







目录
1 Logistic回归分类器基本原理
Logistic回归是一种用于解决分类问题的线性模型,尤其适用于二分类问题。它通过sigmoid函数将线性回归的输出转换为概率,并根据阈值对概率进行分类。
1.1 Sigmoid函数
Logistic回归使用sigmoid函数(也称为逻辑函数),将线性组合的输出映射到概率。
Sigmoid函数的表达式为:
, 其中
是线性组合的结果
Sigmoid函数在不同坐标尺度下的两条曲线图:
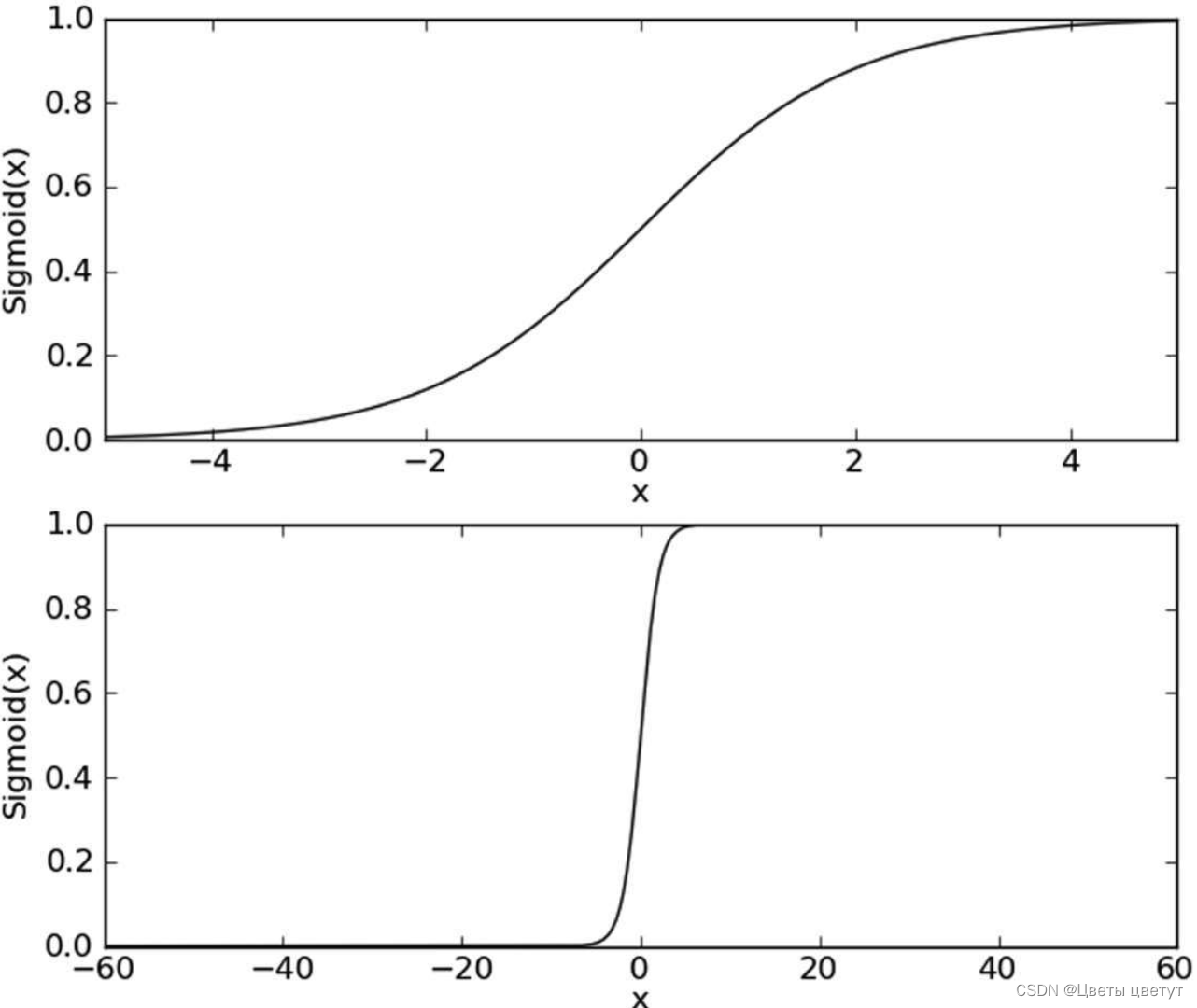
当x为0时,Sigmoid函数值为0.5。随着x的增大,对应的Sigmoid值将逼近于1;随着x的减小,Sigmoid值将逼近于0。如果横坐标刻度足够大, Sigmoid函数看起来很像一个阶跃函数。
1.2 确定最佳回归系数
Sigmoid函数的输入 的表达式:
其中,向量 是分类器的输入特征数据,向量
就是我们需要找到的最佳参数(系数)。
为了寻找该最佳参数,需要用到最优化理论的知识——梯度上升法。
-
梯度上升法
梯度上升法是一种优化算法,基本思想是通过迭代更新参数来找到使目标函数取得最大值的参数值。在每次迭代中,根据目标函数对参数的梯度方向进行更新,直到满足停止条件。更新规则如下:
其中, 是需要优化的参数向量;
是需要最大化的目标函数;
是目标函数
对参数
的梯度;
是学习率,用于控制参数更新的步长。
迭代的过程中,梯度算子总是指向函数值增长最快的方向,总是保证我们能选取到最佳的移动方向。
梯度上升法python代码:
# sigmoid函数
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) # 转换为 NumPy 矩阵
labelMat = np.mat(classLabels).transpose() # 转换为 NumPy 矩阵并转置
# n 是特征的数量
m, n = np.shape(dataMatrix)
alpha = 0.001 # 初始化学习率
maxCycles = 500 # 初始化最大迭代次数
weights = np.ones((n, 1)) # 初始化权重
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) # 计算假设值
error = (labelMat - h) # 计算误差
weights = weights + alpha * dataMatrix.transpose() * error # 更新权重
return weights-
知识拓展
梯度下降算法与这里的梯度上升算法是一样的,只是迭代公式中的加法需要变成减法,即: 。梯度上升算法用来求函数的最大值,梯度下降算法用来求函数的最小值。
-
随机梯度上升法
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,该方法处理样本少的数据集尚可,如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度就太高了。
一种改进方法是:一次仅用一个样本点来更新回归系数,即随机梯度上升算法。与梯度上升法类似,随机梯度上升法也是通过迭代更新参数来寻找使目标函数取得最大值的参数值。然而,与梯度上升法不同的是,随机梯度上升法在每次迭代中仅使用部分样本(即随机抽样的样本)来计算梯度,从而降低计算成本。
随机梯度上升法的基本思想是通过迭代更新参数来逼近最大化目标函数。在每次迭代中,随机梯度上升法的更新规则如下:
其中: 是需要优化的参数向量;
是目标函数针对随机抽样的第
个样本计算得到的函数值;
是目标函数
对参数
的梯度。
随机梯度上升法的优点是在大规模数据集下具有较低的计算复杂度,并且能够在迭代过程中快速收敛。
随机梯度上升法的python代码:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m, n = np.shape(dataMatrix)
