:
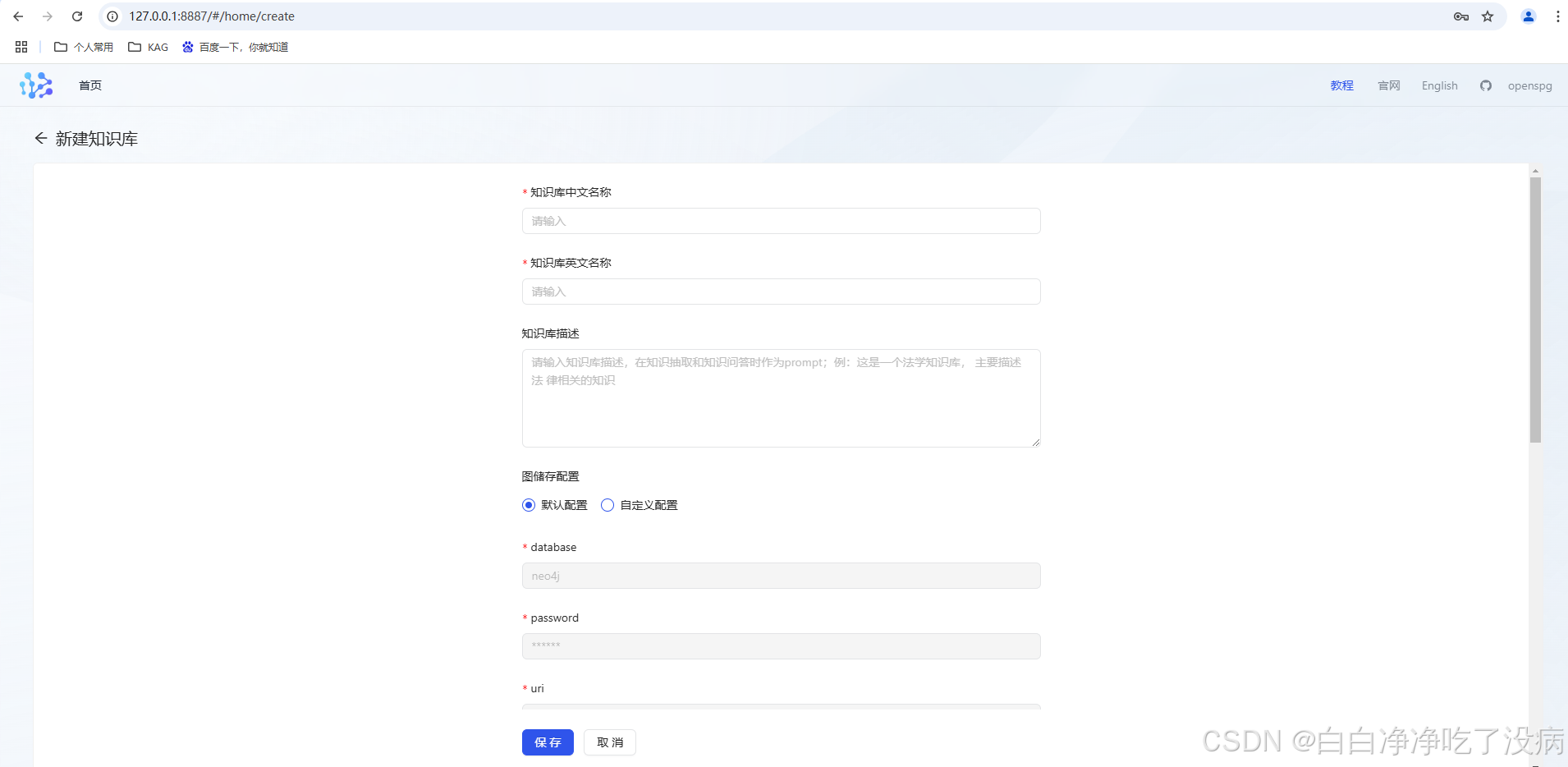
官方教程中有一个提示需要注意:

于是,我跟着创建一个知识库:
知识库名字:Zturbo9921,调用模型时用自定义改为了英文:en,其他均使用的时全局配置。
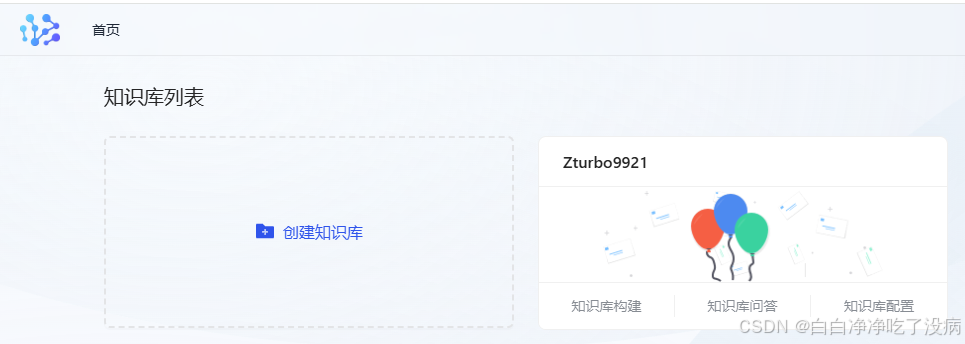
有时候会提示名字已存在或超时,但实际已创建成功,直接返回首页即可!
此处的 bug 已不想吐槽,成功界面如上图所示!
等以上配置搞定后,打开 Neo4j Browser 填入用户名和密码:
"user":"neo4j"
"password":"neo4j@openspg"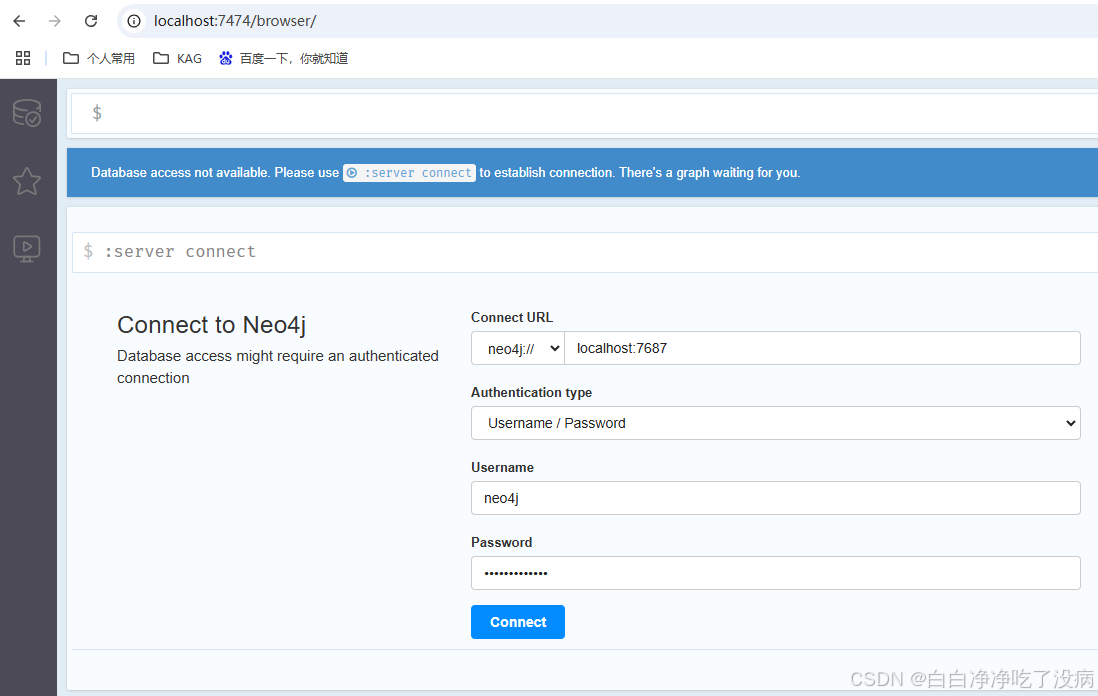
