







求无向图的连通分量的个数
在构造函数中,每次执行一次dfs 就会完整遍历一个连通分量。连通分量的个数我们用count 来记录。
public class CC {
private Graph G;
private boolean[] visited;
private int count = 0; // 连通分量的个数
public CC (Graph G) {
this.G = G;
visited = new boolean[G.V()];
for (int w = 0; w < G.V(); w++) {
if (!visited[w]){
dfs(w);
count ++ ; // 每一轮产生一个连通分量
}
}
}
private void dfs(int v) {
visited[v] = true;
for (int w : G.adj(v)) {
if (!visited[w])
dfs(w);
}
}
public int ccount(){ // 返回连通分量的个数
return count ;
}
public static void main(String[] args) {
Graph g = new Graph("g.txt");
CC cc = new CC(g) ;
System.out.println(cc.ccount());
}
}
这里的g.txt 文件格式如下,放在整个工程的目录下。 这样可以比较容易使用相对路径
7 6
0 1
0 2
1 3
1 4
2 3
2 6
// 第一行7 8 分别表示图的顶点个数 和边的条数 后面每一行都表示两个顶点之间存在一条边
你可以自己构建一个图,然后用这样的方式输入数据。检测自己的图拥有的连通分量的个数。
图的构建代码我放在下面供大家参考 这里使用邻接表进行图的存储
import java.io.File;
import java.io.IOException;
import java.util.Scanner;
import java.util.TreeSet;
public class Graph {
private int V; // 顶点数
private int E; //边的条数
private TreeSet<Integer>[] adj; // treeset类型的数组
// 构造函数
public Graph(String filename) {
File file = new File(filename);
try (Scanner scanner = new Scanner(file)) { // 必须要处理异常java语法规定的
V = scanner.nextInt();
if (V < 0) throw new IllegalArgumentException("V must be non-negative");
adj = new TreeSet[V]; // V个集合
for (int i = 0; i < V; i++) {
adj[i] = new TreeSet<>(); // 类型推断 Integer 可以省略
//使用TreeSet在一些算法题中也非常有用,一些oj平台的题目经常在输出上做排序要求 TreeSet会自动对存放的数据进行排序
}
E = scanner.nextInt();
if (E < 0) throw new IllegalArgumentException("E must be non-negative");
for (int i = 0; i < E; i++) { // 建立邻接表
int a = scanner.nextInt();
int b = scanner.nextInt();
validateVertax(a);
validateVertax(b);
if (a == b) // 如果有自环边 抛出异常
throw new IllegalArgumentException("self loop is detected");
if (adj[a].contains(b)) // 如果有平行边 抛出异常
throw new IllegalArgumentException("parallel edge is degteced");
adj[a].add(b); // O(v) 级别的操作,链表长度级别的
adj[b].add(a);
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 判断顶点的合法性
private void validateVertax(int v) {
if (v < 0 || v >= V)
throw new IllegalArgumentException("verrtex" + v + "is invalid");
}
public int V() { // 返回顶点的个数
return V;
}
public int E() { // 返回边的条数
return E;
}
// 是否存在一条边
public boolean hasEdge(int v, int w) {
validateVertax(w);
validateVertax(v);
return adj[v].contains(w); //
}
// 返回和V 相邻的顶点集合
public Iterable<Integer> adj(int v) { // 返回接口对象 这几种结构都实现了iterable
// 这样可以统一方法 这里就进行一次抽象
validateVertax(v);
return adj[v];
}
// 求一个顶点的度
public int degree(int v) {
validateVertax(v); //这里不做验证 adj这里会进行验证
return adj[v].size();
}
@Override
public String toString() { // 这里需要做一些修改