weights = np.ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.0001 # 动态调整学习率alpha,随着迭代次数增加而减小
# 生成一个位于[0, len(dataIndex))范围内的随机浮点数,然后通过int()将其转换为整数,从而得到一个在指定范围内的随机索引randIndex
randIndex = int(np.random.uniform(0, len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h # 计算真实类别与预测类别的差值
weights = weights + alpha * error * dataMatrix[randIndex]
del (dataIndex[randIndex])
return weights随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别:第一,后者的变量h和误差error都是向量,而前者则全是数值;第二,前者没有矩阵的转换过程,所有变量的数据类型都是NumPy数组。
2 实例:预测病马的死亡率
- 数据集:368个样本和28个特征
- 原始的数据集经过预处理后保存为:horseColicTest.txt和horseColic-Training.txt,若想对原始数据和预处理后的数据做比较,可在http://archive.ics.uci. edu/ml/datasets/Horse+Colic浏览。
- 优化算法:随机梯度上升法
python代码:
# 用于测试算法:计算测试集的样本数据对应的Sigmoid值
def classifyVector(inX, weights):
prob = sigmoid(sum(inX * weights))
if prob > 0.5:
return 1.0
else:
return 0.0
# 打开测试集和训练集,并对数据进行格式化处理的函数
def colicTest():
# 导入数据集
frTrain = open('horseColicTraining.txt')
frTest = open('horseColicTest.txt')
# 训练算法
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
# 计算权重
trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, 1000)
# 使用计算的权重系数测试算法
errorCount = 0
numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr), trainWeights)) != int(currLine[21]):
errorCount += 1
# 计算算法的预测错误率
errorRate = (float(errorCount) / numTestVec)
print("the error rate of this test is: %f" % errorRate)
return errorRate
# 调用函数colicTest()10次并求结果的平均值
def multiTest():
numTests = 10
errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum / float(numTests)))
multiTest()运行结果:
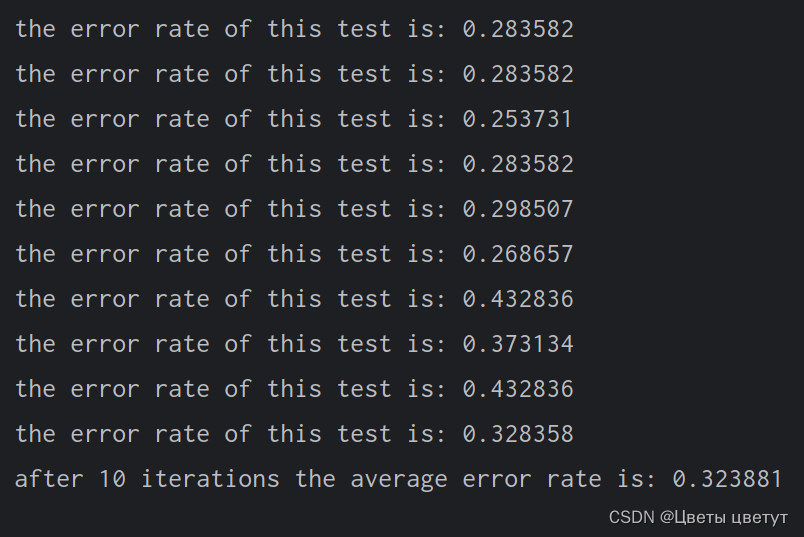
后续可通过调整colicTest()中的迭代次数和stocGradAscent1()中的步长,降低算法的平均错误率。















 4685
4685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