登录进去就可以看到同名数据库(zturbo9921)了(说明:知识库的名字会覆盖掉之前全局配置中给数据库起的名字):
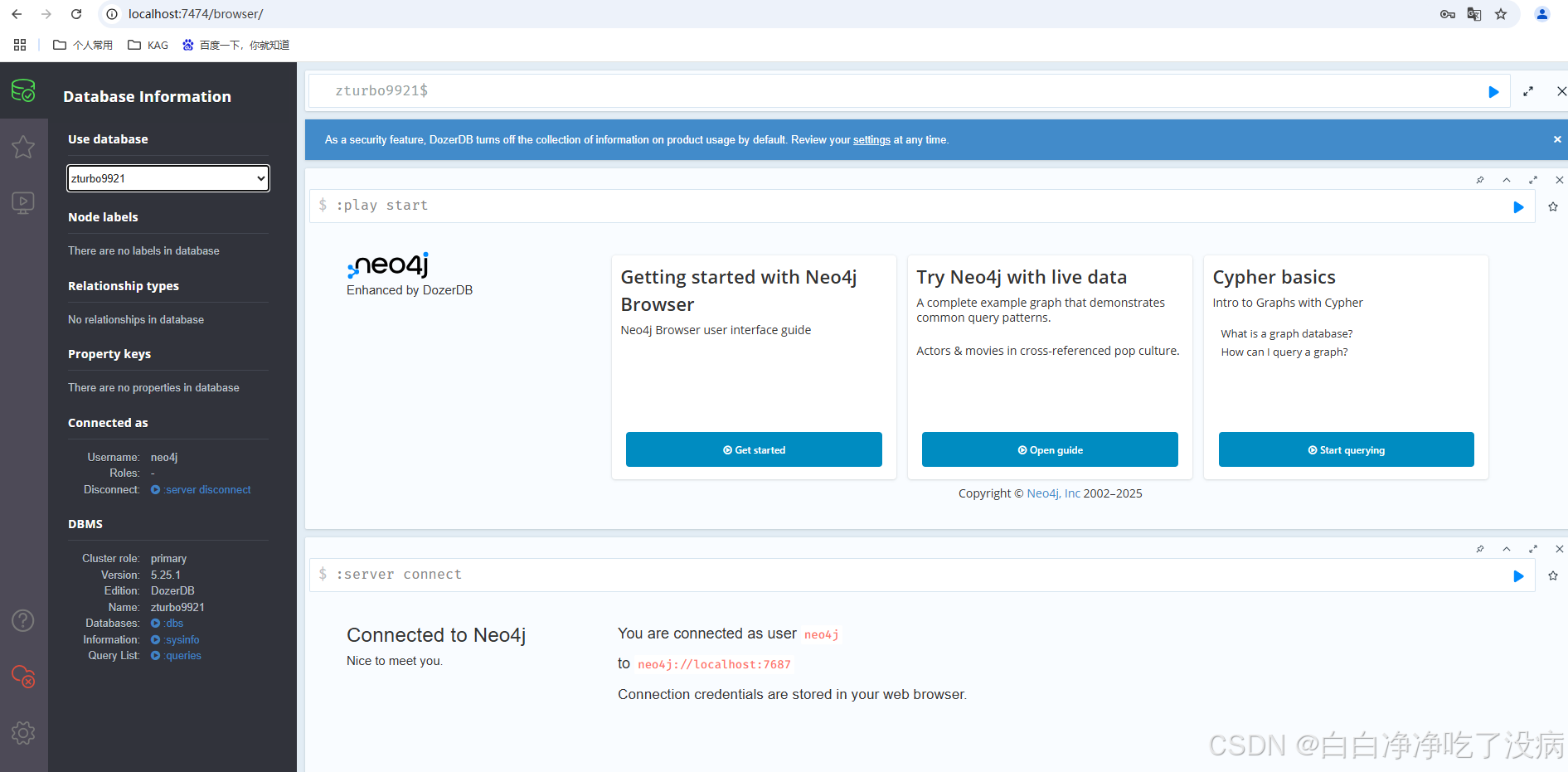
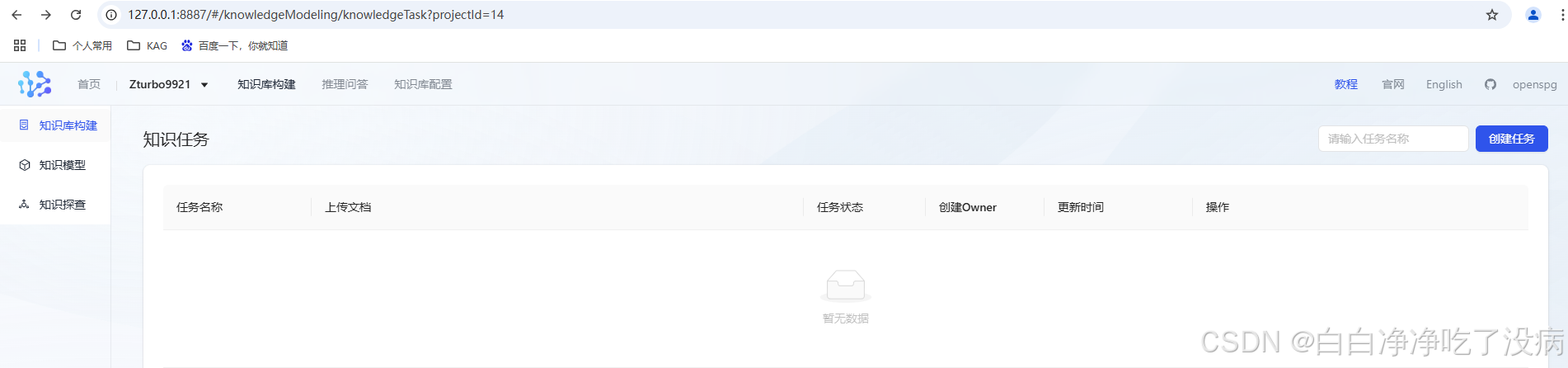
② 构建知识库,上传文档实现知识抽取及众多功能
点击知识库构建,可以进入这个项目的知识库构建阶段:
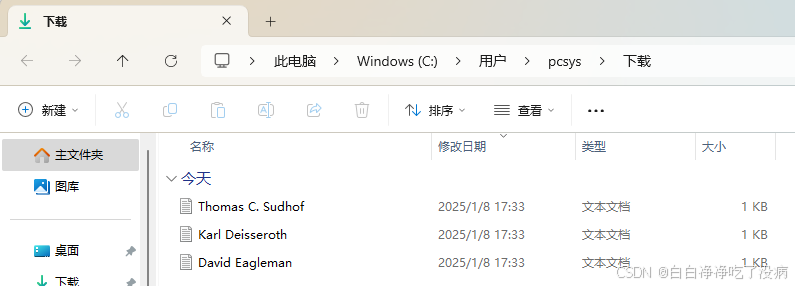
点击右上角创建任务,上传官方给定的三个文件,进行知识抽取:
Enter the knowledge base Build => Create task to initiate knowledge