






 本文介绍了Deeplabv3+模型,该模型在Deeplabv3基础上增加了decoder结构,使用空洞卷积获取多尺度信息,并通过改进的Xception作为backbone提高精度和效率。在PASCAL VOC2012和Cityscapes数据集上实现最优性能,分别达到89.0%和82.1%的精度。论文详细探讨了模型设计、实验选择及不同变体的性能比较。
本文介绍了Deeplabv3+模型,该模型在Deeplabv3基础上增加了decoder结构,使用空洞卷积获取多尺度信息,并通过改进的Xception作为backbone提高精度和效率。在PASCAL VOC2012和Cityscapes数据集上实现最优性能,分别达到89.0%和82.1%的精度。论文详细探讨了模型设计、实验选择及不同变体的性能比较。
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
文章目录
简介
- 论文在deeplabv3的基础上添加了decoder结构,提出了deeplabv3+
- deeplabv3中ASPP(空洞空间卷积金字塔)具有提取多尺度上下文信息(等效不同大小的感受野,卷积核参数量也不会增加)
- 添加的decoder可以提取精细的目标边界
- 空洞卷积可以提取backbone中任意分辨率的feature
- 改进xception作为backbone,使用深度可分离卷积,提神精度,减少了参数量和计算量,
一、创新点
- 提出了一个encoder-decoder的模型结构,即deeplabv3作为encoder,并添加一个简单的decoder