// 我们一般都 i j k 表示index uvw 表示图论中的顶点
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(String.format("V = %d , E = %d\n", V, E));
for (int v = 0; v < V; v++) {
stringBuilder.append(String.format("%d : ", v));
for (int w : adj[v]) { // adj[v].get(j) 这里用的是迭带遍历
stringBuilder.append(String.format("%d ", w));
}
stringBuilder.append("\n");
}
return stringBuilder.toString();
}
public static void main(String[] args) {
// 默认一个工程的性对路径是在这个工程的文件夹下,也就是Graph 这个文件夹下
Graph adjSet = new Graph("g.txt");
System.out.println(adjSet);
}
}
连通分量都包含哪些顶点
如果想知道每一个连通分量都包含哪些顶点,我们可以在外层每一次新进入一个连通分量,都传入一个空的 容器,这样,在dfs的时候,把对应连通分量遍历到的顶点都添加到容器中。但是这样有一点点臃肿。相应的思路在下面的伪代码中有表述。
for (int w = 0; w < G.V(); w++) {
if (!visited[w]){
dfs(w , list[count]); // 每次传入一个容器 list[count] 是一个列表 list是一个包含列表的列表
count ++ ; // 每一轮产生一个连通分量
}
}
我们换一个思路,我们可以改造一下visited 数组,让这个visited数组记录更多的信息。 由于我们需要求解的是,每一个顶点属于哪一个连通分量,同时我们标记连通分量是从0开始编号的, 并且,每一个被遍历到的顶点都会有属于自己>0 连通分量的编号。 因此,我们把visited数组改成int型, 同时初始化为-1, 表示所有的顶点在初始是不属于任何连通分量,同时还没有被访问到。 这样 , visited 数组就有了两层含义。
同时我们在遍历时dfs函数中新添加一个变量 ccId 表示连通分量的ID 在遍历到一个顶点 v 时,我们把这个ccId写入visited , visited[v]= ccId 标记这个顶点属于哪个连通分量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6NQy3wIL-1587569640712)(…/…/Movies/算法编程/图论算法/课程截图/第四章dfs应用/屏幕快照 2020-04-22 下午2.57.52.png)]
初始时:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| -1 | -1 | -1 | -1 | -1 | -1 | -1 |
遍历后:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 |
public class CCadv { // CCadv 表示求连通分量的升级版
private Graph G;
private int[] visited;
private int count = 0; // 连通分量的个数
public CCadv(Graph G) { //
this.G = G;
visited = new int[G.V()];
for (int i = 0; i < G.V(); i++) // 初始化都为-1
visited[i] = -1;
for (int w = 0; w < G.V(); w++) {
if (visited[w] == -1) { //如果visited[w]==-1 表示还没有被访问过
dfs(w, count); // dfs(w ,count++) 每一轮dfs 会遍历一个连通分量
count++; // 进入下一轮,连通分量的个数要++
}
}
}
// dfs遍历 ccId 表示当前遍历顶点的连通分量的ID 我们用连通分量的个数表示ID
private void dfs(int v, int ccId) {
visited[v] = ccId;
for (int w : G.adj(v)) {
if (visited[w] == -1)
dfs(w, ccId);
}
}
// 打印最后遍历的连通分量的信息 也就是打印visited数组的信息
public int count() {
for (int e : visited)
System.out.print(e + " ");
System.out.println();
return count;
}
public static void main(String[] args) {
Graph g = new Graph("g.txt");
CCadv cCadv =new CCadv(g) ;
System.out.println( cCadv.count());
}
}
两个顶点是否在同一个连通分量中
判断两个顶点是否在同一个连通分量中十分方便,因为visited数组存储的就是每个顶点对应的连通分量的编号。 因此直接判断这两个顶点对应的连通分量 是否相等即可。
//判断两个顶点是否在一个连通分量中
public boolean isConnected(int v , int w){
return visited[v] ==visited[w] ;
}
我们只需要遍历整个visited数组, 就可以收集这个信息。res [index] 就是连通分量index 中所有顶点的集合。这里可以非常巧妙的利用 visited[v ] 为连通分量的ID 来进行逻辑的书写, res[visited[v]].add(v)