building tasks. Users can download sample files 📎David Eagleman.txt 📎Karl Deisseroth.txt 📎Thomas C. Sudhof.txt
点击右上方创建任务,依次上传这三个文件:
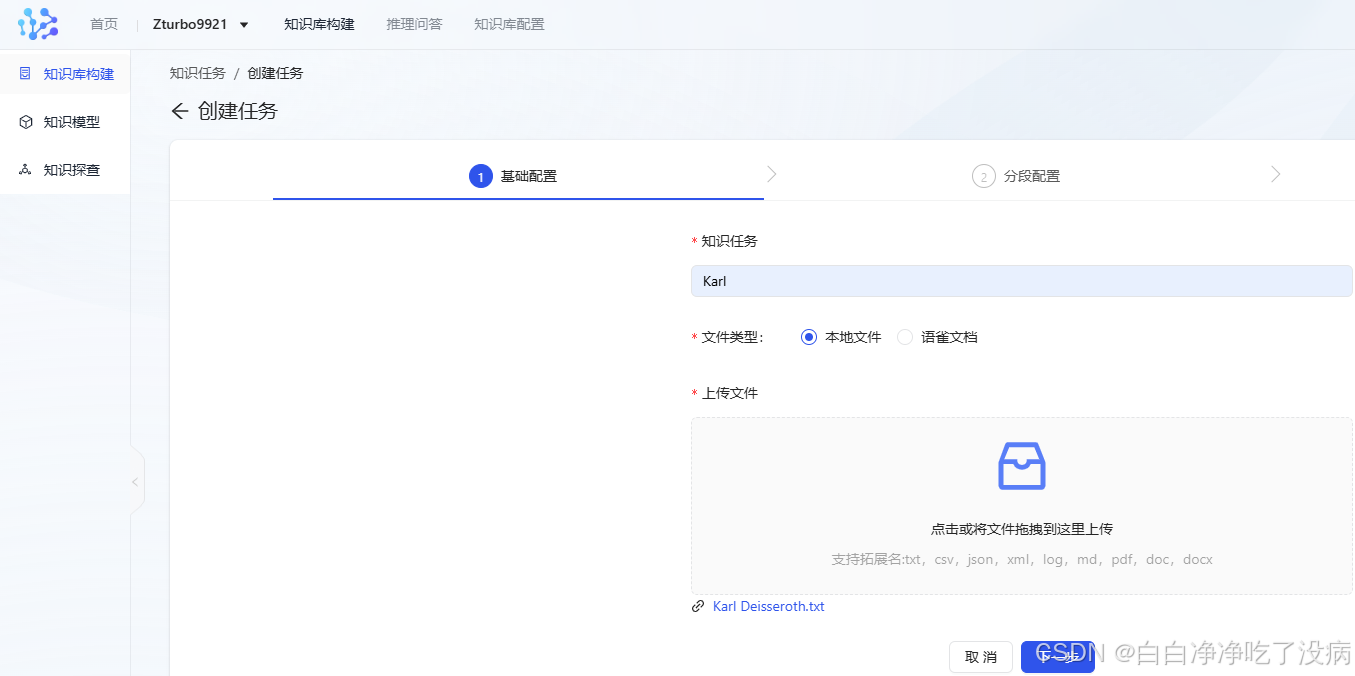
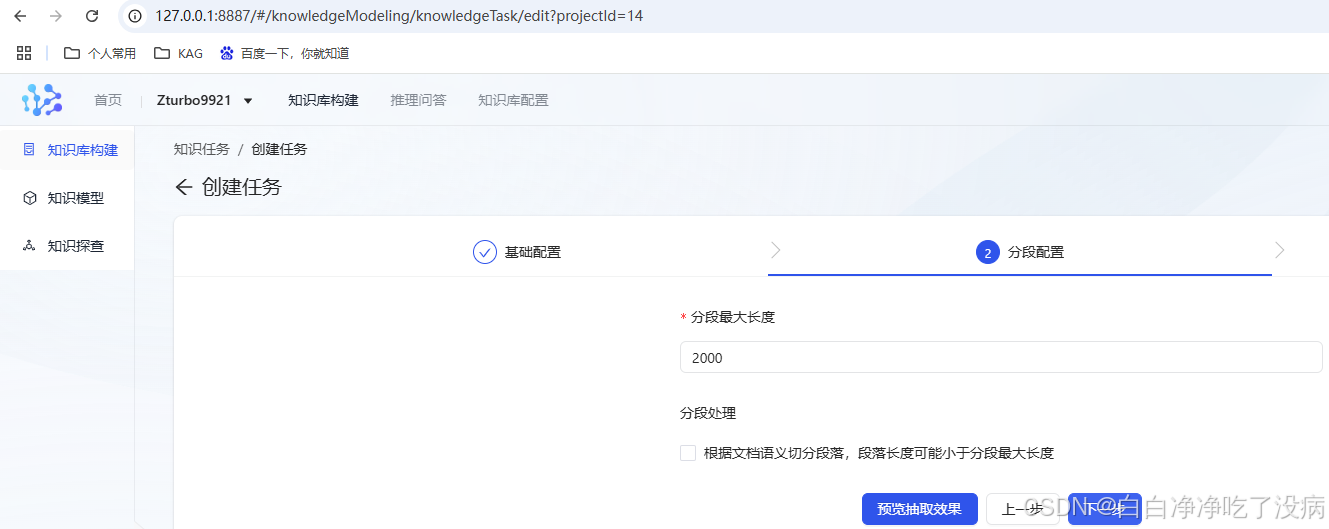
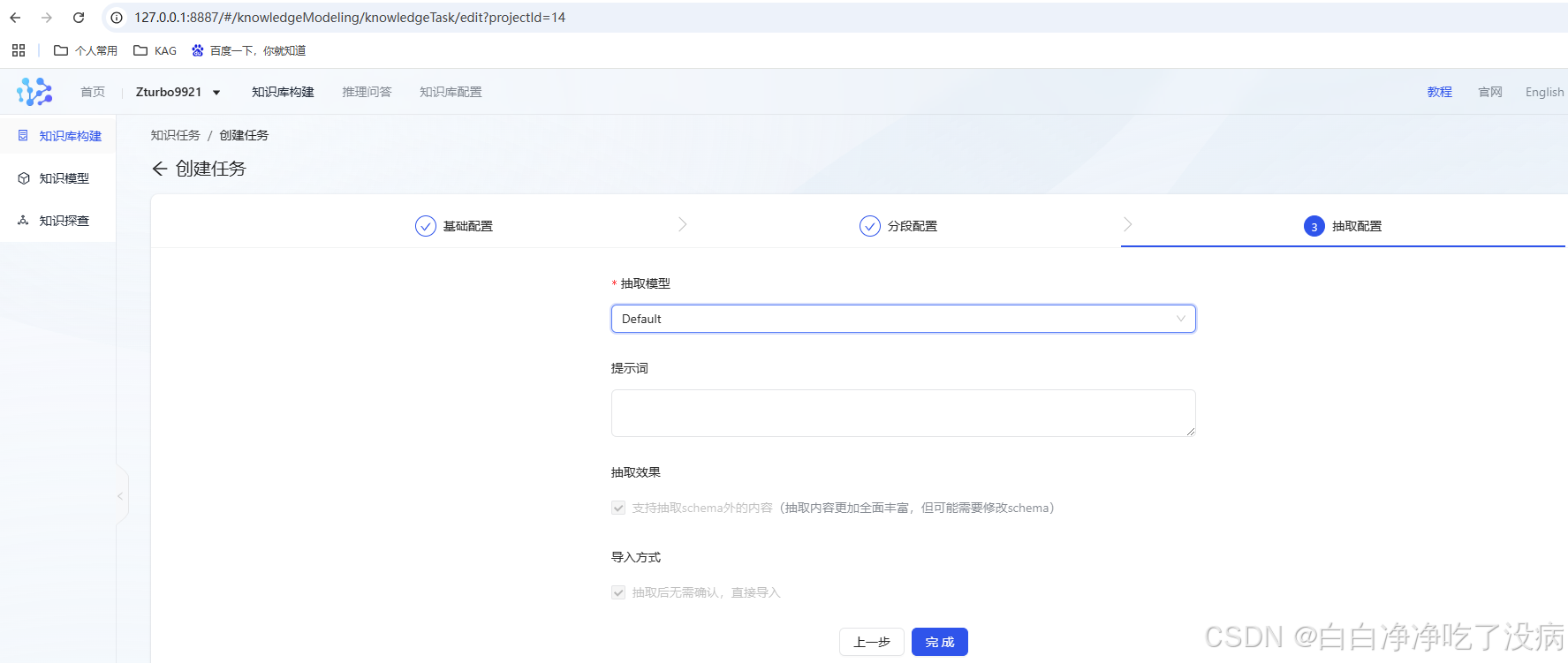
然后点击完成:
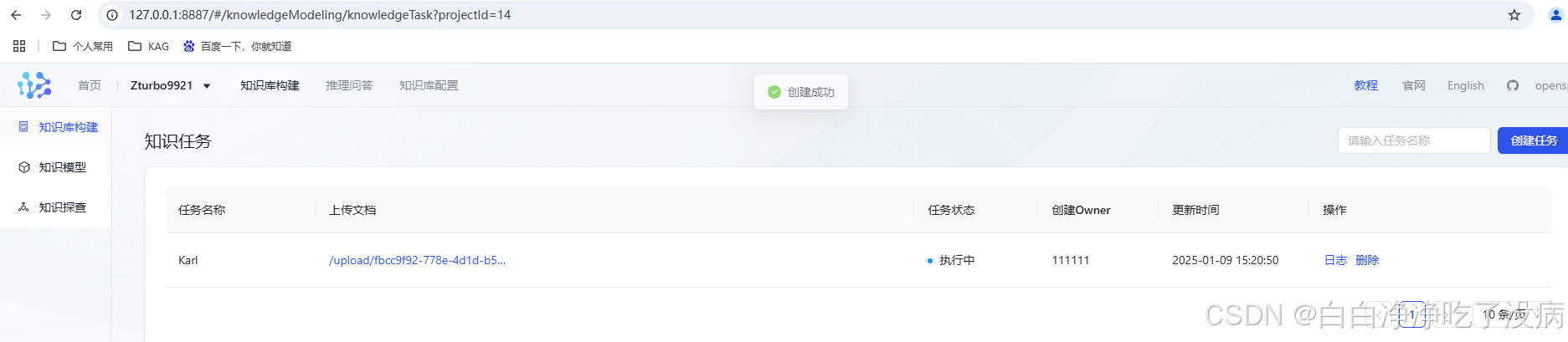
另外两个文件同理不赘述,全部成功上传后界面如下所示:

这个过程需要等挺长时间,因为要分割、抽取、向量化、对齐等操作,相当耗时:
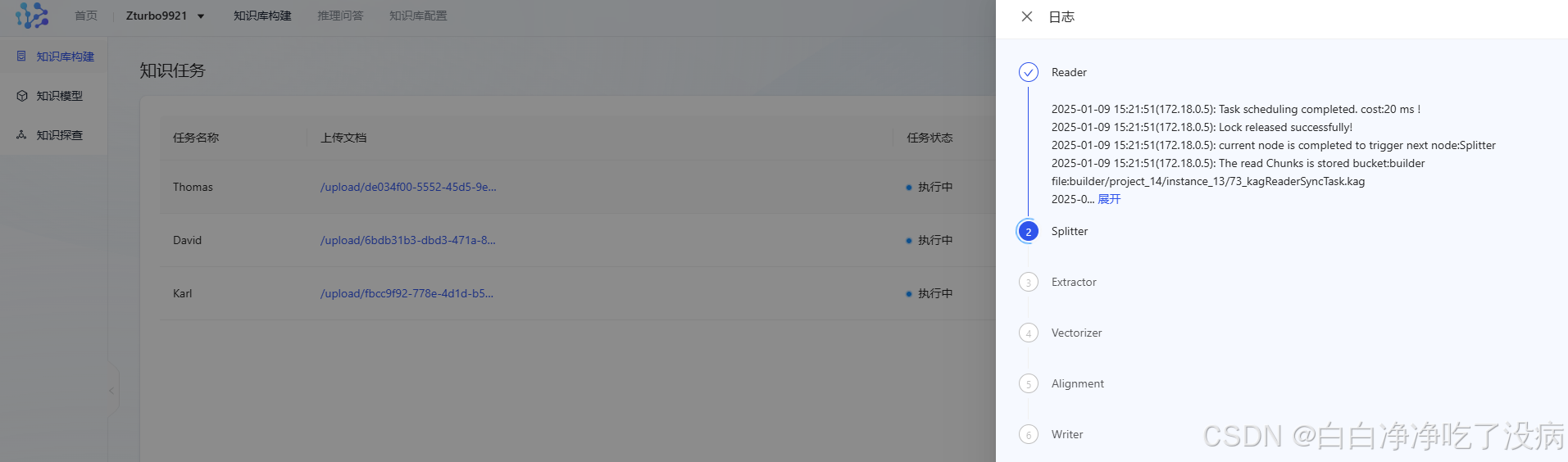
抽取完成后状态会转变,可以实时看到处理状态,直到完成:
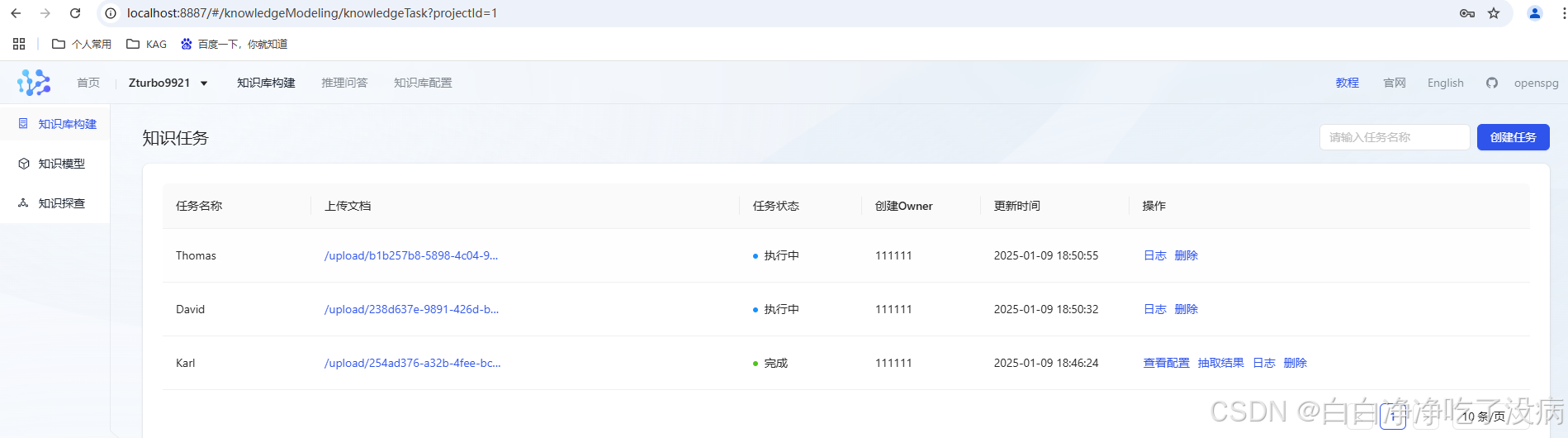 最终结果如下图所示:
最终结果如下图所示:
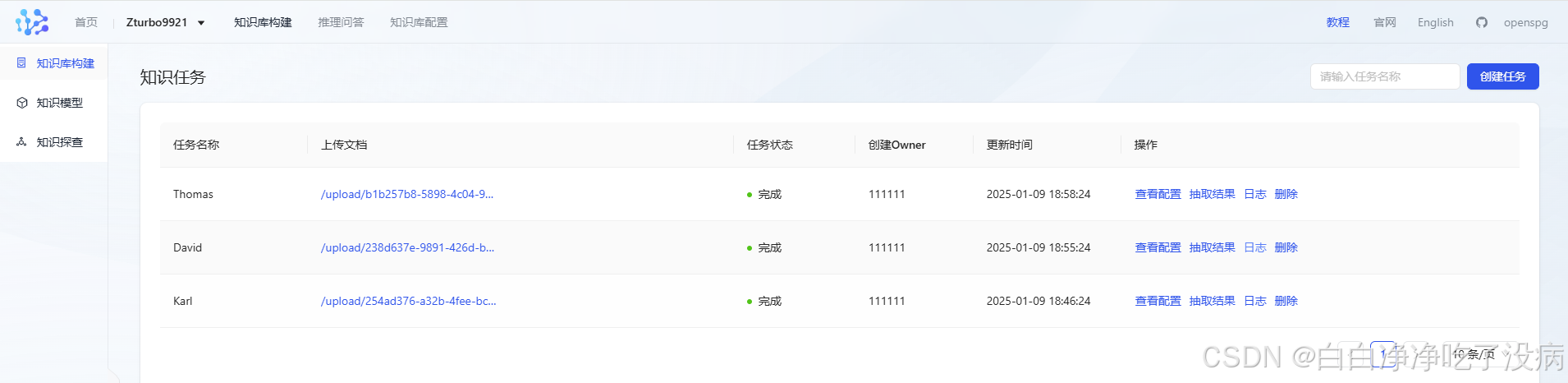
③ 知识抽取和展示
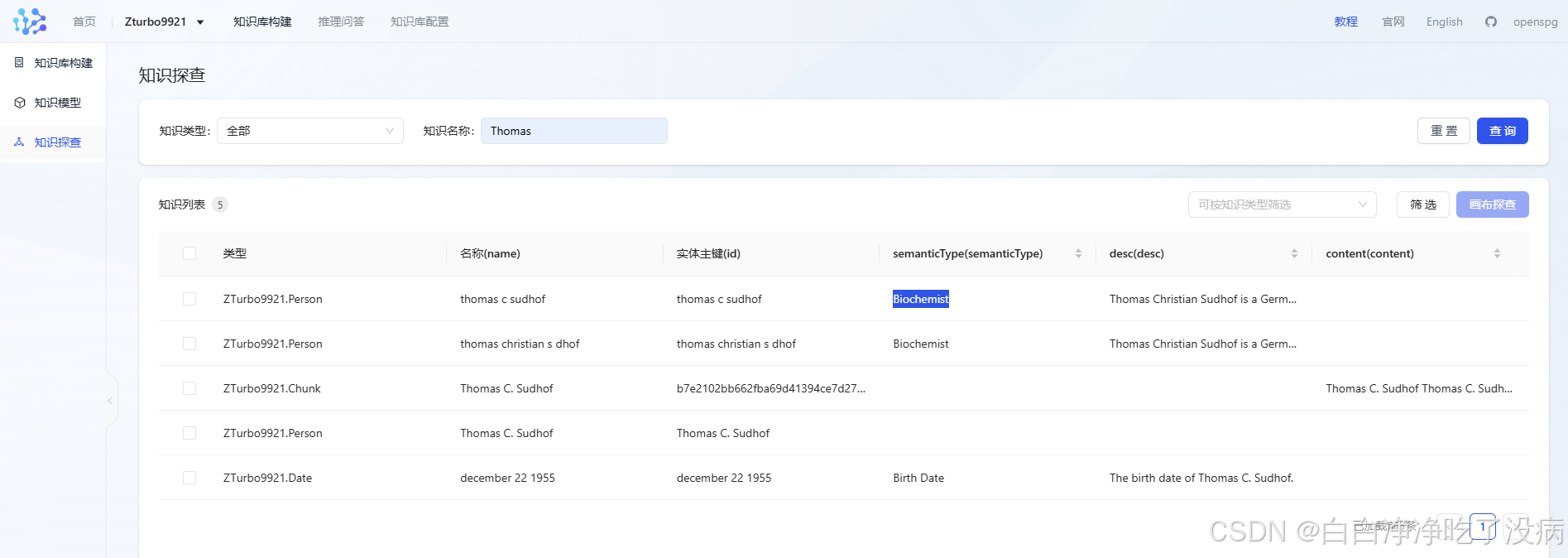
点击左侧栏的知识探查(第三个),随意搜索 Thomas,可以检索以下表格:
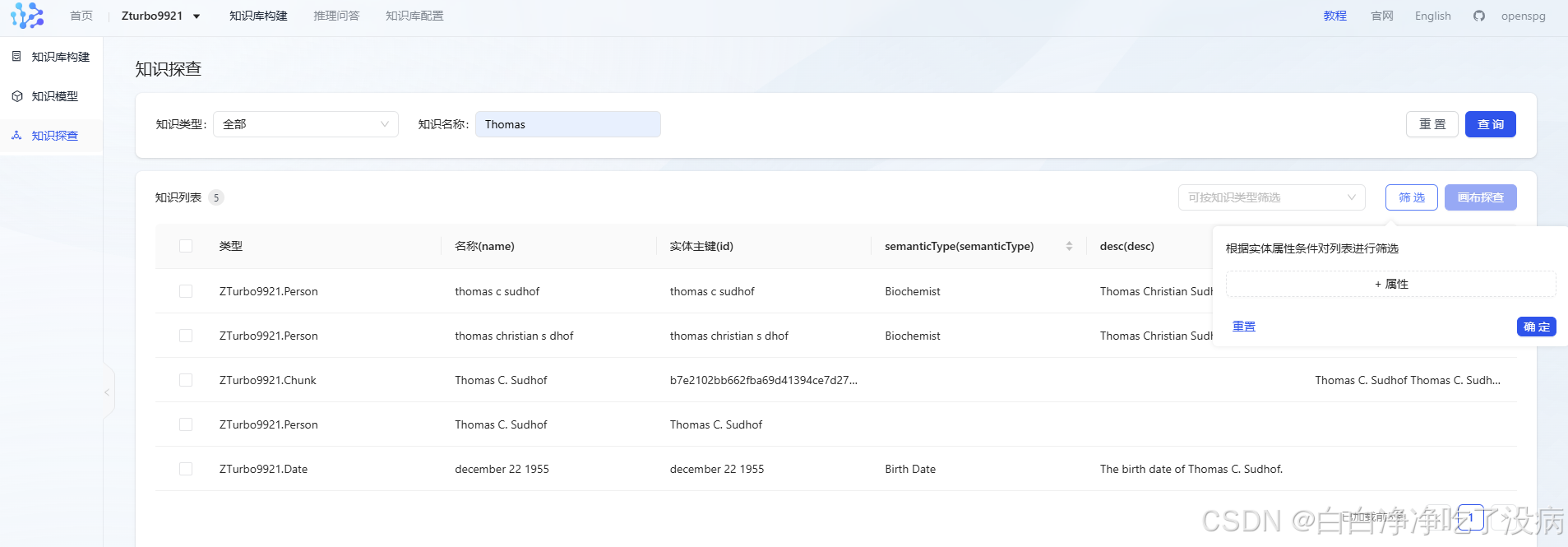