- 使用的空洞卷积可以任意控制提取特征的分辨率,在权衡精度和运行时间时可做选择
- 改进Xception,并将深度可分离卷积应用到ASPP和decoder模块中,提升了速度和精度
- 模型在PASCAL VOC2012后和Cityscapes数据集上达到最优,分别为89.0% 和 82.1%
- 分析了模型的设计选择和模型的变体
总结
- 论文在实验精度上达到最优(PASCAL VOC2012和Cityscapes,89.0% 和 82.1%)
- 进行了9组实验
二、论文链接
原文链接
代码链接
pytorch-segmentation
deeplabplus-pytroch
论文投稿期刊
相关论文
[Xception] Xception:Deep learning with depthwise separable convolutions. In:CVPR2017 (arxiv.org)
[deeplabv3] Rethinking atrous convolutionfor semantic image segmentation(2017)(arxiv.org)
[PSPNet] Pyramid scene parsing network. In:CVPR2017
三、论文评价
- 创新:该论文是在deeplabv3加了一点点改进(添加了decoder,改进xception作为backbone),精度提升了,综合各种模块的优势吧,创新不是很大。
- 行文:
- 改进小,所以论文一直在强调不同模块的优势和作用,将他们融合到模型中。
- 在实验中体现融入模块后精确度的提升。