// 不同的连通分量中包含的顶点都是谁
public ArrayList<Integer>[] components() {
ArrayList<Integer>[] res = new ArrayList[count]; //我们有多少连通分量就申请多少个列表
for (int i = 0; i < count; i++)
res[i] = new ArrayList<>();
for (int v = 0; v < G.V(); v++) {
res[visited[v]].add(v); // 连通分量中包含的顶点
}
return res;
}
单源路径问题
如果单纯问两个点之间是否有路径(是否在同一个连通分量中),直接用isConnected 就够了。但是如果求一个具体的路径是谁,还不够。我们需要在dfs中记录更多的信息。
如果我们在dfs中遍历到一个顶点时,可以知道这个这个顶点它的上一个顶点是谁,也就是说,它是从哪一号顶点过来的,那么我们就可以顺腾摸瓜,找出这条路径。因此我们需要一个pre数组记录每个顶点在遍历过程中的父顶点是谁,初始时 pre[i] = i 父顶点都初始化为自己。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FQWtovaH-1587569640719)(…/…/Movies/算法编程/图论算法/课程截图/第四章dfs应用/屏幕快照 2020-04-22 下午2.57.52.png)]
以这张图为例,加入我们要找0-6之间的路径,我们需要从顶点0开始dfs遍历,这幅图的邻接表如下:
0 : 1 2
1 : 3 4
2 : 0 3 6
3 : 1 2
4 : 1
5 :
6 : 2
加入我们想要求从顶点0到顶点6的路径,那么我们对顶点0进行dfs遍历即可。我们按照邻接表的顺序从顶点0进行dfs遍历:dfs(0) ->dfs(1) ->dfs(3)->dfs(2)->dfs(6)->dfs(4) (我们发现5不在遍历序列中,这是因为5和0不在一个连通分量中,因此这两个点之间也就不存在路径)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 1 | 6 | 5 | 2 |
根据这个数组,我们就可以求出起点0 与0在同一个连通分量中的所有顶点路径(只是路径,不一定是最短的)比如求解从0—>6 的路径, pre[6] 为2 pre[2] 为3 pre[3] 为1 pre[1] 为0 于是我们知道了 6<–2<–3<–1<–0
我们这个算法目前只是求单源路径,也就是指定一个起点,求解这个起点 到它所在连通分量所有顶点的路径。比如0为起点, 0所在连通分量有顶点 0 1 2 3 4 6 我们求的是0 到这些顶点路径。
import java.util.ArrayList;
import java.util.Collections;
public class SingleSourcePath {
private Graph G;
private int s; // 单源的源是谁
private boolean[] visited;
private int[] pre;
public SingleSourcePath(Graph G, int s) { // 构造函数 我们在构造函数中已经调用dfs 对图进行遍历 并得到order数组
G.validateVertax(s); // 对s的合法性做一个判断
this.G = G;
this.s = s;
pre = new int[G.V()]; // 存放顶点的在路径中的父顶点
for (int i = 0; i < pre.length; i++)
pre[i] = -1; // 如果pre[i]==-1 就说明这个顶点没有被遍历过 但是语义也模糊了 因为现在pre有了两层语义
visited = new boolean[G.V()];
dfs(s, s); // 只遍历和s连通的顶点 初始时s的父顶点都是自己
}
// parent 是v的在遍历路径的上一个顶点
private void dfs(int v, int parent) {
visited[v] = true;
pre[v] = parent;
for (int w : G.adj(v)) {
if (!visited[w]) {
dfs(w, v);
}
}
}
// 判断从起点s到顶点t是否存在一条路径
public boolean isConnectedTo(int t) {
G.validateVertax(t);
return visited[t]; // 只要被标记上,就是和源连通的
}
public Iterable<Integer> path(int t) {
ArrayList<Integer> res = new ArrayList<>();
if (isConnectedTo(t)) { // 如果能到达t
int cur = t;
while (cur != s) {
res.add(cur);
cur = pre[cur];
}
res.add(s); // 最后把源s添加进去 现在是一个倒序 用reverse方法把顺序反过来
Collections.reverse(res);
}
return res;// 如果没有路径,就返回一个空list
}
public static void main(String[] args) {
Graph g = new Graph("g.txt");
SingleSourcePath singleSourcePath = new SingleSourcePath(g, 0);
System.out.println("0--->6:" + singleSourcePath.path(6));
