







AffinityNet: Semi-Supervised Few-Shot Learning for Disease Type Prediction
Publication:
The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19)
Code:
AffinityNet:https://github.com/BeautyOfWeb/AffinityNet
Scikit-learn:http://scikit-learn.org
Dataset:
Harmonized kidney and uterus cancer gene expression datasets were downloaded from Genomic Data Commons Data Portal (https://portal.gdc.cancer.gov) (Grossman et al. 2016).
Introduction
Patients, drugs, networks, etc., are all complex objects with heterogeneous features or attributes. Complex objects usually have heterogeneous features with unclear structures. Deep learning models such as Convolutional Neural Networks (CNNs) cannot be directly applied to complex objects whose features are not ordered structurally.
One critical challenge in cancer patient clustering problem is the “big p, small N” problem. We do not have an “ImageNet” (Russakovsky et al. 2015) to train deep learning models that can learn good representations from raw features. These features are not “naturally” ordered. Thus, we cannot directly use convolutional neural networks with small filters to extract abstract local features.
For a clustering/classification task, nodes/objects belonging to the same cluster should have similar representations that are near the cluster centroid. So, we developed the k-nearest-neighbor (kNN) attention pooling layer, which applies the attention mechanism to learning node representations. With the kNN attention pooling layer, each node’s representation is decided by its k-nearest neighbors as well as itself, ensuring that similar nodes will have similar learned representations.
we propose the Affinity Network Model (AffinityNet) that consists of stacked kNN attention pooling layers to learn the deep representations of a set of objects. Similar to Graph Attention Model (GAM) (Veliˇckovi´c et al. 2017), but GAM is designed to tackle representation learning on graphs and it does not directly apply to data without a known graph, our AffinityNet model generalizes GAM to facilitate representation learning on any collections of objects with or without a known graph.
In addition to learning deep representations for classifying objects, feature selection is also important in biomedical research. In order to facilitate feature selection in a “deep learning” way, we propose a feature attention layer, a simple special case of the kNN attention pooling layer which can be incorporated into a neural network model and directly learn feature weights using backpropagation.
We performed experiments on both synthetic and real cancer genomics data. The results demonstrated that our AffinityNet model has better generalization power than conventional neural network models for few-shot learning.
Related Work
In graph learning, a graph has a number of nodes and edges (both nodes and edges can have features). Combining node features with graph structure can do a better job than using node features alone. However, all these graph learning algorithms require that a graph is known. Many algorithms also require the input to be the whole graph, and thus do not scale well to large graphs. Our proposed AffinityNet model generalizes graph learning to a collection of objects with or without known graphs.
As the key component of AffinityNet, kNN attention pooling layer is also related to normalization layers in deep learning. All these normalization layers use batch statistics or feature statistics to normalize instance features, while kNN attention pooling layers apply the attention mechanism to the learned instance representations to ensure similar instances will have similar representations.
Our proposed kNN attention pooling layer applies pooling on node representations instead of individual features. kNN attention pooling layer combines normalization, attention and pooling, making it more general and powerful. It can serve as an implicit regularizer to make the network generalize well for semi-supervised few-shot learning.
Affinity Network Model (AffinityNet)
One key ingredient for the success of deep learning is its ability to learn a good representation through multiple complex nonlinear transformations. While conventional deep learning models often perform well when lots of training data is available, our goal is to design new models that can learn a good feature transformation in a transparent and data efficient way. We developed the kNN attention pooling layer, and used it to construct the AffinityNet Model.
In a typical AffinityNet model as shown in Fig. 1, the input layer is followed by a feature attention layer (a simple special case of kNN attention pooling layer used for raw feature selection), and then followed by multiple stacked kNN attention pooling layers (Fig. 1 only illustrates one kNN attention pooling layer).
The output of the last kNN attention pooling layer will be the newly learned network representations, which can be used for classification or regression tasks.
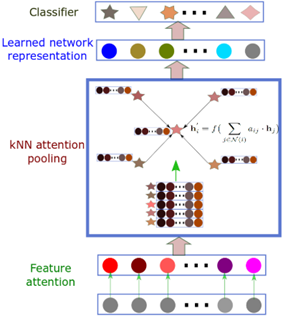
图表 1 AffinityNet Overview
Though it is possible to train AffinityNet with only a few labeled examples, it is more advantageous to use it as a semi-supervised learning framework (i.e., using both labeled and unlabeled data during training).
kNN attention pooling layer
A good classification model should have the ability to learn a feature transformation. As an object’s k-nearest neighbors should have similar feature representations, we propose the kNN attention pooling layer to incorporate neighborhood information using attention-based pooling (Eq. 1):
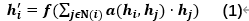
h i h_{i} hi —— input feature representations for object i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1373
1373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