- 论文模型细节的设计和实验选择描述得很详细(有decoder的设计,以及backbone的选择和改进)(在论文前面只是大致介绍层的作用,没有精确个数)
四、模型
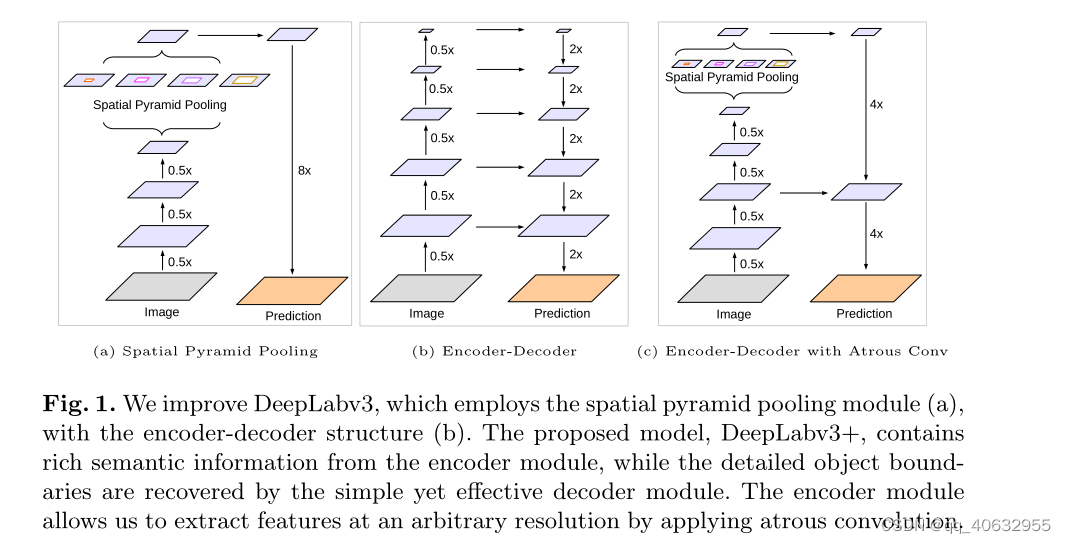
- deeplab模型融合了encoder-decoder结构,和SPP结构;
- 在SPP上采用不同rate的空洞卷积变为ASPP
- low-level feature是输入图像分辨率降维原来的1/4 ,即经历里了两个stride=2
- 指定backbone最后输出的feature分辨率是用空洞卷积来控制的,一般output_stride选取16或8。
-link:空洞卷积不改变分辨率,在其等效标准卷积的感受野大小时,stride和空洞rate的转化
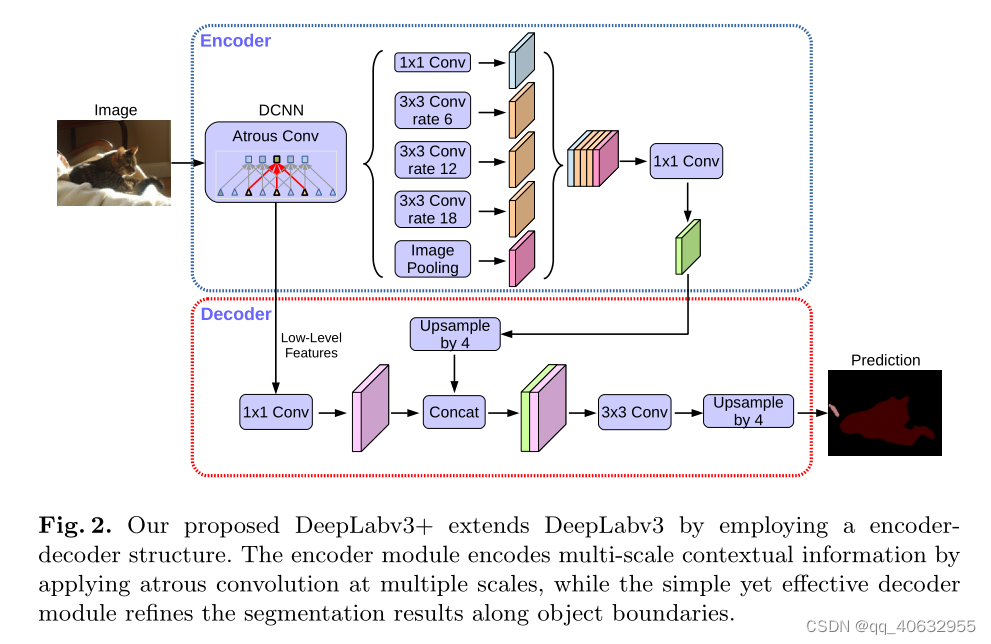
- Image pooling: 全局平均池化 ----> 输出尺寸(1,1) ---->1*1卷积 改变通道---->上采样恢复成输入的尺寸
- backbone提取的low-level feature 的channel 通过1*1卷积降维到48(经过试验表明,48最优)
- 经过ASPP(每个部分通道将其降为256,共5个部分),cat为5 * 256,再经过通过1*1卷积降维到256
- 两个feature cat之后,接上2个3*3卷积,输出channel都为256,然后接上1*1卷积,通道降维分类数
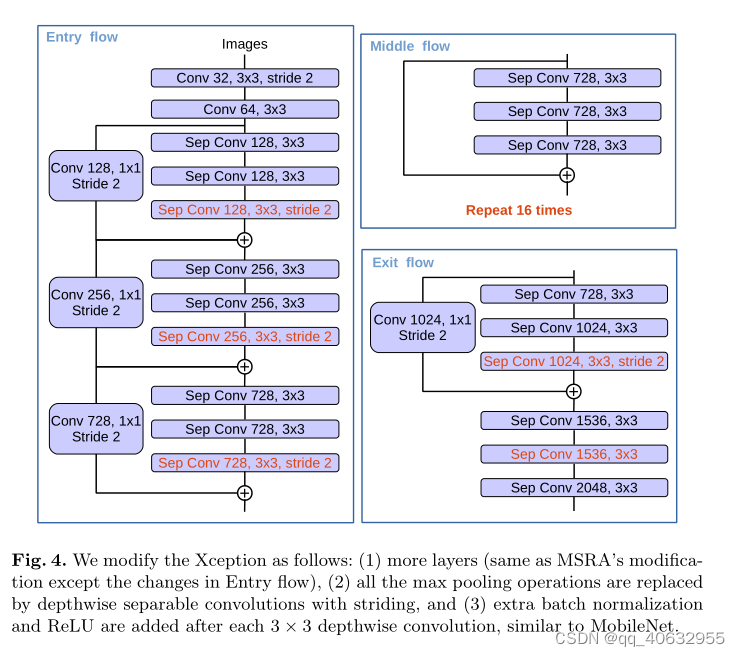
- 论文中描述了resnet101和改进的xception,使用改进的xception作为backbone效果好