System.out.println("0--->5:" + singleSourcePath.path(5));
}
}
但是有时候,我们就是想知道一个顶点到某一个目标顶点是否有路径,难道我们需要遍历完整个连通分量之后才给出答案吗?其实不是的,我们只需要在遍历过程中找到目标顶点,就终止遍历。因此我们需要对dfs进行改造。
import java.util.ArrayList;
import java.util.Collections;
public class Path {
private Graph G;
private int s; // 单源的源是谁 即起点是谁
private int t; // 终止点是谁
private boolean[] visited;
private int[] pre;
public Path(Graph G, int s, int t) { // 构造函数 我们在构造函数中已经调用dfs 对图进行遍历 并得到order数组
G.validateVertax(s); // 对s的合法性做一个判断
G.validateVertax(t);
this.G = G;
this.s = s;
this.t = t;
pre = new int[G.V()]; // 存放顶点的在路径中的父顶点
for (int i = 0; i < pre.length; i++)
pre[i] = -1; // 如果pre[i]==-1 就说明这个顶点没有被遍历过 但是语义也模糊了 因为现在pre有了两层语义
visited = new boolean[G.V()];
dfs(s, s); // 只遍历和s连通的顶点 初始时s的父顶点都是自己
for(boolean e :visited){
System.out.print(e+" ");
}
System.out.println();
}
// parent 是v的上一个顶点
private boolean dfs(int v, int parent) {
visited[v] = true; // 我们应该先标记后判断 如果先判断会导致t标记不上
pre[v] = parent; // 如果标记不上,就会出现判断错误,即v和s不在一个连通分量中,那么也就是没有路径
if (v == t)
return true;
for (int w : G.adj(v))
if (!visited[w])
if (dfs(w, v)) // 如果下一层dfs返回true 说明已经找到这个顶点了,这一层也应该随之返回
return true;
return false;
}
public boolean isConnected() {
return visited[t]; // 只要被标记上,就是和源连通的
}
public Iterable<Integer> path() {
ArrayList<Integer> res = new ArrayList<>();
if (isConnected()) { // 如果能到达t
int cur = t;
while (cur != s) {
res.add(cur);
cur = pre[cur];
}
res.add(s); // 最后把源s添加进去 现在是一个倒序
Collections.reverse(res);
}
return res;// 如果没有路径,就返回一个空list
}
public static void main(String[] args) {
Graph g = new Graph("g.txt");
Path path = new Path(g, 0, 6);
System.out.println("0-->6:" + path.path());
}
}
检测无向图中的环
其实也就是说,我从一个顶点出发,是不是可以找到一条路径回到自己 。 找到一个已经被访问过的顶点,这个顶点不是当前访问顶点的上一个顶点。
public class CycleDetection {
private Graph g;
private boolean[] visited;
private boolean hasCycle = false;
public CycleDetection(Graph g) {
this.g = g;
visited = new boolean[g.V()];
}
public boolean cycle() {
for (int v = 0; v < g.V(); v++) {
if (!visited[v]) {
if(dfs(v,v)){
hasCycle =true;
break;
}
}
}
return hasCycle;
}
// 从顶点v出发判断图是否有环 这个递归算法是可以提前终止
private boolean dfs(int v, int parent) {
visited[v] = true;
for (int w : g.adj(v)) {
if (!visited[w]) {
if (dfs(w, v))
return true;
//如果w已经被访问过了 并且不是v的父顶点 这个条件就是递归终止条件
} else if (w != parent)
return true;
}
return false;
}
public static void main(String[] args) {
Graph g = new Graph("g.txt");
Graph g2 = new Graph("g2.txt");
CycleDetection hasCycle = new CycleDetection(g);
CycleDetection hasCycle2 = new CycleDetection(g2);
System.out.println(hasCycle.cycle());
System.out.println(hasCycle2.cycle());
}
}
二分图检测
什么是二分图呢?
