






SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
(SegNet 用于图像分割的编码解码架构的卷积网络)
文章目录
简介
- 论文针对场景理解需求提出了SegNet模型,将原来用于无监督学习的自编码器(encoder-decoder)用于图像分割
- 针对图像分割特定问题,在上采样时,采用带索引的反池化操作,保留了边界信息,提升了分割精度。
- 论文在SegNet和FCN上设计了不同的解码器变体,定量分析了解码器影响精度的关键因素。
一、创新点
- 采用 encoder-decoder 结构(结构对称)
- 在encoder阶段,重用decoder阶段记录下的最大池化索引
- 提升边界划分
- 减少参数量的学习
- 可以融合到任何encoder-decoder架构中
- 设计了SegNet和FCN上不同的解码器变体,定量分析了解码器影响精度的关键因素
- encoder feature maps 保留和利用更多,效果越好
- 在受内存限制时,需要压缩encoder feature map (可以采用降维,最大池化索引)
- decoder 参数量越大(卷积的 channel),效果也会越好
总结
- 论文在实验精度上没有达到最优,仅推理内存最低
- 进行了6组实验
- 在图像分割中引入了 encoder-decoder的对称架构
二、论文链接
原文链接
代码链接
论文投稿期刊
相关论文
[DeepLab-LargeFOV] Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
[DeconvNet]Learning Deconvolution Network for Semantic Segmentation
三、 论文评价
-
创新: SegNet是在自编码架构上,采用了带索引的池化层和根据索引的反池化层,兼顾了内存和边界信息。但是SegNet的推理时间会比较长,而从预测指标上来看,也没有非常惊艳的结果,只是在池化操作上作了文章,在实时应用上还有待优化。
-
行文:
- 文章开头和结尾都明确指出SegNet是针对于场景理解应用需求而设计,强调场景理解更具挑战性和实用性(出发点有价值,未来也具有较大的探索空间)
- 模型的使用技巧也应对了相应需求,兼顾内存和精度(虽然只是在推理内存上达到最优)(改进是有针对性的)
- 实验也在场景理解中的路景和室内的任务上进行的(呼应)