五、实验
数据集
- PASCAL VOC 2012
- Cityscapes(50 类,包括了5000 张精准标注和20000 张粗略标注)
- JFT-300M dataset
- MS-COCO dataset
训练
学习率策略:poly
初始学习率:0.007
具体实验
实验1(选择low-level降维通道数)

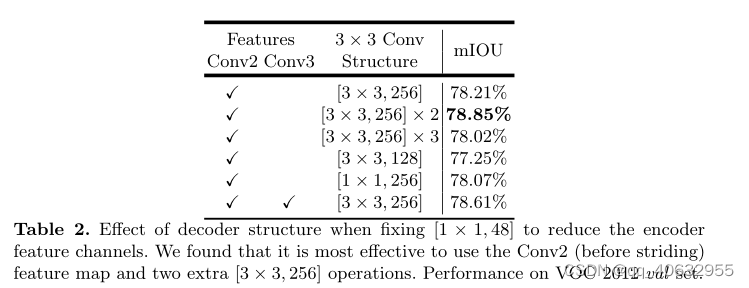
实验2(deceder的细节设计精度比较)
实验3(model variants在voc上精确度和计算量的比较)
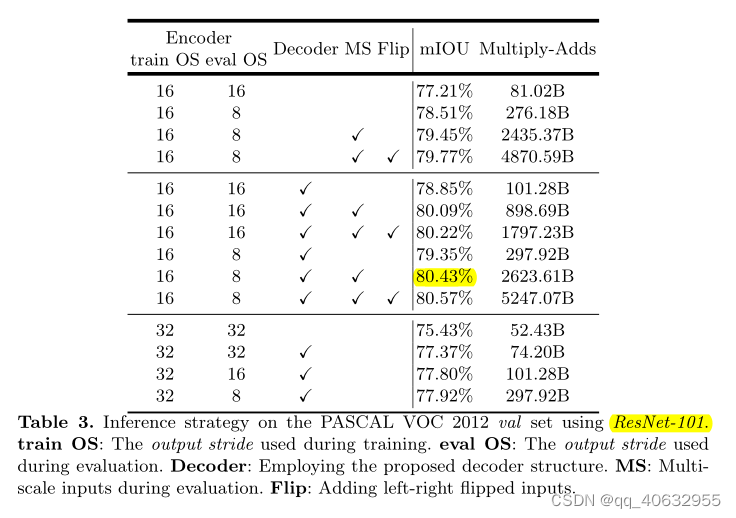
实验4 (backbone分类精度比较)

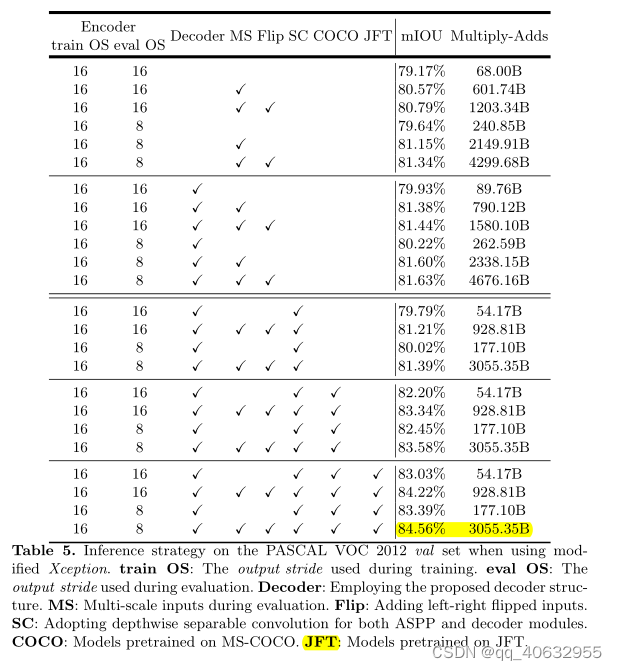
实验5(model variants在精确度和计算量上的比较,backbone为xception)
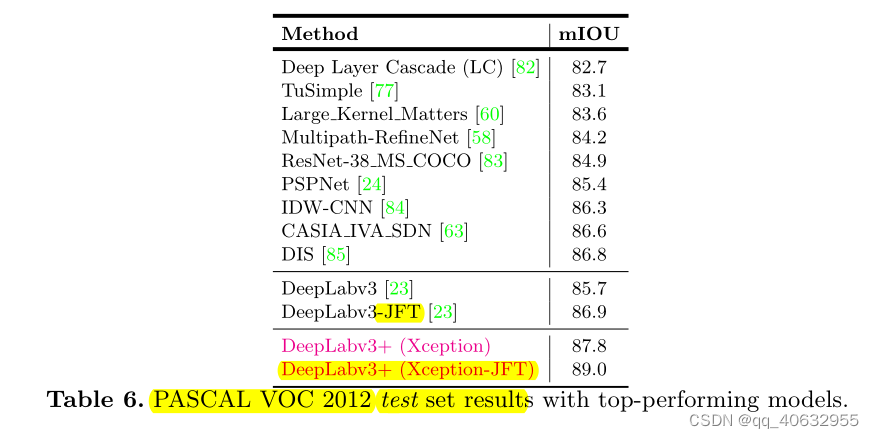
实验6 (在voc上与其他top模型的精度比较)
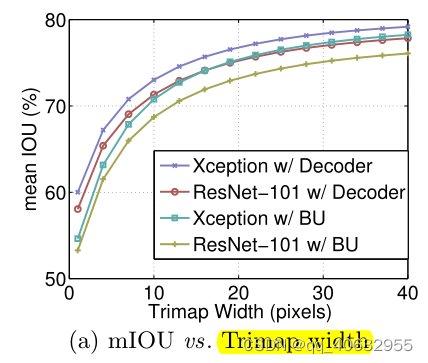
实验7(不同trimap width上精度的比较)
实验8 (model variants在Cityscapes上的精度比较)
实验9(在Cityscapes上与其他top模型的精度比较)


















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