顶点V可以分为不想交的两个部分
所有的边的两个端点隶属于不同的部分。
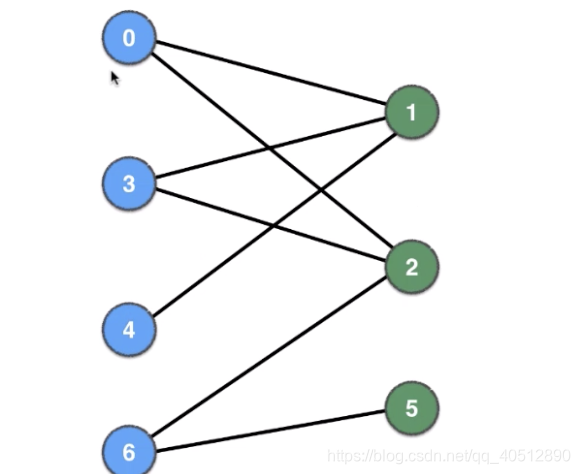
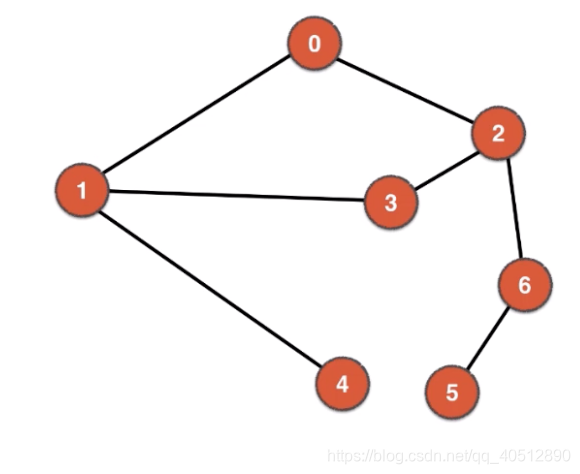
第一个图可以很容易看出这是一个二分图,但是对于第二图就不是那么容易判断是不是一个二分图。 事实上,第一幅图就是第二幅图。
如何用程序自动判断二分图呢? —> 染色 在dfs中进行染色操作 当然这里的染色不是真的染色,而是把图的顶点标记为两类,使得相邻的两个顶点类别不同。因此这里我用 0 和 1 代表不同的两个类别。使用dfs遍历,用一个 int型的colors数组标记每一个顶点的颜色,初始值都为-1 , 代表还未进行染色。
public class BipartitionDetection {
private Graph G;
private boolean[] visited; // 可以省略,colors[v] ==-1 表示未访问过
private int[] colors;
private boolean isBipartite = true;
public BipartitionDetection(Graph G) {
this.G = G;
visited = new boolean[G.V()];
colors = new int[G.V()];
for (int i = 0; i < G.V(); i++) {
colors[i] = -1; // 表示顶点上的颜色还没有被染上
}
for (int w = 0; w < G.V(); w++) {
if (!visited[w]) {
if(!dfs(w ,0)){
isBipartite = false;
break;
}
}
}
}
// 二分图的检测
private boolean dfs(int v, int color) {
visited[v] = true;
colors[v] = color;
for (int w : G.adj(v)) {
if (!visited[w]) {
if (!dfs(w, 1 - color)) return false;
} else if (colors[w] == colors[v])//如果顶点w已经访问过了,并且和顶点v的颜色相同 返回false
return false;
}
return true;//如果顶点v对自己的每一个邻接点都进行了检测 都没有发现问题,那么就返回true
}
public boolean isBipartite(){
return isBipartite;
}
public static void main(String[] args){
Graph g =new Graph("g.txt");
Graph g2 =new Graph("g2.txt") ;
BipartitionDetection bipartitionDetection = new BipartitionDetection(g);
BipartitionDetection bipartitionDetection2 =new BipartitionDetection(g2) ;
System.out.println(bipartitionDetection.isBipartite());
System.out.println(bipartitionDetection2.isBipartite());
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









