







(一)认识Logistic回归(LR)分类器
首先,Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题,利用Logistic函数(或称为Sigmoid函数),自变量取值范围为(-INF, INF),自变量的取值范围为(0,1),函数形式为:
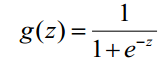
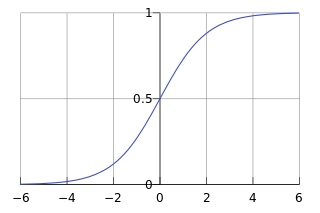
由于sigmoid函数的定义域是(-INF, +INF),而值域为(0, 1)。因此最基本的LR分类器适合于对两分类(类0,类1)目标进行分类。Sigmoid 函数是个很漂亮的“S”形,如下图所示:
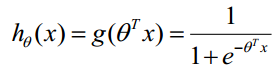
函数的值表示结果为1的概率,就是特征属于y=1的概率。因此对于输入x分类结果为类别1和类别0的概率分别为:
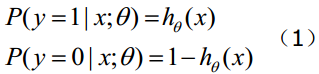
当我们要判别一个新来的特征属于哪个类时,按照下式求出一个z值:
(x1,x2,...,xn是某样本数据的各个特征,维度为n)
进而求出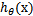
Logistic回归可以也可以用于多分类的,但是二分类的更为常用也更容易解释。所以实际中最常用的就是二分类的Logistic回归。LR分类器适用数据类型:数值型和标称型数据。其优点是计算代价不高,易于理解和实现;其缺点是容易欠拟合,分类精度可能不高。
(二)Logistic回归数学推导
1,梯度下降法求解Logistic回归
首先,理解下述数学推导过程需要较多的导数求解公式,可以参考“
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4070
4070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