也可以根据属性进行筛选:
点击和选中其中的一个人,点击画布探查,可展示完整的知识图谱及关系链接:
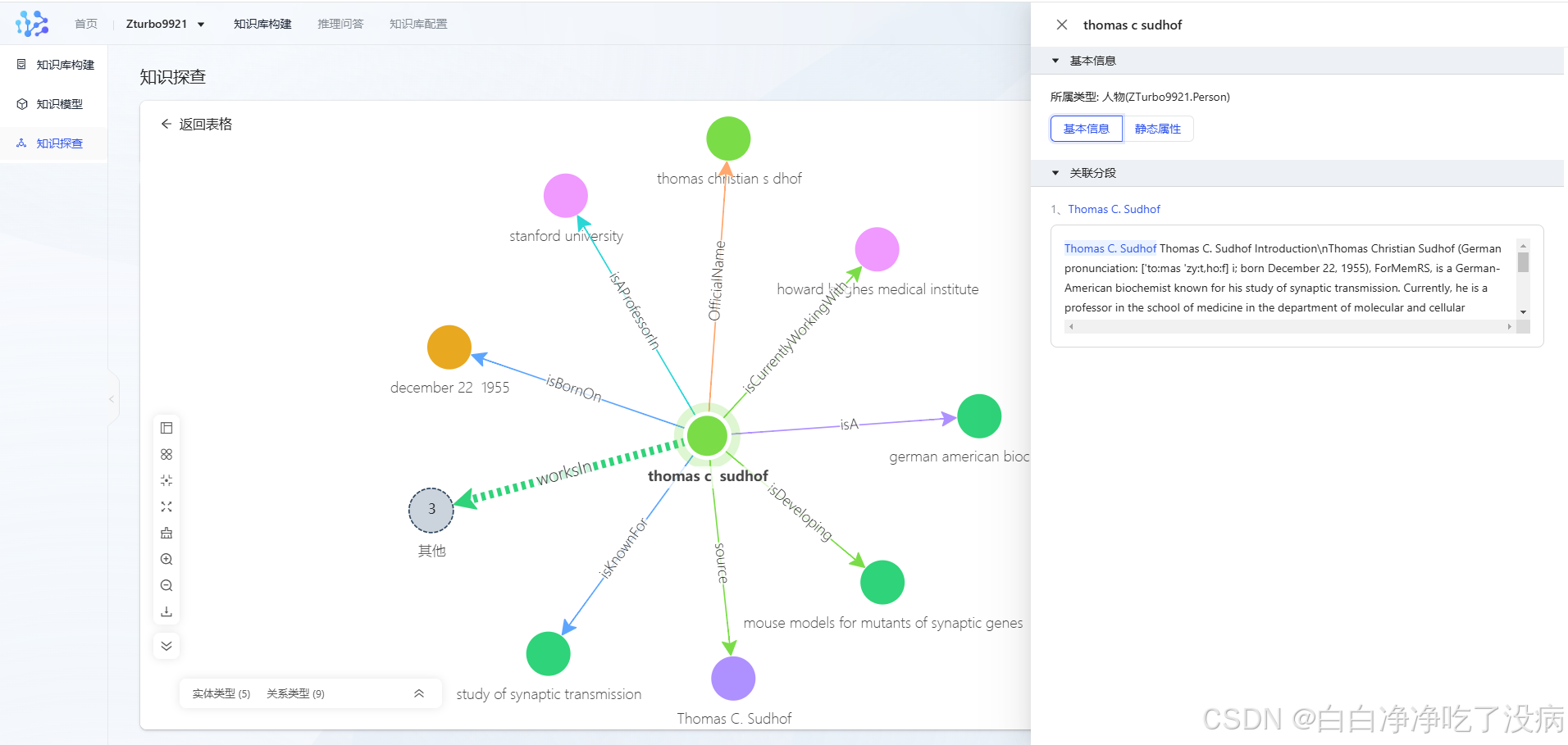
此外,可以看到对应的知识模型及详细的描述信息:
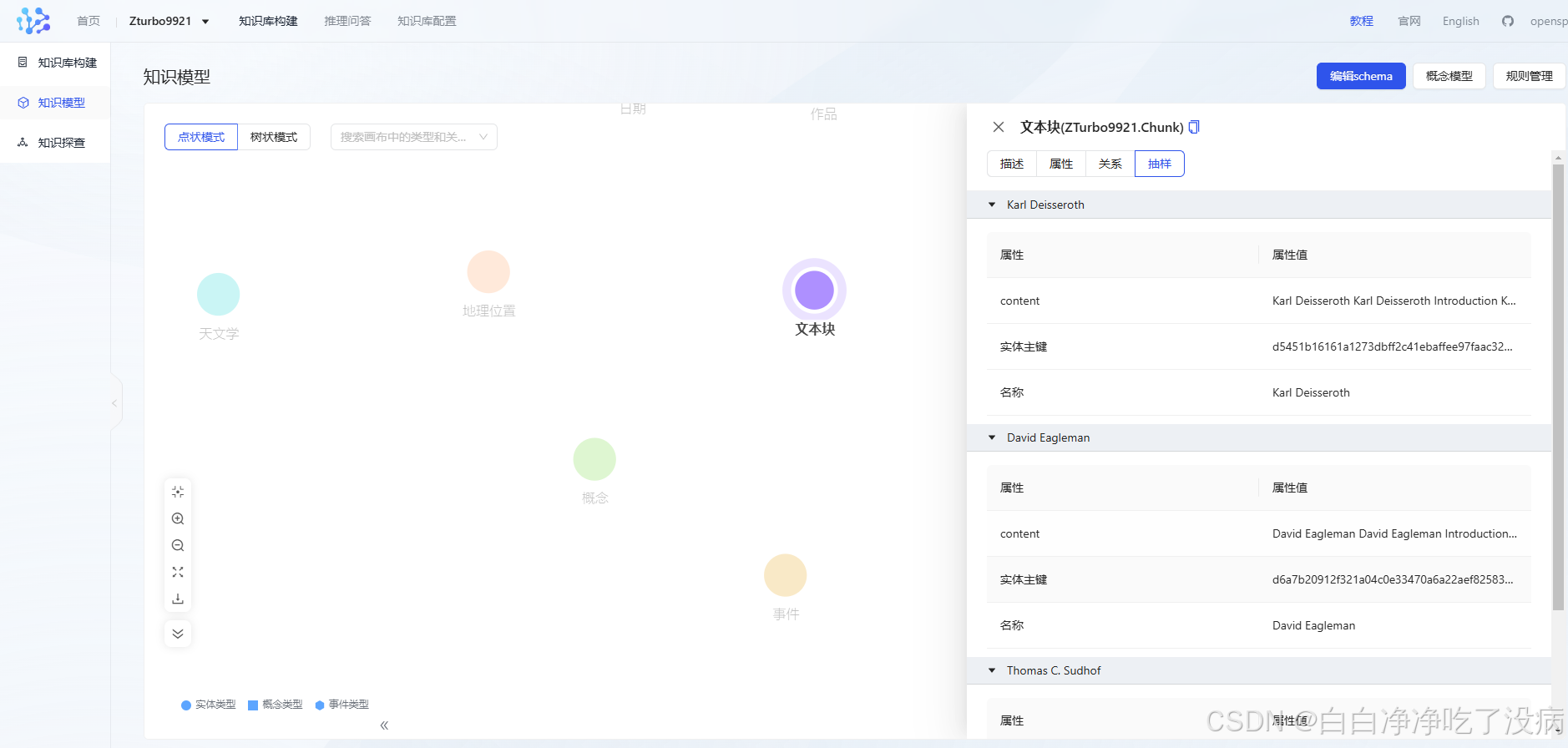
④ 知识推理和问答
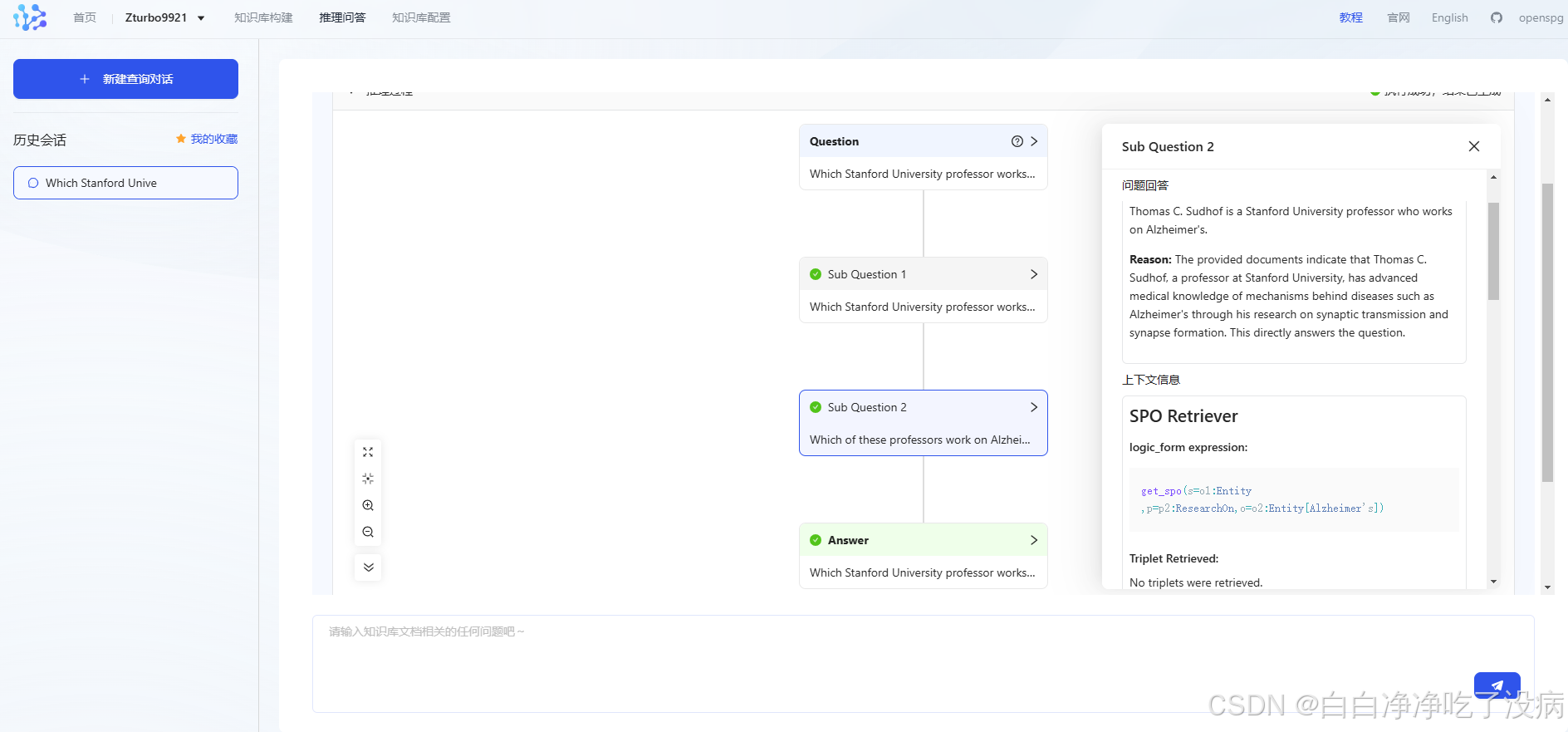
输入问题:Which Stanford University professor works on Alzheimer's?
输入后,上述问题会自动拆分成若干子问题,并逐个给出回答:
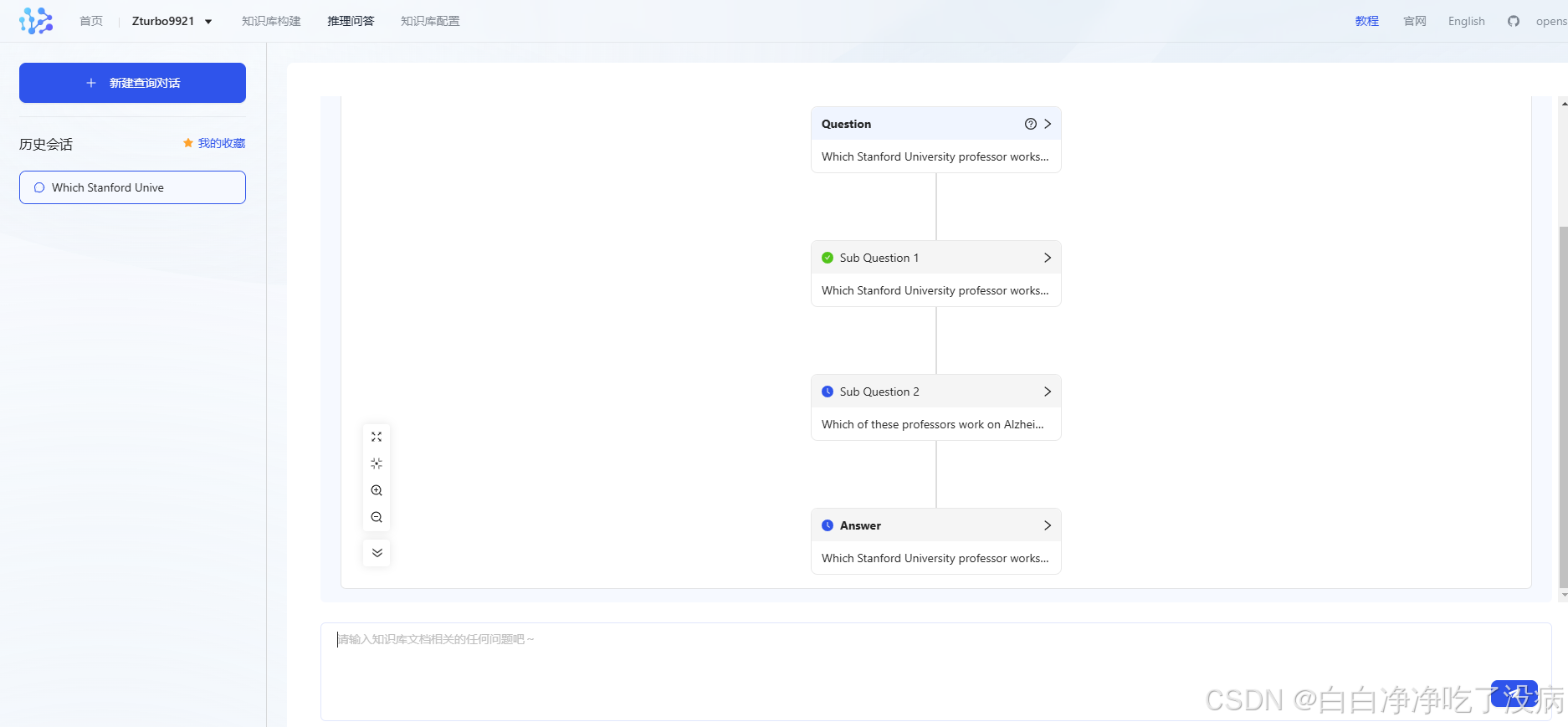