- 文章的最大优势是定量分析做的很好,有对照的模型变体(利于找出精度提升的关键因素),有针对性的评价指标BF,有较为细节的控制变量的模型训练,以更好的分析和评价模型。
四、模型
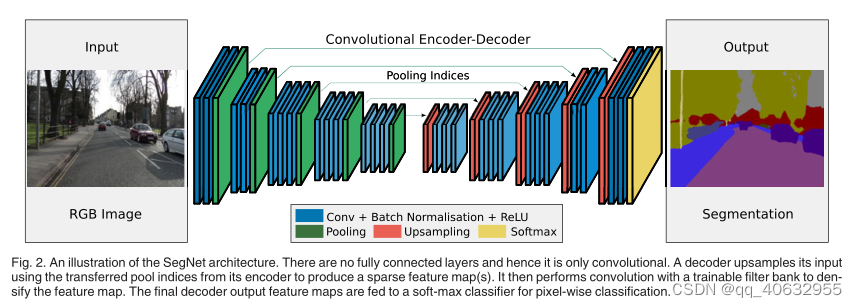
- 编码器是采用VGG16中前13的卷积层,解码器也对于13层,大小和通道数一一对应(除了第一个和最后一个)
- 对应第一个编码器的最后一个解码器的卷积通道数是类别数,用于soft-max classifier
- 编码器的每一个卷积层后都有BN和ReLU,加上max-pooling(2*2、2s),并记录最大池化索引;
- 解码器复用最大池化索引,进行上采样,(此时的特征图比较稀疏),后面接上卷积层(来产生密集的特征图),再加上BN和ReLU
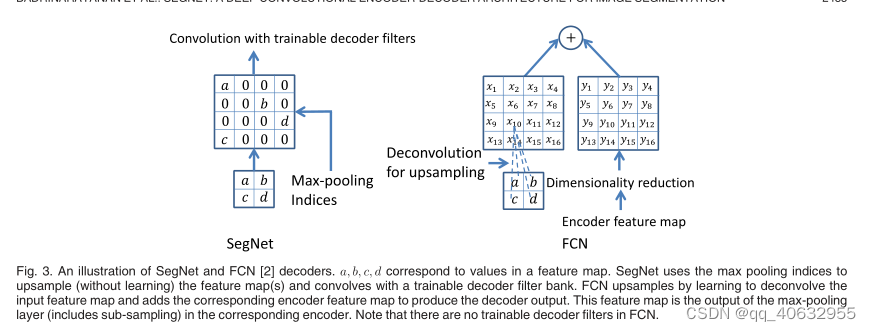
- 索引记录,每个池化窗口,用 2 bits 来存储
五、实验
数据集
- CamVid 中的road scene datasets(11类)
- SUN RGB-D的indoor scene datasets( 5,285 training 5,050 testing 37类)
具体实验
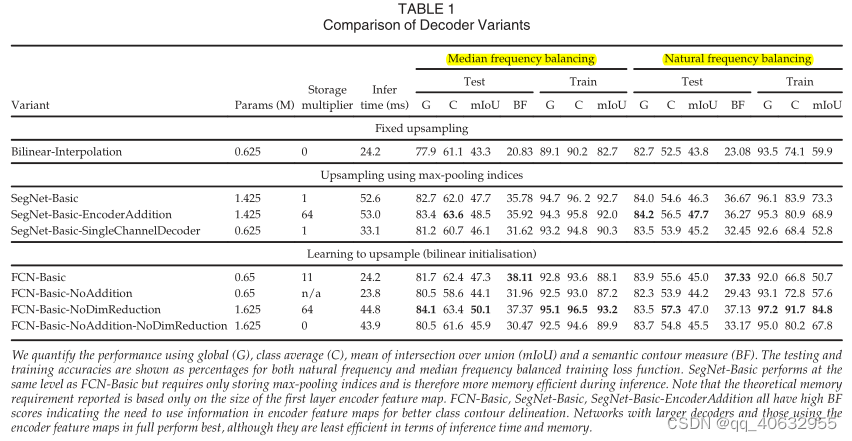
实验1(模型decoder变体的参数,内存,推理时间,不同精度比较)
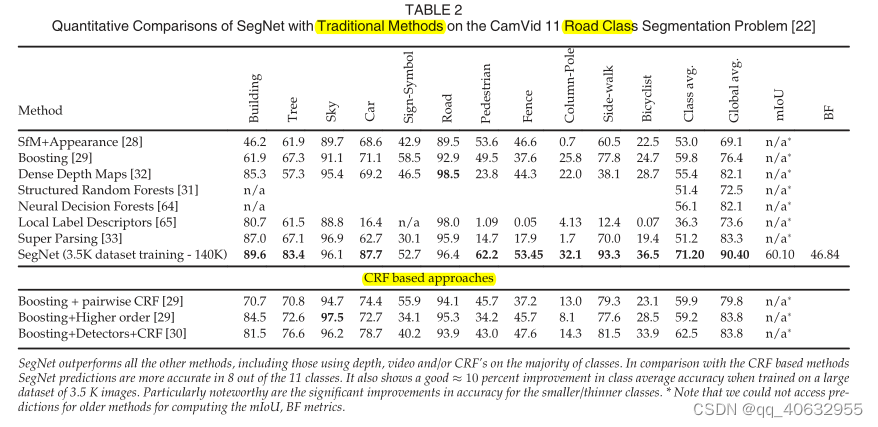
实验2(与传统方法做不同类、精度的比较)
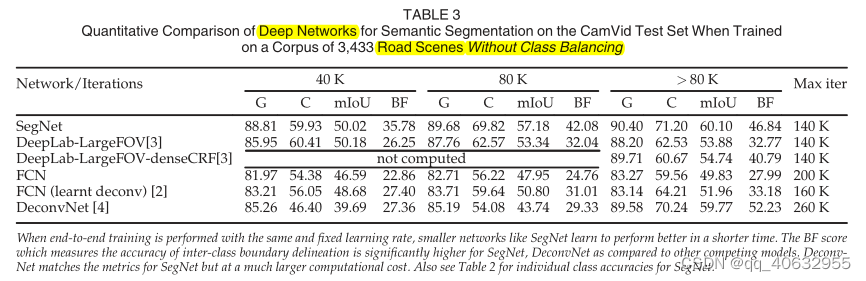
实验3(不同模型在road scene不同训练阶段的精度比较)
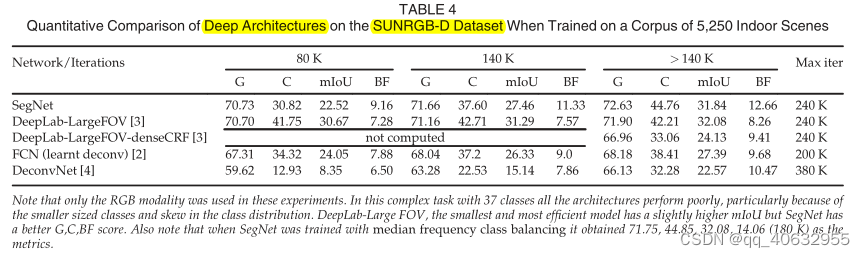
实验4(不同模型在indoor scene不同训练阶段的精度比较)
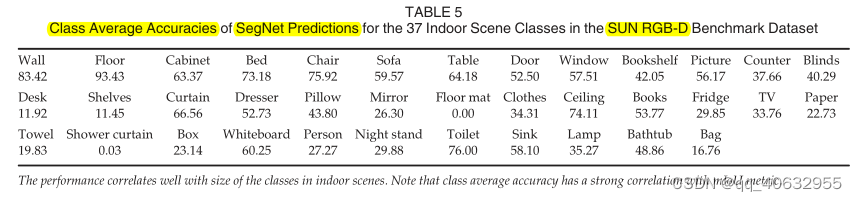
实验5 (SegNet在indoor scene上各类的精度)
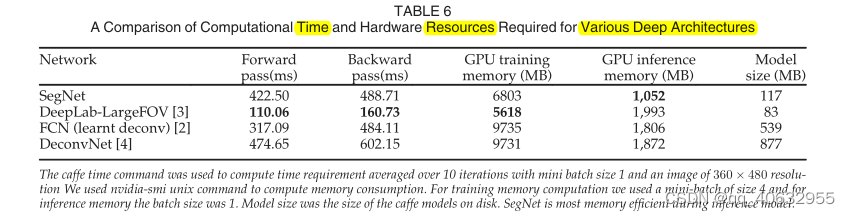
实验6(不同模型在计算时间和内存的比较)















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