最后,最终会返回给出源问题的回答:
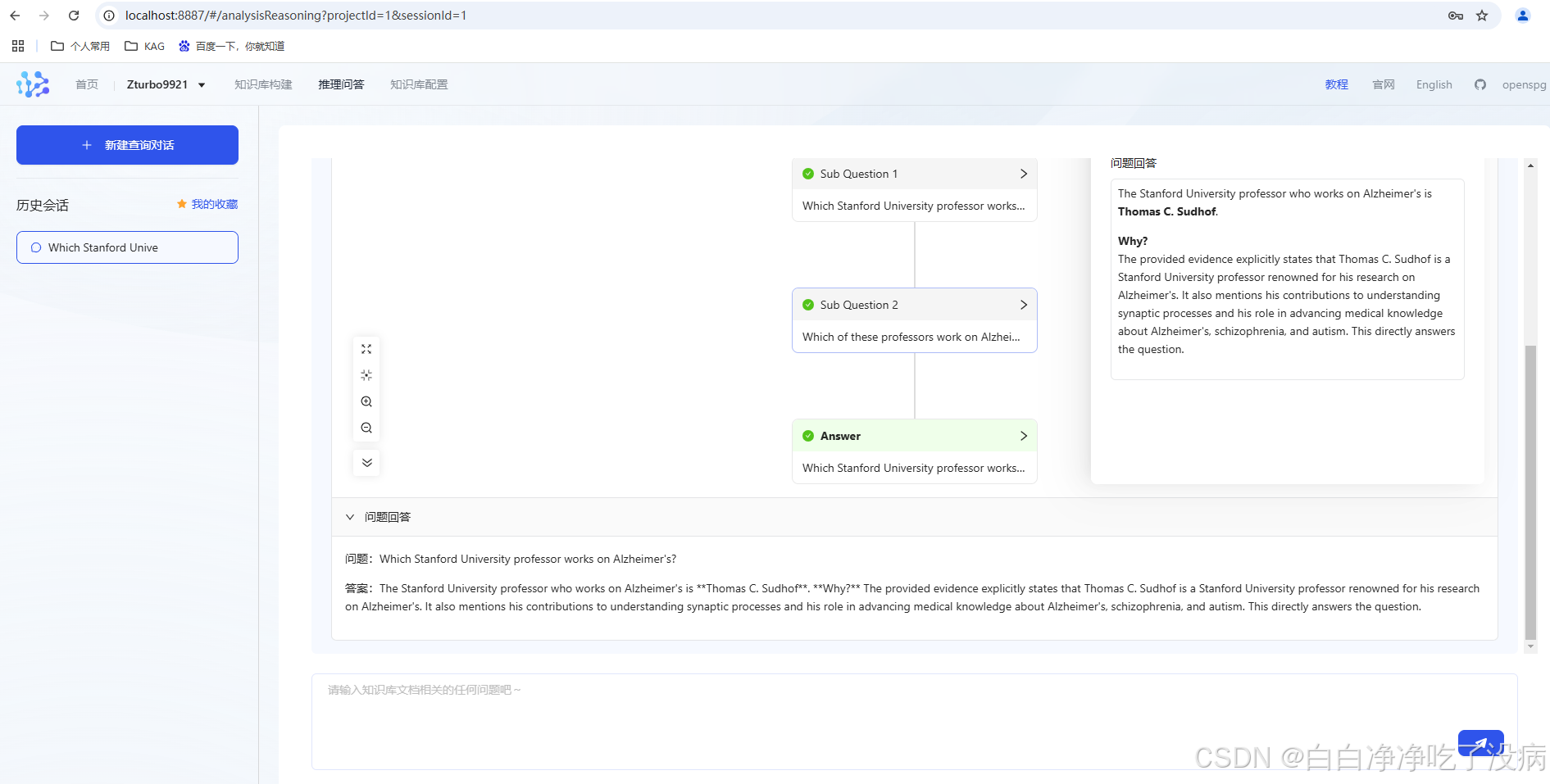
此外,还可以查看每个子问题的答案,以及原因和上下文信息:
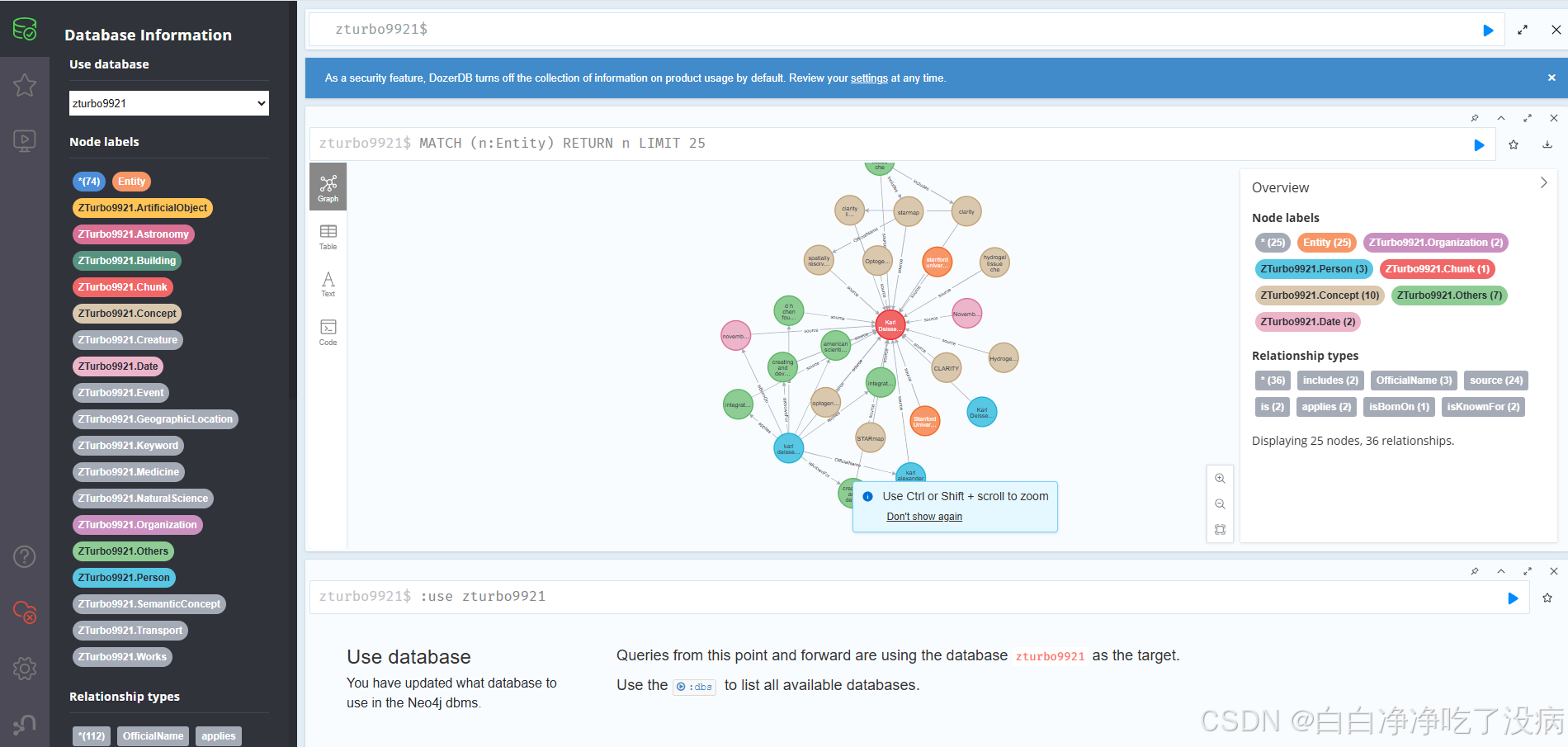
⑤ 通过 Neo4j 来看 KAG 中的知识关联等原理
除了在 OpenSPG 平台,也可以通过 Neo4j 更加直观地来查看和分析导入的文本数据(http://localhost:7474/browser/):
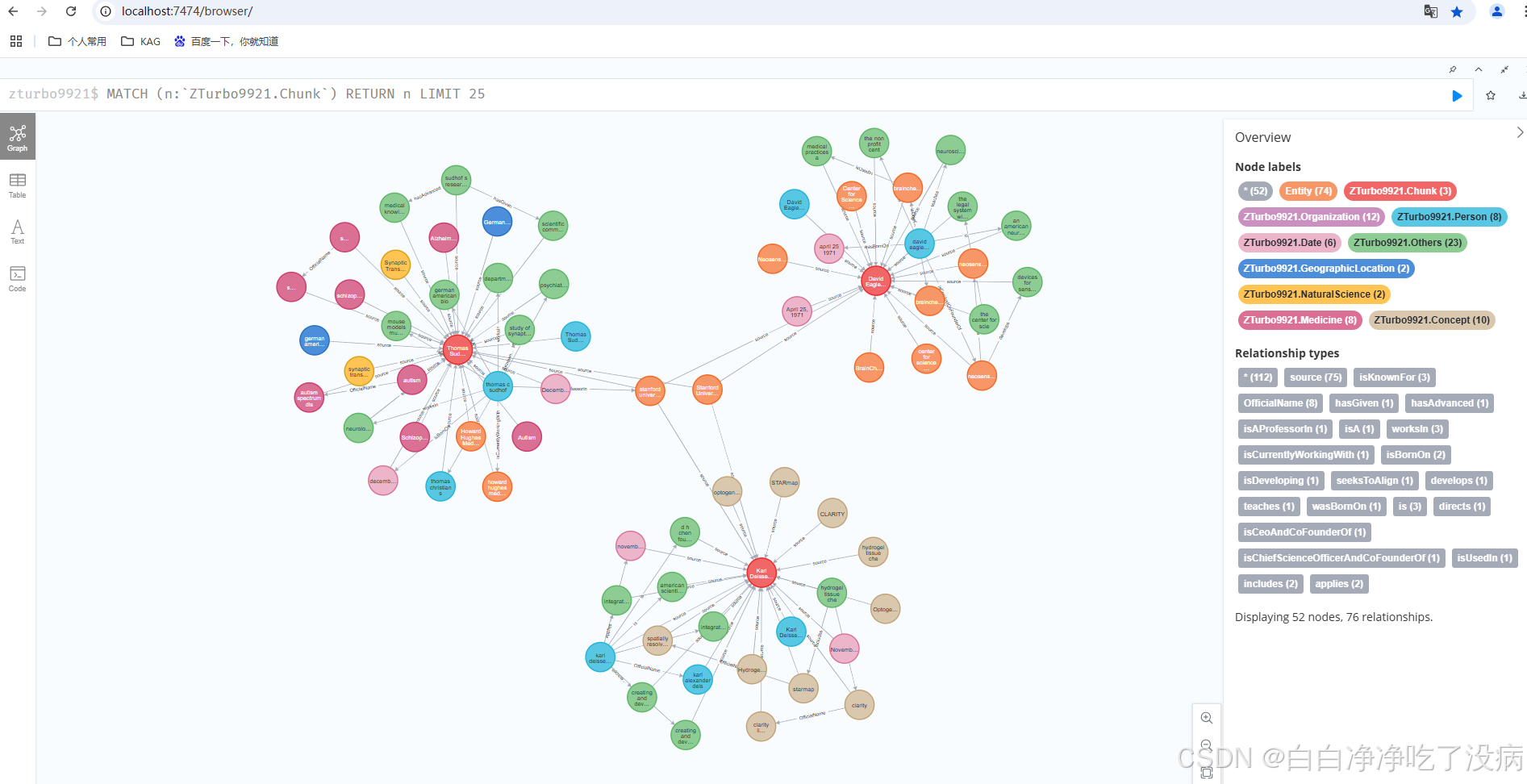
点击左侧栏的 chunk,即语义块(共三个,对应导入的三个文档),可以分别从整体看到这三个语义块之间的关联,以及实体与实体之间的关联。知识图谱中每一种颜色代表一类,非常直观:
以下三个案例是 2024.1.7 之前项目没有更新至 V0.7版本时的复现,粗略介绍带过:
五、KAG 项目案例实践 -hotpotqa(无实体类型关系知识图谱 schema)
① 进入案例目录
cd kag/examples/hotpotqa/
② 项目初始化
knext project restore --host_addr http://127.0.0.1:6008 --proj_path .上述命令是报错的:

需要改为命令:
knext project restore --host_addr http://183.220.37.57:6008 --proj_path .
③ 知识建模
knext schema commit
由于服务端的 Schema 和提交的 Schema 一致,因此会出现上述警告(不用担心,在修改好自己的 Schema再提交时,就不会有这种情况了)。
上述命令完成后,可以在前端 http://183.220.37.57:6008/ 中,选择 HototQA,从而查看 schema 效果:


④ 知识抽取构建(需要开 VPN)
首先需要更改配置文件:
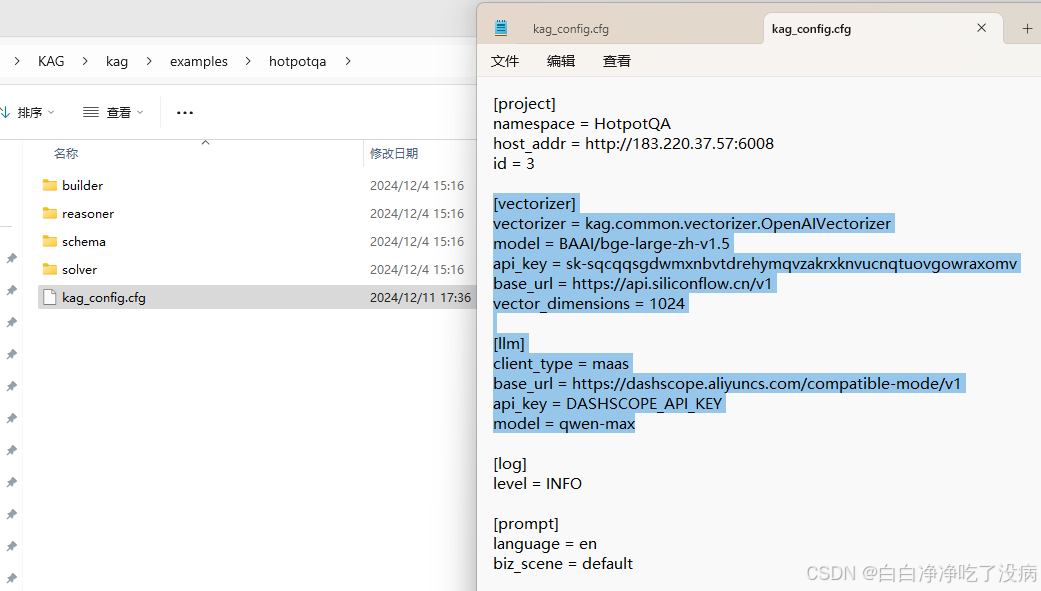
python ./builder/indexer.py上述命令完成后,可以在前端 http://183.220.37.57:6008/ 中,选择 HototQA,从而查看知识抽取构建效果。
六、KAG 项目案例实践-医疗图谱(有实体类型关系知识图谱 schema)
① 进入案例目录
(kag-demo) D:\KAG\kag\examples\hotpotqa>cd ../medicine/② 项目初始化
knext project restore --host_addr http://183.220.37.57:6008 --proj_path .
③ 知识建模
knext schema commit
上述命令完成后,可以在前端 http://183.220.37.57:6008/ 中,选择 Medicine,从而查看 schema 效果:


④ 知识抽取构建(需要开 VPN)
首先需要更改配置文件:
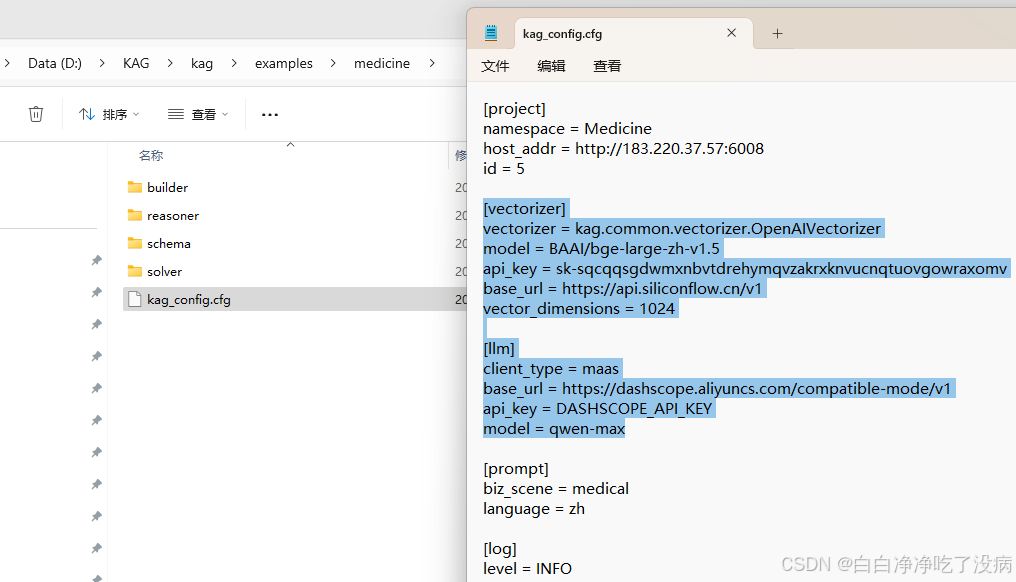
其次开 VPN,执行以下命令:
python ./builder/indexer.py上述命令完成后,可以在前端 http://183.220.37.57:6008/ 中,选择 Medicine,查看知识抽取构建效果。
七、KAG 项目案例实践-黑产挖掘(事件图谱 schema)
① 进入案例目录
(kag-demo) D:\KAG\kag\examples\hotpotqa>cd ../riskmining/② 项目初始化
knext project restore --host_addr http://183.220.37.57:6008 --proj_path .
③ 知识建模
knext schema commit上述命令完成后,可以在前端 http://183.220.37.57:6008/: 中,选择 RiskMing 项目,从而查看 schema 效果:

因此,这里只进行展示图谱某节点与周边节点之间的关系:

④ 知识抽取构建(需要开 VPN)
首先需要更改配置文件:
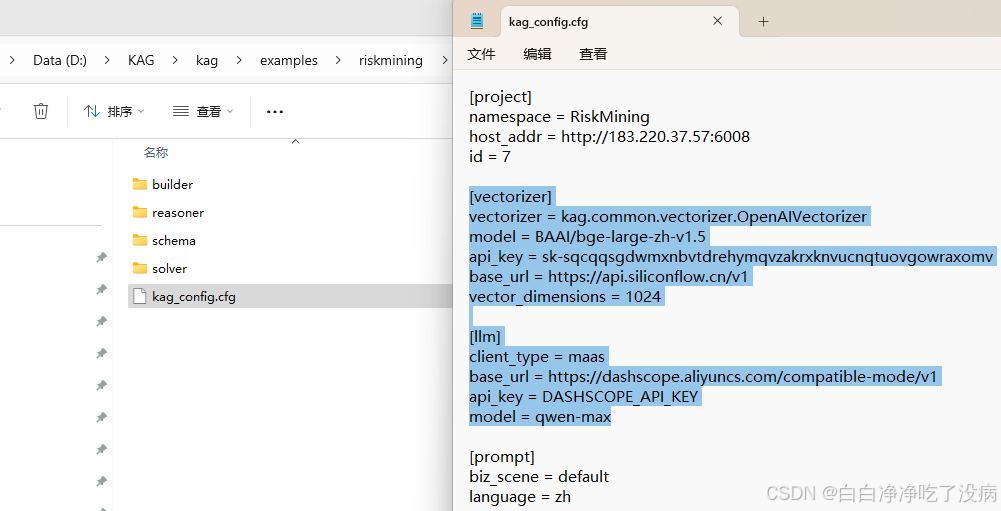
python ./builder/indexer.py上述命令完成后,可以在前端 http://183.220.37.57:6008/ 中,选择 RiskMing 项目,从而查看知识抽样的效果:



















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











